 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiktok Dataset
Papers and Code
AI-Integrated Decision Support System for Real-Time Market Growth Forecasting and Multi-Source Content Diffusion Analytics
Nov 13, 2025The rapid proliferation of AI-generated content (AIGC) has reshaped the dynamics of digital marketing and online consumer behavior. However, predicting the diffusion trajectory and market impact of such content remains challenging due to data heterogeneity, non linear propagation mechanisms, and evolving consumer interactions. This study proposes an AI driven Decision Support System (DSS) that integrates multi source data including social media streams, marketing expenditure records, consumer engagement logs, and sentiment dynamics using a hybrid Graph Neural Network (GNN) and Temporal Transformer framework. The model jointly learns the content diffusion structure and temporal influence evolution through a dual channel architecture, while causal inference modules disentangle the effects of marketing stimuli on return on investment (ROI) and market visibility. Experiments on large scale real-world datasets collected from multiple online platforms such as Twitter, TikTok, and YouTube advertising show that our system outperforms existing baselines in all six metrics. The proposed DSS enhances marketing decisions by providing interpretable real-time insights into AIGC driven content dissemination and market growth patterns.
CAMP-VQA: Caption-Embedded Multimodal Perception for No-Reference Quality Assessment of Compressed Video
Nov 10, 2025The prevalence of user-generated content (UGC) on platforms such as YouTube and TikTok has rendered no-reference (NR) perceptual video quality assessment (VQA) vital for optimizing video delivery. Nonetheless, the characteristics of non-professional acquisition and the subsequent transcoding of UGC video on sharing platforms present significant challenges for NR-VQA. Although NR-VQA models attempt to infer mean opinion scores (MOS), their modeling of subjective scores for compressed content remains limited due to the absence of fine-grained perceptual annotations of artifact types. To address these challenges, we propose CAMP-VQA, a novel NR-VQA framework that exploits the semantic understanding capabilities of large vision-language models. Our approach introduces a quality-aware prompting mechanism that integrates video metadata (e.g., resolution, frame rate, bitrate) with key fragments extracted from inter-frame variations to guide the BLIP-2 pretraining approach in generating fine-grained quality captions. A unified architecture has been designed to model perceptual quality across three dimensions: semantic alignment, temporal characteristics, and spatial characteristics. These multimodal features are extracted and fused, then regressed to video quality scores. Extensive experiments on a wide variety of UGC datasets demonstrate that our model consistently outperforms existing NR-VQA methods, achieving improved accuracy without the need for costly manual fine-grained annotations. Our method achieves the best performance in terms of average rank and linear correlation (SRCC: 0.928, PLCC: 0.938) compared to state-of-the-art methods. The source code and trained models, along with a user-friendly demo, are available at: https://github.com/xinyiW915/CAMP-VQA.
Large Language Models for Toxic Language Detection in Low-Resource Balkan Languages
Jun 11, 2025Online toxic language causes real harm, especially in regions with limited moderation tools. In this study, we evaluate how large language models handle toxic comments in Serbian, Croatian, and Bosnian, languages with limited labeled data. We built and manually labeled a dataset of 4,500 YouTube and TikTok comments drawn from videos across diverse categories, including music, politics, sports, modeling, influencer content, discussions of sexism, and general topics. Four models (GPT-3.5 Turbo, GPT-4.1, Gemini 1.5 Pro, and Claude 3 Opus) were tested in two modes: zero-shot and context-augmented. We measured precision, recall, F1 score, accuracy and false positive rates. Including a short context snippet raised recall by about 0.12 on average and improved F1 score by up to 0.10, though it sometimes increased false positives. The best balance came from Gemini in context-augmented mode, reaching an F1 score of 0.82 and accuracy of 0.82, while zero-shot GPT-4.1 led on precision and had the lowest false alarms. We show how adding minimal context can improve toxic language detection in low-resource settings and suggest practical strategies such as improved prompt design and threshold calibration. These results show that prompt design alone can yield meaningful gains in toxicity detection for underserved Balkan language communities.
RealisDance-DiT: Simple yet Strong Baseline towards Controllable Character Animation in the Wild
Apr 21, 2025
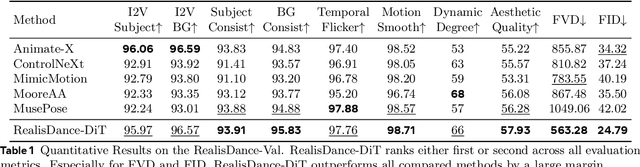

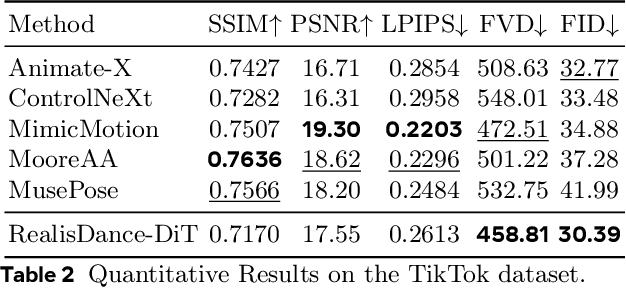
Controllable character animation remains a challenging problem, particularly in handling rare poses, stylized characters, character-object interactions, complex illumination, and dynamic scenes. To tackle these issues, prior work has largely focused on injecting pose and appearance guidance via elaborate bypass networks, but often struggles to generalize to open-world scenarios. In this paper, we propose a new perspective that, as long as the foundation model is powerful enough, straightforward model modifications with flexible fine-tuning strategies can largely address the above challenges, taking a step towards controllable character animation in the wild. Specifically, we introduce RealisDance-DiT, built upon the Wan-2.1 video foundation model. Our sufficient analysis reveals that the widely adopted Reference Net design is suboptimal for large-scale DiT models. Instead, we demonstrate that minimal modifications to the foundation model architecture yield a surprisingly strong baseline. We further propose the low-noise warmup and "large batches and small iterations" strategies to accelerate model convergence during fine-tuning while maximally preserving the priors of the foundation model. In addition, we introduce a new test dataset that captures diverse real-world challenges, complementing existing benchmarks such as TikTok dataset and UBC fashion video dataset, to comprehensively evaluate the proposed method. Extensive experiments show that RealisDance-DiT outperforms existing methods by a large margin.
TT-DF: A Large-Scale Diffusion-Based Dataset and Benchmark for Human Body Forgery Detection
May 13, 2025The emergence and popularity of facial deepfake methods spur the vigorous development of deepfake datasets and facial forgery detection, which to some extent alleviates the security concerns about facial-related artificial intelligence technologies. However, when it comes to human body forgery, there has been a persistent lack of datasets and detection methods, due to the later inception and complexity of human body generation methods. To mitigate this issue, we introduce TikTok-DeepFake (TT-DF), a novel large-scale diffusion-based dataset containing 6,120 forged videos with 1,378,857 synthetic frames, specifically tailored for body forgery detection. TT-DF offers a wide variety of forgery methods, involving multiple advanced human image animation models utilized for manipulation, two generative configurations based on the disentanglement of identity and pose information, as well as different compressed versions. The aim is to simulate any potential unseen forged data in the wild as comprehensively as possible, and we also furnish a benchmark on TT-DF. Additionally, we propose an adapted body forgery detection model, Temporal Optical Flow Network (TOF-Net), which exploits the spatiotemporal inconsistencies and optical flow distribution differences between natural data and forged data. Our experiments demonstrate that TOF-Net achieves favorable performance on TT-DF, outperforming current state-of-the-art extendable facial forgery detection models. For our TT-DF dataset, please refer to https://github.com/HashTAG00002/TT-DF.
Solving Copyright Infringement on Short Video Platforms: Novel Datasets and an Audio Restoration Deep Learning Pipeline
Apr 30, 2025



Short video platforms like YouTube Shorts and TikTok face significant copyright compliance challenges, as infringers frequently embed arbitrary background music (BGM) to obscure original soundtracks (OST) and evade content originality detection. To tackle this issue, we propose a novel pipeline that integrates Music Source Separation (MSS) and cross-modal video-music retrieval (CMVMR). Our approach effectively separates arbitrary BGM from the original OST, enabling the restoration of authentic video audio tracks. To support this work, we introduce two domain-specific datasets: OASD-20K for audio separation and OSVAR-160 for pipeline evaluation. OASD-20K contains 20,000 audio clips featuring mixed BGM and OST pairs, while OSVAR160 is a unique benchmark dataset comprising 1,121 video and mixed-audio pairs, specifically designed for short video restoration tasks. Experimental results demonstrate that our pipeline not only removes arbitrary BGM with high accuracy but also restores OSTs, ensuring content integrity. This approach provides an ethical and scalable solution to copyright challenges in user-generated content on short video platforms.
MetaHarm: Harmful YouTube Video Dataset Annotated by Domain Experts, GPT-4-Turbo, and Crowdworkers
Apr 22, 2025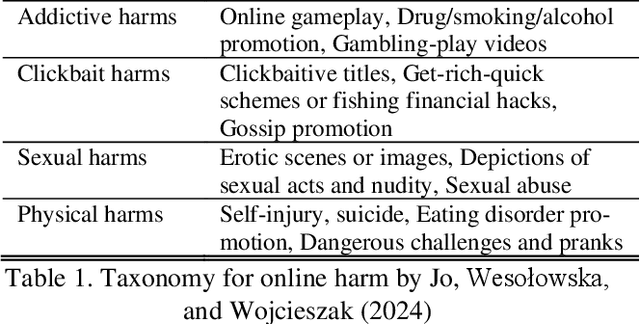



Short video platforms, such as YouTube, Instagram, or TikTok, are used by billions of users. These platforms expose users to harmful content, ranging from clickbait or physical harms to hate or misinformation. Yet, we lack a comprehensive understanding and measurement of online harm on short video platforms. Toward this end, we present two large-scale datasets of multi-modal and multi-categorical online harm: (1) 60,906 systematically selected potentially harmful YouTube videos and (2) 19,422 videos annotated by three labeling actors: trained domain experts, GPT-4-Turbo (using 14 image frames, 1 thumbnail, and text metadata), and crowdworkers (Amazon Mechanical Turk master workers). The annotated dataset includes both (a) binary classification (harmful vs. harmless) and (b) multi-label categorizations of six harm categories: Information, Hate and harassment, Addictive, Clickbait, Sexual, and Physical harms. Furthermore, the annotated dataset provides (1) ground truth data with videos annotated consistently across (a) all three actors and (b) the majority of the labeling actors, and (2) three data subsets labeled by individual actors. These datasets are expected to facilitate future work on online harm, aid in (multi-modal) classification efforts, and advance the identification and potential mitigation of harmful content on video platforms.
Enhancing Dance-to-Music Generation via Negative Conditioning Latent Diffusion Model
Mar 28, 2025Conditional diffusion models have gained increasing attention since their impressive results for cross-modal synthesis, where the strong alignment between conditioning input and generated output can be achieved by training a time-conditioned U-Net augmented with cross-attention mechanism. In this paper, we focus on the problem of generating music synchronized with rhythmic visual cues of the given dance video. Considering that bi-directional guidance is more beneficial for training a diffusion model, we propose to enhance the quality of generated music and its synchronization with dance videos by adopting both positive rhythmic information and negative ones (PN-Diffusion) as conditions, where a dual diffusion and reverse processes is devised. Specifically, to train a sequential multi-modal U-Net structure, PN-Diffusion consists of a noise prediction objective for positive conditioning and an additional noise prediction objective for negative conditioning. To accurately define and select both positive and negative conditioning, we ingeniously utilize temporal correlations in dance videos, capturing positive and negative rhythmic cues by playing them forward and backward, respectively. Through subjective and objective evaluations of input-output correspondence in terms of dance-music beat alignment and the quality of generated music, experimental results on the AIST++ and TikTok dance video datasets demonstrate that our model outperforms SOTA dance-to-music generation models.
SIV-Bench: A Video Benchmark for Social Interaction Understanding and Reasoning
Jun 05, 2025The rich and multifaceted nature of human social interaction, encompassing multimodal cues, unobservable relations and mental states, and dynamical behavior, presents a formidable challenge for artificial intelligence. To advance research in this area, we introduce SIV-Bench, a novel video benchmark for rigorously evaluating the capabilities of Multimodal Large Language Models (MLLMs) across Social Scene Understanding (SSU), Social State Reasoning (SSR), and Social Dynamics Prediction (SDP). SIV-Bench features 2,792 video clips and 8,792 meticulously generated question-answer pairs derived from a human-LLM collaborative pipeline. It is originally collected from TikTok and YouTube, covering a wide range of video genres, presentation styles, and linguistic and cultural backgrounds. It also includes a dedicated setup for analyzing the impact of different textual cues-original on-screen text, added dialogue, or no text. Our comprehensive experiments on leading MLLMs reveal that while models adeptly handle SSU, they significantly struggle with SSR and SDP, where Relation Inference (RI) is an acute bottleneck, as further examined in our analysis. Our study also confirms the critical role of transcribed dialogue in aiding comprehension of complex social interactions. By systematically identifying current MLLMs' strengths and limitations, SIV-Bench offers crucial insights to steer the development of more socially intelligent AI. The dataset and code are available at https://kfq20.github.io/sivbench/.
What Are You Doing? A Closer Look at Controllable Human Video Generation
Mar 06, 2025
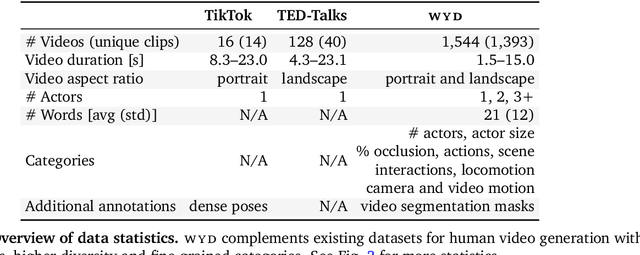
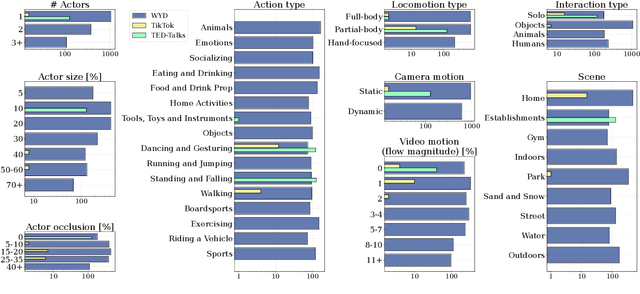
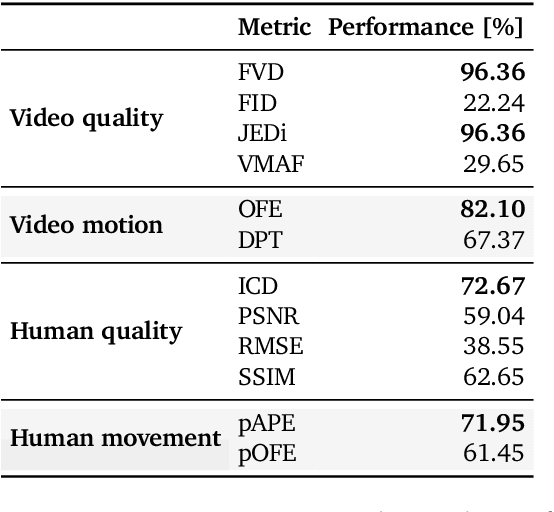
High-quality benchmarks are crucial for driving progress in machine learning research. However, despite the growing interest in video generation, there is no comprehensive dataset to evaluate human generation. Humans can perform a wide variety of actions and interactions, but existing datasets, like TikTok and TED-Talks, lack the diversity and complexity to fully capture the capabilities of video generation models. We close this gap by introducing `What Are You Doing?' (WYD): a new benchmark for fine-grained evaluation of controllable image-to-video generation of humans. WYD consists of 1{,}544 captioned videos that have been meticulously collected and annotated with 56 fine-grained categories. These allow us to systematically measure performance across 9 aspects of human generation, including actions, interactions and motion. We also propose and validate automatic metrics that leverage our annotations and better capture human evaluations. Equipped with our dataset and metrics, we perform in-depth analyses of seven state-of-the-art models in controllable image-to-video generation, showing how WYD provides novel insights about the capabilities of these models. We release our data and code to drive forward progress in human video generation modeling at https://github.com/google-deepmind/wyd-benchmark.