 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Discovery
Causal discovery is the process of inferring causal relationships between variables from observational data.
Papers and Code
Causal Structure Learning for Dynamical Systems with Theoretical Score Analysis
Dec 16, 2025Real world systems evolve in continuous-time according to their underlying causal relationships, yet their dynamics are often unknown. Existing approaches to learning such dynamics typically either discretize time -- leading to poor performance on irregularly sampled data -- or ignore the underlying causality. We propose CaDyT, a novel method for causal discovery on dynamical systems addressing both these challenges. In contrast to state-of-the-art causal discovery methods that model the problem using discrete-time Dynamic Bayesian networks, our formulation is grounded in Difference-based causal models, which allow milder assumptions for modeling the continuous nature of the system. CaDyT leverages exact Gaussian Process inference for modeling the continuous-time dynamics which is more aligned with the underlying dynamical process. We propose a practical instantiation that identifies the causal structure via a greedy search guided by the Algorithmic Markov Condition and Minimum Description Length principle. Our experiments show that CaDyT outperforms state-of-the-art methods on both regularly and irregularly-sampled data, discovering causal networks closer to the true underlying dynamics.
Rethinking Causal Discovery Through the Lens of Exchangeability
Dec 10, 2025Causal discovery methods have traditionally been developed under two distinct regimes: independent and identically distributed (i.i.d.) and timeseries data, each governed by separate modelling assumptions. In this paper, we argue that the i.i.d. setting can and should be reframed in terms of exchangeability, a strictly more general symmetry principle. We present the implications of this reframing, alongside two core arguments: (1) a conceptual argument, based on extending the dependency of experimental causal inference on exchangeability to causal discovery; and (2) an empirical argument, showing that many existing i.i.d. causal-discovery methods are predicated on exchangeability assumptions, and that the sole extensive widely-used real-world "i.i.d." benchmark (the Tübingen dataset) consists mainly of exchangeable (and not i.i.d.) examples. Building on this insight, we introduce a novel synthetic dataset that enforces only the exchangeability assumption, without imposing the stronger i.i.d. assumption. We show that our exchangeable synthetic dataset mirrors the statistical structure of the real-world "i.i.d." dataset more closely than all other i.i.d. synthetic datasets. Furthermore, we demonstrate the predictive capability of this dataset by proposing a neural-network-based causal-discovery algorithm trained exclusively on our synthetic dataset, and which performs similarly to other state-of-the-art i.i.d. methods on the real-world benchmark.
Triangulation as an Acceptance Rule for Multilingual Mechanistic Interpretability
Dec 31, 2025Multilingual language models achieve strong aggregate performance yet often behave unpredictably across languages, scripts, and cultures. We argue that mechanistic explanations for such models should satisfy a \emph{causal} standard: claims must survive causal interventions and must \emph{cross-reference} across environments that perturb surface form while preserving meaning. We formalize \emph{reference families} as predicate-preserving variants and introduce \emph{triangulation}, an acceptance rule requiring necessity (ablating the circuit degrades the target behavior), sufficiency (patching activations transfers the behavior), and invariance (both effects remain directionally stable and of sufficient magnitude across the reference family). To supply candidate subgraphs, we adopt automatic circuit discovery and \emph{accept or reject} those candidates by triangulation. We ground triangulation in causal abstraction by casting it as an approximate transformation score over a distribution of interchange interventions, connect it to the pragmatic interpretability agenda, and present a comparative experimental protocol across multiple model families, language pairs, and tasks. Triangulation provides a falsifiable standard for mechanistic claims that filters spurious circuits passing single-environment tests but failing cross-lingual invariance.
BUILD with Precision: Bottom-Up Inference of Linear DAGs
Dec 18, 2025Learning the structure of directed acyclic graphs (DAGs) from observational data is a central problem in causal discovery, statistical signal processing, and machine learning. Under a linear Gaussian structural equation model (SEM) with equal noise variances, the problem is identifiable and we show that the ensemble precision matrix of the observations exhibits a distinctive structure that facilitates DAG recovery. Exploiting this property, we propose BUILD (Bottom-Up Inference of Linear DAGs), a deterministic stepwise algorithm that identifies leaf nodes and their parents, then prunes the leaves by removing incident edges to proceed to the next step, exactly reconstructing the DAG from the true precision matrix. In practice, precision matrices must be estimated from finite data, and ill-conditioning may lead to error accumulation across BUILD steps. As a mitigation strategy, we periodically re-estimate the precision matrix (with less variables as leaves are pruned), trading off runtime for enhanced robustness. Reproducible results on challenging synthetic benchmarks demonstrate that BUILD compares favorably to state-of-the-art DAG learning algorithms, while offering an explicit handle on complexity.
On the Identifiability of Regime-Switching Models with Multi-Lag Dependencies
Jan 06, 2026Identifiability is central to the interpretability of deep latent variable models, ensuring parameterisations are uniquely determined by the data-generating distribution. However, it remains underexplored for deep regime-switching time series. We develop a general theoretical framework for multi-lag Regime-Switching Models (RSMs), encompassing Markov Switching Models (MSMs) and Switching Dynamical Systems (SDSs). For MSMs, we formulate the model as a temporally structured finite mixture and prove identifiability of both the number of regimes and the multi-lag transitions in a nonlinear-Gaussian setting. For SDSs, we establish identifiability of the latent variables up to permutation and scaling via temporal structure, which in turn yields conditions for identifiability of regime-dependent latent causal graphs (up to regime/node permutations). Our results hold in a fully unsupervised setting through architectural and noise assumptions that are directly enforceable via neural network design. We complement the theory with a flexible variational estimator that satisfies the assumptions and validate the results on synthetic benchmarks. Across real-world datasets from neuroscience, finance, and climate, identifiability leads to more trustworthy interpretability analysis, which is crucial for scientific discovery.
On the Hardness of Conditional Independence Testing In Practice
Dec 16, 2025Tests of conditional independence (CI) underpin a number of important problems in machine learning and statistics, from causal discovery to evaluation of predictor fairness and out-of-distribution robustness. Shah and Peters (2020) showed that, contrary to the unconditional case, no universally finite-sample valid test can ever achieve nontrivial power. While informative, this result (based on "hiding" dependence) does not seem to explain the frequent practical failures observed with popular CI tests. We investigate the Kernel-based Conditional Independence (KCI) test - of which we show the Generalized Covariance Measure underlying many recent tests is nearly a special case - and identify the major factors underlying its practical behavior. We highlight the key role of errors in the conditional mean embedding estimate for the Type-I error, while pointing out the importance of selecting an appropriate conditioning kernel (not recognized in previous work) as being necessary for good test power but also tending to inflate Type-I error.
Towards Unsupervised Causal Representation Learning via Latent Additive Noise Model Causal Autoencoders
Dec 15, 2025Unsupervised representation learning seeks to recover latent generative factors, yet standard methods relying on statistical independence often fail to capture causal dependencies. A central challenge is identifiability: as established in disentangled representation learning and nonlinear ICA literature, disentangling causal variables from observational data is impossible without supervision, auxiliary signals, or strong inductive biases. In this work, we propose the Latent Additive Noise Model Causal Autoencoder (LANCA) to operationalize the Additive Noise Model (ANM) as a strong inductive bias for unsupervised discovery. Theoretically, we prove that while the ANM constraint does not guarantee unique identifiability in the general mixing case, it resolves component-wise indeterminacy by restricting the admissible transformations from arbitrary diffeomorphisms to the affine class. Methodologically, arguing that the stochastic encoding inherent to VAEs obscures the structural residuals required for latent causal discovery, LANCA employs a deterministic Wasserstein Auto-Encoder (WAE) coupled with a differentiable ANM Layer. This architecture transforms residual independence from a passive assumption into an explicit optimization objective. Empirically, LANCA outperforms state-of-the-art baselines on synthetic physics benchmarks (Pendulum, Flow), and on photorealistic environments (CANDLE), where it demonstrates superior robustness to spurious correlations arising from complex background scenes.
Causal inference and model explainability tools for retail
Dec 14, 2025Most major retailers today have multiple divisions focused on various aspects, such as marketing, supply chain, online customer experience, store customer experience, employee productivity, and vendor fulfillment. They also regularly collect data corresponding to all these aspects as dashboards and weekly/monthly/quarterly reports. Although several machine learning and statistical techniques have been in place to analyze and predict key metrics, such models typically lack interpretability. Moreover, such techniques also do not allow the validation or discovery of causal links. In this paper, we aim to provide a recipe for applying model interpretability and causal inference for deriving sales insights. In this paper, we review the existing literature on causal inference and interpretability in the context of problems in e-commerce and retail, and apply them to a real-world dataset. We find that an inherently explainable model has a lower variance of SHAP values, and show that including multiple confounders through a double machine learning approach allows us to get the correct sign of causal effect.
LxCIM: a new rank-based binary classifier performance metric invariant to local exchange of classes
Dec 10, 2025

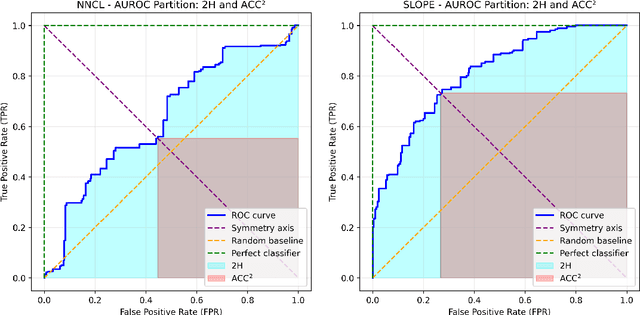

Binary classification is one of the oldest, most prevalent, and studied problems in machine learning. However, the metrics used to evaluate model performance have received comparatively little attention. The area under the receiver operating characteristic curve (AUROC) has long been a standard choice for model comparison. Despite its advantages, AUROC is not always ideal, particularly for problems that are invariant to local exchange of classes (LxC), a new form of metric invariance introduced in this work. To address this limitation, we propose LxCIM (LxC-invariant metric), which is not only rank-based and invariant under local exchange of classes, but also intuitive, logically consistent, and always computable, while enabling more detailed analysis through the cumulative accuracy-decision rate curve. Moreover, LxCIM exhibits clear theoretical connections to AUROC, accuracy, and the area under the accuracy-decision rate curve (AUDRC). These relationships allow for multiple complementary interpretations: as a symmetric form of AUROC, a rank-based analogue of accuracy, or a more representative and more interpretable variant of AUDRC. Finally, we demonstrate the direct applicability of LxCIM to the bivariate causal discovery problem (which exhibits invariance to local exchange of classes) and show how it addresses the acknowledged limitations of existing metrics used in this field. All code and implementation details are publicly available at github.com/tiagobrogueira/Causal-Discovery-In-Exchangeable-Data.
Causal Discovery on Higher-Order Interactions
Nov 18, 2025Causal discovery combines data with knowledge provided by experts to learn the DAG representing the causal relationships between a given set of variables. When data are scarce, bagging is used to measure our confidence in an average DAG obtained by aggregating bootstrapped DAGs. However, the aggregation step has received little attention from the specialized literature: the average DAG is constructed using only the confidence in the individual edges of the bootstrapped DAGs, thus disregarding complex higher-order edge structures. In this paper, we introduce a novel theoretical framework based on higher-order structures and describe a new DAG aggregation algorithm. We perform a simulation study, discussing the advantages and limitations of the proposed approach. Our proposal is both computationally efficient and effective, outperforming state-of-the-art solutions, especially in low sample size regimes and under high dimensionality settings.