 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice EHR: Introducing Multimodal Audio Data for Health
Apr 02, 2024

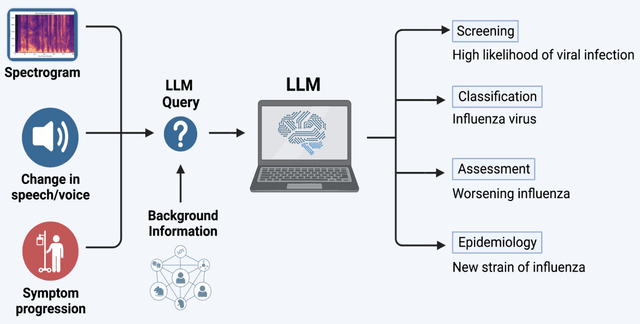
Large AI models trained on audio data may have the potential to rapidly classify patients, enhancing medical decision-making and potentially improving outcomes through early detection. Existing technologies depend on limited datasets using expensive recording equipment in high-income, English-speaking countries. This challenges deployment in resource-constrained, high-volume settings where audio data may have a profound impact. This report introduces a novel data type and a corresponding collection system that captures health data through guided questions using only a mobile/web application. This application ultimately results in an audio electronic health record (voice EHR) which may contain complex biomarkers of health from conventional voice/respiratory features, speech patterns, and language with semantic meaning - compensating for the typical limitations of unimodal clinical datasets. This report introduces a consortium of partners for global work, presents the application used for data collection, and showcases the potential of informative voice EHR to advance the scalability and diversity of audio AI.
Auto-FedRL: Federated Hyperparameter Optimization for Multi-institutional Medical Image Segmentation
Mar 12, 2022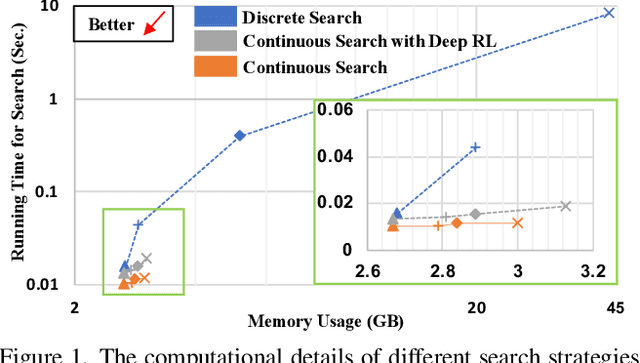

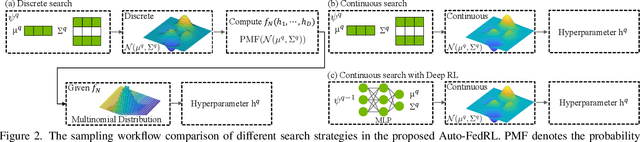

Federated learning (FL) is a distributed machine learning technique that enables collaborative model training while avoiding explicit data sharing. The inherent privacy-preserving property of FL algorithms makes them especially attractive to the medical field. However, in case of heterogeneous client data distributions, standard FL methods are unstable and require intensive hyperparameter tuning to achieve optimal performance. Conventional hyperparameter optimization algorithms are impractical in real-world FL applications as they involve numerous training trials, which are often not affordable with limited compute budgets. In this work, we propose an efficient reinforcement learning~(RL)-based federated hyperparameter optimization algorithm, termed Auto-FedRL, in which an online RL agent can dynamically adjust hyperparameters of each client based on the current training progress. Extensive experiments are conducted to investigate different search strategies and RL agents. The effectiveness of the proposed method is validated on a heterogeneous data split of the CIFAR-10 dataset as well as two real-world medical image segmentation datasets for COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
Auto-FedAvg: Learnable Federated Averaging for Multi-Institutional Medical Image Segmentation
Apr 20, 2021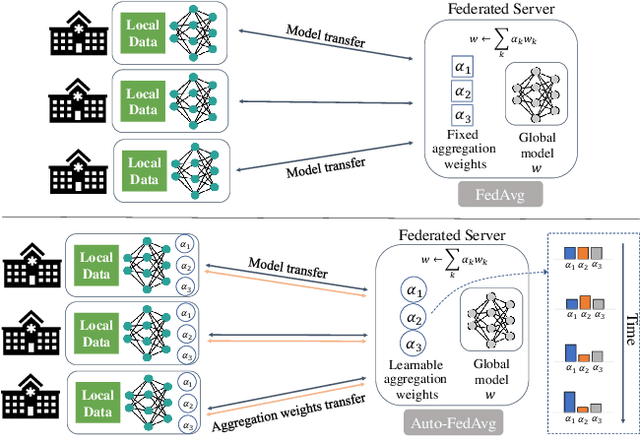
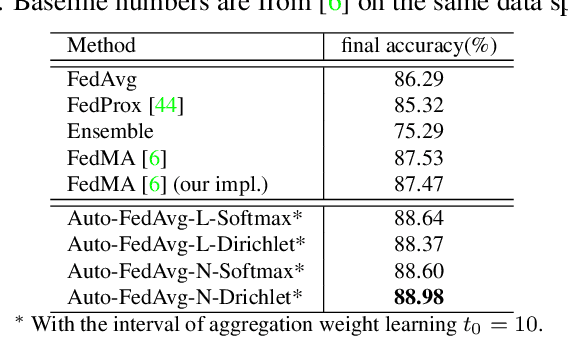
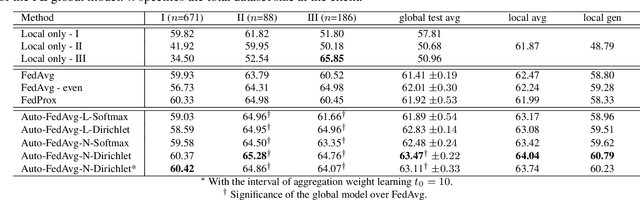
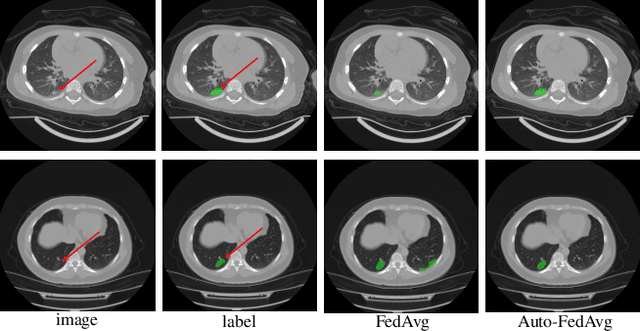
Federated learning (FL) enables collaborative model training while preserving each participant's privacy, which is particularly beneficial to the medical field. FedAvg is a standard algorithm that uses fixed weights, often originating from the dataset sizes at each client, to aggregate the distributed learned models on a server during the FL process. However, non-identical data distribution across clients, known as the non-i.i.d problem in FL, could make this assumption for setting fixed aggregation weights sub-optimal. In this work, we design a new data-driven approach, namely Auto-FedAvg, where aggregation weights are dynamically adjusted, depending on data distributions across data silos and the current training progress of the models. We disentangle the parameter set into two parts, local model parameters and global aggregation parameters, and update them iteratively with a communication-efficient algorithm. We first show the validity of our approach by outperforming state-of-the-art FL methods for image recognition on a heterogeneous data split of CIFAR-10. Furthermore, we demonstrate our algorithm's effectiveness on two multi-institutional medical image analysis tasks, i.e., COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
Multi-Domain Image Completion for Random Missing Input Data
Jul 10, 2020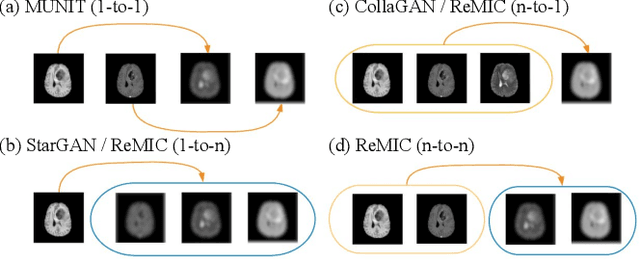
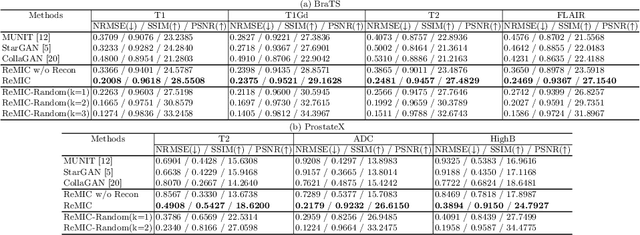

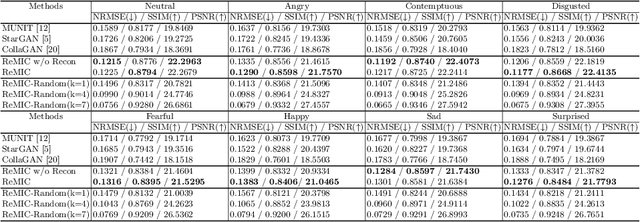
Multi-domain data are widely leveraged in vision applications taking advantage of complementary information from different modalities, e.g., brain tumor segmentation from multi-parametric magnetic resonance imaging (MRI). However, due to possible data corruption and different imaging protocols, the availability of images for each domain could vary amongst multiple data sources in practice, which makes it challenging to build a universal model with a varied set of input data. To tackle this problem, we propose a general approach to complete the random missing domain(s) data in real applications. Specifically, we develop a novel multi-domain image completion method that utilizes a generative adversarial network (GAN) with a representational disentanglement scheme to extract shared skeleton encoding and separate flesh encoding across multiple domains. We further illustrate that the learned representation in multi-domain image completion could be leveraged for high-level tasks, e.g., segmentation, by introducing a unified framework consisting of image completion and segmentation with a shared content encoder. The experiments demonstrate consistent performance improvement on three datasets for brain tumor segmentation, prostate segmentation, and facial expression image completion respectively.
Sensorless Freehand 3D Ultrasound Reconstruction via Deep Contextual Learning
Jun 13, 2020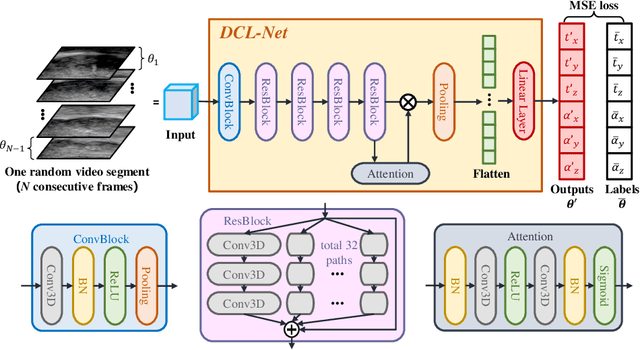
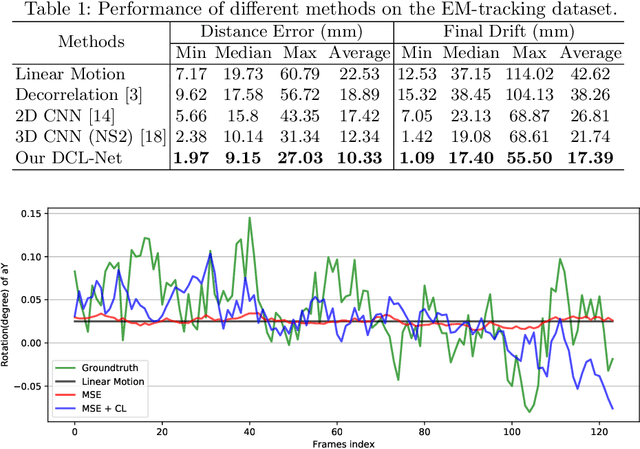

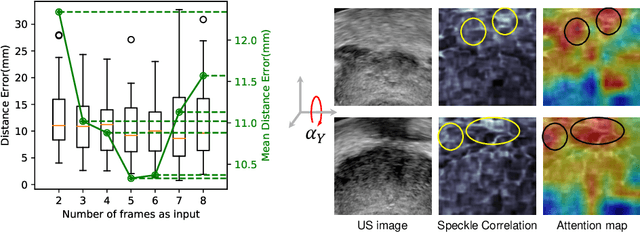
Transrectal ultrasound (US) is the most commonly used imaging modality to guide prostate biopsy and its 3D volume provides even richer context information. Current methods for 3D volume reconstruction from freehand US scans require external tracking devices to provide spatial position for every frame. In this paper, we propose a deep contextual learning network (DCL-Net), which can efficiently exploit the image feature relationship between US frames and reconstruct 3D US volumes without any tracking device. The proposed DCL-Net utilizes 3D convolutions over a US video segment for feature extraction. An embedded self-attention module makes the network focus on the speckle-rich areas for better spatial movement prediction. We also propose a novel case-wise correlation loss to stabilize the training process for improved accuracy. Highly promising results have been obtained by using the developed method. The experiments with ablation studies demonstrate superior performance of the proposed method by comparing against other state-of-the-art methods. Source code of this work is publicly available at https://github.com/DIAL-RPI/FreehandUSRecon.
A Collaborative Computer Aided Diagnosis (C-CAD) System with Eye-Tracking, Sparse Attentional Model, and Deep Learning
Apr 28, 2018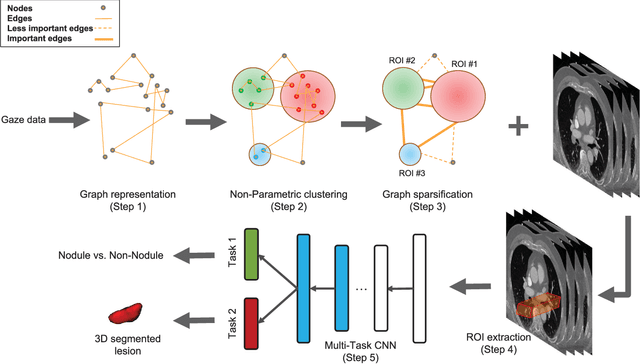
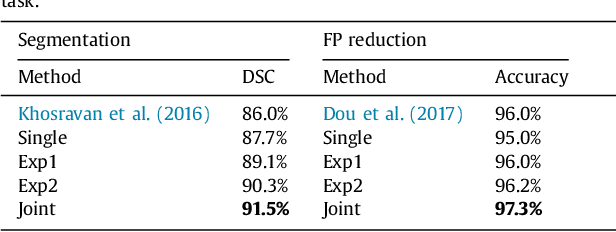
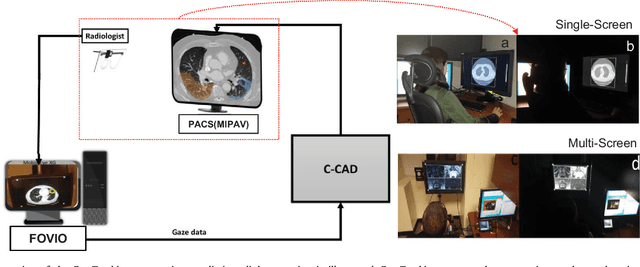
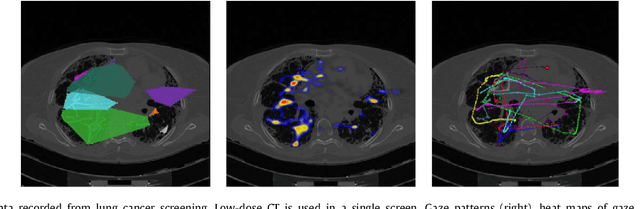
There are at least two categories of errors in radiology screening that can lead to suboptimal diagnostic decisions and interventions:(i)human fallibility and (ii)complexity of visual search. Computer aided diagnostic (CAD) tools are developed to help radiologists to compensate for some of these errors. However, despite their significant improvements over conventional screening strategies, most CAD systems do not go beyond their use as second opinion tools due to producing a high number of false positives, which human interpreters need to correct. In parallel with efforts in computerized analysis of radiology scans, several researchers have examined behaviors of radiologists while screening medical images to better understand how and why they miss tumors, how they interact with the information in an image, and how they search for unknown pathology in the images. Eye-tracking tools have been instrumental in exploring answers to these fundamental questions. In this paper, we aim to develop a paradigm shift CAD system, called collaborative CAD (C-CAD), that unifies both of the above mentioned research lines: CAD and eye-tracking. We design an eye-tracking interface providing radiologists with a real radiology reading room experience. Then, we propose a novel algorithm that unifies eye-tracking data and a CAD system. Specifically, we present a new graph based clustering and sparsification algorithm to transform eye-tracking data (gaze) into a signal model to interpret gaze patterns quantitatively and qualitatively. The proposed C-CAD collaborates with radiologists via eye-tracking technology and helps them to improve diagnostic decisions. The C-CAD learns radiologists' search efficiency by processing their gaze patterns. To do this, the C-CAD uses a deep learning algorithm in a newly designed multi-task learning platform to segment and diagnose cancers simultaneously.