 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgenhanes
Papers and Code
GLEN-Bench: A Graph-Language based Benchmark for Nutritional Health
Jan 26, 2026Nutritional interventions are important for managing chronic health conditions, but current computational methods provide limited support for personalized dietary guidance. We identify three key gaps: (1) dietary pattern studies often ignore real-world constraints such as socioeconomic status, comorbidities, and limited food access; (2) recommendation systems rarely explain why a particular food helps a given patient; and (3) no unified benchmark evaluates methods across the connected tasks needed for nutritional interventions. We introduce GLEN-Bench, the first comprehensive graph-language based benchmark for nutritional health assessment. We combine NHANES health records, FNDDS food composition data, and USDA food-access metrics to build a knowledge graph that links demographics, health conditions, dietary behaviors, poverty-related constraints, and nutrient needs. We test the benchmark using opioid use disorder, where models must detect subtle nutritional differences across disease stages. GLEN-Bench includes three linked tasks: risk detection identifies at-risk individuals from dietary and socioeconomic patterns; recommendation suggests personalized foods that meet clinical needs within resource constraints; and question answering provides graph-grounded, natural-language explanations to facilitate comprehension. We evaluate these graph-language approaches, including graph neural networks, large language models, and hybrid architectures, to establish solid baselines and identify practical design choices. Our analysis identifies clear dietary patterns linked to health risks, providing insights that can guide practical interventions.
A Micro-Macro Machine Learning Framework for Predicting Childhood Obesity Risk Using NHANES and Environmental Determinants
Dec 28, 2025Childhood obesity remains a major public health challenge in the United States, strongly influenced by a combination of individual-level, household-level, and environmental-level risk factors. Traditional epidemiological studies typically analyze these levels independently, limiting insights into how structural environmental conditions interact with individual-level characteristics to influence health outcomes. In this study, we introduce a micro-macro machine learning framework that integrates (1) individual-level anthropometric and socioeconomic data from NHANES and (2) macro-level structural environment features, including food access, air quality, and socioeconomic vulnerability extracted from USDA and EPA datasets. Four machine learning models Logistic Regression, Random Forest, XGBoost, and LightGBM were trained to predict obesity using NHANES microdata. XGBoost achieved the strongest performance. A composite environmental vulnerability index (EnvScore) was constructed using normalized indicators from USDA and EPA at the state level. Multi-level comparison revealed strong geographic similarity between states with high environmental burden and the nationally predicted micro-level obesity risk distribution. This demonstrates the feasibility of integrating multi-scale datasets to identify environment-driven disparities in obesity risk. This work contributes a scalable, data-driven, multi-level modeling pipeline suitable for public health informatics, demonstrating strong potential for expansion into causal modeling, intervention planning, and real-time analytics.
MotionTeller: Multi-modal Integration of Wearable Time-Series with LLMs for Health and Behavioral Understanding
Dec 25, 2025As wearable sensing becomes increasingly pervasive, a key challenge remains: how can we generate natural language summaries from raw physiological signals such as actigraphy - minute-level movement data collected via accelerometers? In this work, we introduce MotionTeller, a generative framework that natively integrates minute-level wearable activity data with large language models (LLMs). MotionTeller combines a pretrained actigraphy encoder with a lightweight projection module that maps behavioral embeddings into the token space of a frozen decoder-only LLM, enabling free-text, autoregressive generation of daily behavioral summaries. We construct a novel dataset of 54383 (actigraphy, text) pairs derived from real-world NHANES recordings, and train the model using cross-entropy loss with supervision only on the language tokens. MotionTeller achieves high semantic fidelity (BERTScore-F1 = 0.924) and lexical accuracy (ROUGE-1 = 0.722), outperforming prompt-based baselines by 7 percent in ROUGE-1. The average training loss converges to 0.38 by epoch 15, indicating stable optimization. Qualitative analysis confirms that MotionTeller captures circadian structure and behavioral transitions, while PCA plots reveal enhanced cluster alignment in embedding space post-training. Together, these results position MotionTeller as a scalable, interpretable system for transforming wearable sensor data into fluent, human-centered descriptions, introducing new pathways for behavioral monitoring, clinical review, and personalized health interventions.
Neural Network-based Partial-Linear Single-Index Models for Environmental Mixtures Analysis
Dec 12, 2025Evaluating the health effects of complex environmental mixtures remains a central challenge in environmental health research. Existing approaches vary in their flexibility, interpretability, scalability, and support for diverse outcome types, often limiting their utility in real-world applications. To address these limitations, we propose a neural network-based partial-linear single-index (NeuralPLSI) modeling framework that bridges semiparametric regression modeling interpretability with the expressive power of deep learning. The NeuralPLSI model constructs an interpretable exposure index via a learnable projection and models its relationship with the outcome through a flexible neural network. The framework accommodates continuous, binary, and time-to-event outcomes, and supports inference through a bootstrap-based procedure that yields confidence intervals for key model parameters. We evaluated NeuralPLSI through simulation studies under a range of scenarios and applied it to data from the National Health and Nutrition Examination Survey (NHANES) to demonstrate its practical utility. Together, our contributions establish NeuralPLSI as a scalable, interpretable, and versatile modeling tool for mixture analysis. To promote adoption and reproducibility, we release a user-friendly open-source software package that implements the proposed methodology and supports downstream visualization and inference (\texttt{https://github.com/hyungrok-do/NeuralPLSI}).
Distributional Random Forests for Complex Survey Designs on Reproducing Kernel Hilbert Spaces
Dec 09, 2025We study estimation of the conditional law $P(Y|X=\mathbf{x})$ and continuous functionals $Ψ(P(Y|X=\mathbf{x}))$ when $Y$ takes values in a locally compact Polish space, $X \in \mathbb{R}^p$, and the observations arise from a complex survey design. We propose a survey-calibrated distributional random forest (SDRF) that incorporates complex-design features via a pseudo-population bootstrap, PSU-level honesty, and a Maximum Mean Discrepancy (MMD) split criterion computed from kernel mean embeddings of Hájek-type (design-weighted) node distributions. We provide a framework for analyzing forest-style estimators under survey designs; establish design consistency for the finite-population target and model consistency for the super-population target under explicit conditions on the design, kernel, resampling multipliers, and tree partitions. As far as we are aware, these are the first results on model-free estimation of conditional distributions under survey designs. Simulations under a stratified two-stage cluster design provide finite sample performance and demonstrate the statistical error price of ignoring the survey design. The broad applicability of SDRF is demonstrated using NHANES: We estimate the tolerance regions of the conditional joint distribution of two diabetes biomarkers, illustrating how distributional heterogeneity can support subgroup-specific risk profiling for diabetes mellitus in the U.S. population.
Rate doubly robust estimation for weighted average treatment effects
Sep 18, 2025The weighted average treatment effect (WATE) defines a versatile class of causal estimands for populations characterized by propensity score weights, including the average treatment effect (ATE), treatment effect on the treated (ATT), on controls (ATC), and for the overlap population (ATO). WATE has broad applicability in social and medical research, as many datasets from these fields align with its framework. However, the literature lacks a systematic investigation into the robustness and efficiency conditions for WATE estimation. Although doubly robust (DR) estimators are well-studied for ATE, their applicability to other WATEs remains uncertain. This paper investigates whether widely used WATEs admit DR or rate doubly robust (RDR) estimators and assesses the role of nuisance function accuracy, particularly with machine learning. Using semiparametric efficient influence function (EIF) theory and double/debiased machine learning (DML), we propose three RDR estimators under specific rate and regularity conditions and evaluate their performance via Monte Carlo simulations. Applications to NHANES data on smoking and blood lead levels, and SIPP data on 401(k) eligibility, demonstrate the methods' practical relevance in medical and social sciences.
LLMs for energy and macronutrients estimation using only text data from 24-hour dietary recalls: a parameter-efficient fine-tuning experiment using a 10-shot prompt
Sep 16, 2025BACKGROUND: Most artificial intelligence tools used to estimate nutritional content rely on image input. However, whether large language models (LLMs) can accurately predict nutritional values based solely on text descriptions of foods consumed remains unknown. If effective, this approach could enable simpler dietary monitoring without the need for photographs. METHODS: We used 24-hour dietary recalls from adolescents aged 12-19 years in the National Health and Nutrition Examination Survey (NHANES). An open-source quantized LLM was prompted using a 10-shot, chain-of-thought approach to estimate energy and five macronutrients based solely on text strings listing foods and their quantities. We then applied parameter-efficient fine-tuning (PEFT) to evaluate whether predictive accuracy improved. NHANES-calculated values served as the ground truth for energy, proteins, carbohydrates, total sugar, dietary fiber and total fat. RESULTS: In a pooled dataset of 11,281 adolescents (49.9% male, mean age 15.4 years), the vanilla LLM yielded poor predictions. The mean absolute error (MAE) was 652.08 for energy and the Lin's CCC <0.46 across endpoints. In contrast, the fine-tuned model performed substantially better, with energy MAEs ranging from 171.34 to 190.90 across subsets, and Lin's CCC exceeding 0.89 for all outcomes. CONCLUSIONS: When prompted using a chain-of-thought approach and fine-tuned with PEFT, open-source LLMs exposed solely to text input can accurately predict energy and macronutrient values from 24-hour dietary recalls. This approach holds promise for low-burden, text-based dietary monitoring tools.
Estimating Visceral Adiposity from Wrist-Worn Accelerometry
Jun 10, 2025Visceral adipose tissue (VAT) is a key marker of both metabolic health and habitual physical activity (PA). Excess VAT is highly correlated with type 2 diabetes and insulin resistance. The mechanistic basis for this pathophysiology relates to overloading the liver with fatty acids. VAT is also a highly labile fat depot, with increased turnover stimulated by catecholamines during exercise. VAT can be measured with sophisticated imaging technologies, but can also be inferred directly from PA. We tested this relationship using National Health and Nutrition Examination Survey (NHANES) data from 2011-2014, for individuals aged 20-60 years with 7 days of accelerometry data (n=2,456 men; 2,427 women) [1]. Two approaches were used for estimating VAT from activity. The first used engineered features based on movements during gait and sleep, and then ridge regression to map summary statistics of these features into a VAT estimate. The second approach used deep neural networks trained on 24 hours of continuous accelerometry. A foundation model first mapped each 10s frame into a high-dimensional feature vector. A transformer model then mapped each day's feature vector time series into a VAT estimate, which were averaged over multiple days. For both approaches, the most accurate estimates were obtained with the addition of covariate information about subject demographics and body measurements. The best performance was obtained by combining the two approaches, resulting in VAT estimates with correlations of r=0.86. These findings demonstrate a strong relationship between PA and VAT and, by extension, between PA and metabolic health risks.
Association between nutritional factors, inflammatory biomarkers and cancer types: an analysis of NHANES data using machine learning
Apr 18, 2025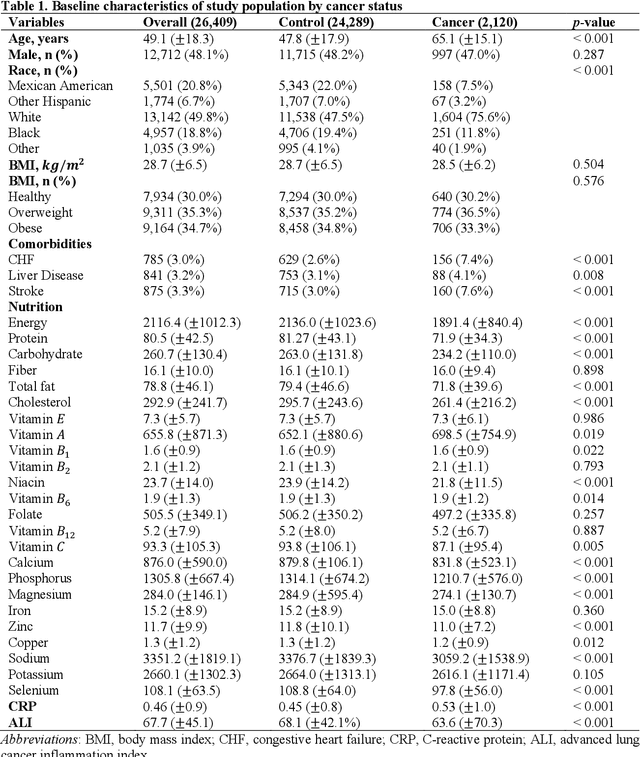
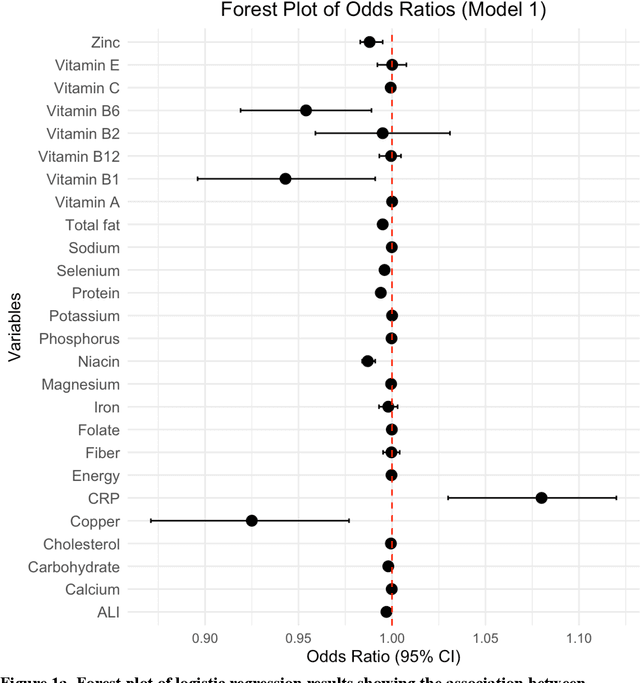
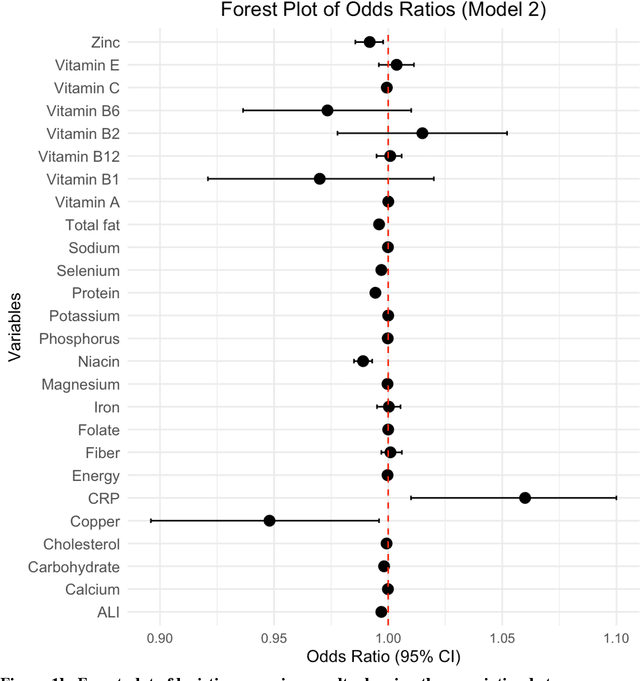

Background. Diet and inflammation are critical factors influencing cancer risk. However, the combined impact of nutritional status and inflammatory biomarkers on cancer status and type, using machine learning (ML), remains underexplored. Objectives. This study investigates the association between nutritional factors, inflammatory biomarkers, and cancer status, and whether these relationships differ across cancer types using National Health and Nutrition Examination Survey (NHANES) data. Methods. We analyzed 24 macro- and micronutrients, C-reactive protein (CRP), and the advanced lung cancer inflammation index (ALI) in 26,409 NHANES participants (2,120 with cancer). Multivariable logistic regression assessed associations with cancer prevalence. We also examined whether these features differed across the five most common cancer types. To evaluate predictive value, we applied three ML models - Logistic Regression, Random Forest, and XGBoost - on the full feature set. Results. The cohort's mean age was 49.1 years; 34.7% were obese. Comorbidities such as anemia and liver conditions, along with nutritional factors like protein and several vitamins, were key predictors of cancer status. Among the models, Random Forest performed best, achieving an accuracy of 0.72. Conclusions. Higher-quality nutritional intake and lower levels of inflammation may offer protective effects against cancer. These findings highlight the potential of combining nutritional and inflammatory markers with ML to inform cancer prevention strategies.
AI-driven Prediction of Insulin Resistance in Normal Populations: Comparing Models and Criteria
Mar 07, 2025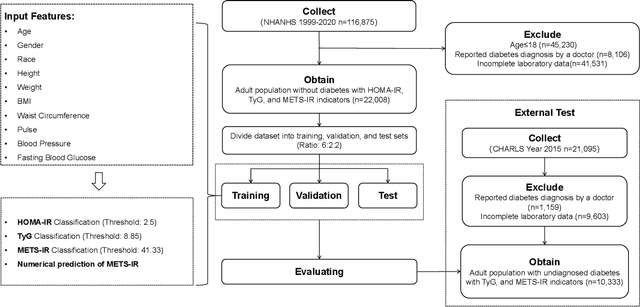
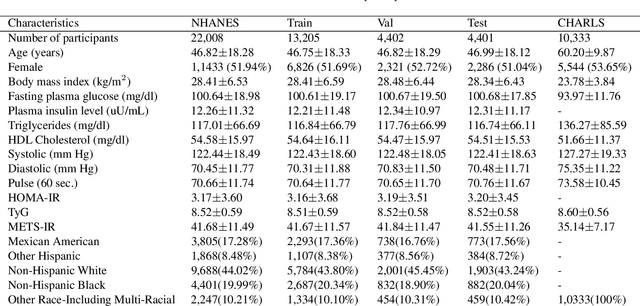
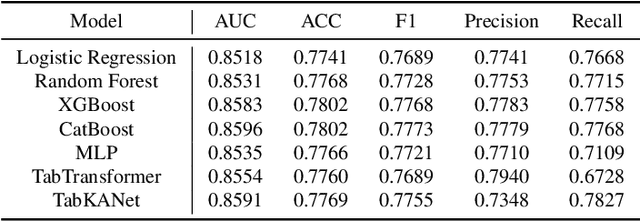
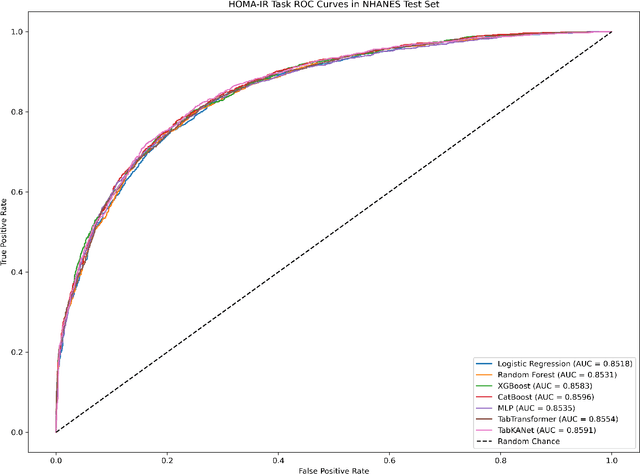
Insulin resistance (IR) is a key precursor to diabetes and a significant risk factor for cardiovascular disease. Traditional IR assessment methods require multiple blood tests. We developed a simple AI model using only fasting blood glucose to predict IR in non-diabetic populations. Data from the NHANES (1999-2020) and CHARLS (2015) studies were used for model training and validation. Input features included age, gender, height, weight, blood pressure, waist circumference, and fasting blood glucose. The CatBoost algorithm achieved AUC values of 0.8596 (HOMA-IR) and 0.7777 (TyG index) in NHANES, with an external AUC of 0.7442 for TyG. For METS-IR prediction, the model achieved AUC values of 0.9731 (internal) and 0.9591 (external), with RMSE values of 3.2643 (internal) and 3.057 (external). SHAP analysis highlighted waist circumference as a key predictor of IR. This AI model offers a minimally invasive and effective tool for IR prediction, supporting early diabetes and cardiovascular disease prevention.