 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Simplification
Text simplification is the task of reducing the complexity of the vocabulary and sentence structure of text while retaining its original meaning, with the goal of improving readability and understanding. Simplification has a variety of important societal applications, for example, increasing accessibility for those with cognitive disabilities such as aphasia, dyslexia, and autism, or for non-native speakers and children with reading difficulties.
Papers and Code
Stable Velocity: A Variance Perspective on Flow Matching
Feb 05, 2026While flow matching is elegant, its reliance on single-sample conditional velocities leads to high-variance training targets that destabilize optimization and slow convergence. By explicitly characterizing this variance, we identify 1) a high-variance regime near the prior, where optimization is challenging, and 2) a low-variance regime near the data distribution, where conditional and marginal velocities nearly coincide. Leveraging this insight, we propose Stable Velocity, a unified framework that improves both training and sampling. For training, we introduce Stable Velocity Matching (StableVM), an unbiased variance-reduction objective, along with Variance-Aware Representation Alignment (VA-REPA), which adaptively strengthen auxiliary supervision in the low-variance regime. For inference, we show that dynamics in the low-variance regime admit closed-form simplifications, enabling Stable Velocity Sampling (StableVS), a finetuning-free acceleration. Extensive experiments on ImageNet $256\times256$ and large pretrained text-to-image and text-to-video models, including SD3.5, Flux, Qwen-Image, and Wan2.2, demonstrate consistent improvements in training efficiency and more than $2\times$ faster sampling within the low-variance regime without degrading sample quality. Our code is available at https://github.com/linYDTHU/StableVelocity.
Balancing Understanding and Generation in Discrete Diffusion Models
Feb 01, 2026In discrete generative modeling, two dominant paradigms demonstrate divergent capabilities: Masked Diffusion Language Models (MDLM) excel at semantic understanding and zero-shot generalization, whereas Uniform-noise Diffusion Language Models (UDLM) achieve strong few-step generation quality, yet neither attains balanced performance across both dimensions. To address this, we propose XDLM, which bridges the two paradigms via a stationary noise kernel. XDLM offers two key contributions: (1) it provides a principled theoretical unification of MDLM and UDLM, recovering each paradigm as a special case; and (2) an alleviated memory bottleneck enabled by an algebraic simplification of the posterior probabilities. Experiments demonstrate that XDLM advances the Pareto frontier between understanding capability and generation quality. Quantitatively, XDLM surpasses UDLM by 5.4 points on zero-shot text benchmarks and outperforms MDLM in few-step image generation (FID 54.1 vs. 80.8). When scaled to tune an 8B-parameter large language model, XDLM achieves 15.0 MBPP in just 32 steps, effectively doubling the baseline performance. Finally, analysis of training dynamics reveals XDLM's superior potential for long-term scaling. Code is available at https://github.com/MzeroMiko/XDLM
Controlling Reading Ease with Gaze-Guided Text Generation
Jan 25, 2026The way our eyes move while reading can tell us about the cognitive effort required to process the text. In the present study, we use this fact to generate texts with controllable reading ease. Our method employs a model that predicts human gaze patterns to steer language model outputs towards eliciting certain reading behaviors. We evaluate the approach in an eye-tracking experiment with native and non-native speakers of English. The results demonstrate that the method is effective at making the generated texts easier or harder to read, measured both in terms of reading times and perceived difficulty of the texts. A statistical analysis reveals that the changes in reading behavior are mostly due to features that affect lexical processing. Possible applications of our approach include text simplification for information accessibility and generation of personalized educational material for language learning.
What Lies Beneath: A Call for Distribution-based Visual Question & Answer Datasets
Jan 29, 2026Visual Question Answering (VQA) has become an important benchmark for assessing how large multimodal models (LMMs) interpret images. However, most VQA datasets focus on real-world images or simple diagrammatic analysis, with few focused on interpreting complex scientific charts. Indeed, many VQA datasets that analyze charts do not contain the underlying data behind those charts or assume a 1-to-1 correspondence between chart marks and underlying data. In reality, charts are transformations (i.e. analysis, simplification, modification) of data. This distinction introduces a reasoning challenge in VQA that the current datasets do not capture. In this paper, we argue for a dedicated VQA benchmark for scientific charts where there is no 1-to-1 correspondence between chart marks and underlying data. To do so, we survey existing VQA datasets and highlight limitations of the current field. We then generate synthetic histogram charts based on ground truth data, and ask both humans and a large reasoning model questions where precise answers depend on access to the underlying data. We release the open-source dataset, including figures, underlying data, distribution parameters used to generate the data, and bounding boxes for all figure marks and text for future research.
Profiling German Text Simplification with Interpretable Model-Fingerprints
Jan 19, 2026While Large Language Models (LLMs) produce highly nuanced text simplifications, developers currently lack tools for a holistic, efficient, and reproducible diagnosis of their behavior. This paper introduces the Simplification Profiler, a diagnostic toolkit that generates a multidimensional, interpretable fingerprint of simplified texts. Multiple aggregated simplifications of a model result in a model's fingerprint. This novel evaluation paradigm is particularly vital for languages, where the data scarcity problem is magnified when creating flexible models for diverse target groups rather than a single, fixed simplification style. We propose that measuring a model's unique behavioral signature is more relevant in this context as an alternative to correlating metrics with human preferences. We operationalize this with a practical meta-evaluation of our fingerprints' descriptive power, which bypasses the need for large, human-rated datasets. This test measures if a simple linear classifier can reliably identify various model configurations by their created simplifications, confirming that our metrics are sensitive to a model's specific characteristics. The Profiler can distinguish high-level behavioral variations between prompting strategies and fine-grained changes from prompt engineering, including few-shot examples. Our complete feature set achieves classification F1-scores up to 71.9 %, improving upon simple baselines by over 48 percentage points. The Simplification Profiler thus offers developers a granular, actionable analysis to build more effective and truly adaptive text simplification systems.
Evaluating Small Decoder-Only Language Models for Grammar Correction and Text Simplification
Jan 07, 2026Large language models have become extremely popular recently due to their ability to achieve strong performance on a variety of tasks, such as text generation and rewriting, but their size and computation cost make them difficult to access, deploy, and secure in many settings. This paper investigates whether small, decoder-only language models can provide an efficient alternative for the tasks of grammar correction and text simplification. The experiments in this paper focus on testing small language models out of the box, fine-tuned, and run sequentially on the JFLEG and ASSET datasets using established metrics. The results show that while SLMs may learn certain behaviors well, their performance remains below strong baselines and current LLMs. The results also show that SLMs struggle with retaining meaning and hallucinations. These findings suggest that despite their efficiency advantages, current SLMs are not yet competitive enough with modern LLMs for rewriting, and further advances in training are required for SLMs to close the performance gap between them and today's LLMs.
Simplify-This: A Comparative Analysis of Prompt-Based and Fine-Tuned LLMs
Jan 09, 2026Large language models (LLMs) enable strong text generation, and in general there is a practical tradeoff between fine-tuning and prompt engineering. We introduce Simplify-This, a comparative study evaluating both paradigms for text simplification with encoder-decoder LLMs across multiple benchmarks, using a range of evaluation metrics. Fine-tuned models consistently deliver stronger structural simplification, whereas prompting often attains higher semantic similarity scores yet tends to copy inputs. A human evaluation favors fine-tuned outputs overall. We release code, a cleaned derivative dataset used in our study, checkpoints of fine-tuned models, and prompt templates to facilitate reproducibility and future work.
UM_FHS at the CLEF 2025 SimpleText Track: Comparing No-Context and Fine-Tune Approaches for GPT-4.1 Models in Sentence and Document-Level Text Simplification
Dec 18, 2025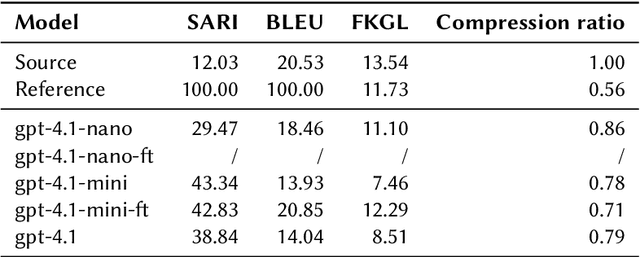
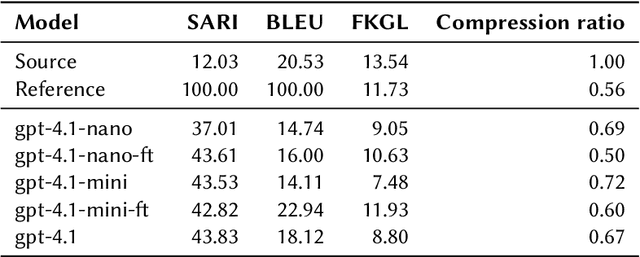
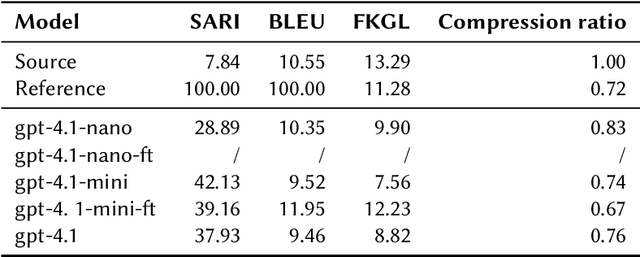
This work describes our submission to the CLEF 2025 SimpleText track Task 1, addressing both sentenceand document-level simplification of scientific texts. The methodology centered on using the gpt-4.1, gpt-4.1mini, and gpt-4.1-nano models from OpenAI. Two distinct approaches were compared: a no-context method relying on prompt engineering and a fine-tuned (FT) method across models. The gpt-4.1-mini model with no-context demonstrated robust performance at both levels of simplification, while the fine-tuned models showed mixed results, highlighting the complexities of simplifying text at different granularities, where gpt-4.1-nano-ft performance stands out at document-level simplification in one case.
PIAST: Rapid Prompting with In-context Augmentation for Scarce Training data
Dec 11, 2025LLMs are highly sensitive to prompt design, but handcrafting effective prompts is difficult and often requires intricate crafting of few-shot examples. We propose a fast automatic prompt construction algorithm that augments human instructions by generating a small set of few shot examples. Our method iteratively replaces/drops/keeps few-shot examples using Monte Carlo Shapley estimation of example utility. For faster execution, we use aggressive subsampling and a replay buffer for faster evaluations. Our method can be run using different compute time budgets. On a limited budget, we outperform existing automatic prompting methods on text simplification and GSM8K and obtain second best results on classification and summarization. With an extended, but still modest compute budget we set a new state of the art among automatic prompting methods on classification, simplification and GSM8K. Our results show that carefully constructed examples, rather than exhaustive instruction search, are the dominant lever for fast and data efficient prompt engineering. Our code is available at https://github.com/Batorskq/PIAST.
Readability Measures and Automatic Text Simplification: In the Search of a Construct
Nov 12, 2025



Readability is a key concept in the current era of abundant written information. To help making texts more readable and make information more accessible to everyone, a line of researched aims at making texts accessible for their target audience: automatic text simplification (ATS). Lately, there have been studies on the correlations between automatic evaluation metrics in ATS and human judgment. However, the correlations between those two aspects and commonly available readability measures (such as readability formulas or linguistic features) have not been the focus of as much attention. In this work, we investigate the place of readability measures in ATS by complementing the existing studies on evaluation metrics and human judgment, on English. We first discuss the relationship between ATS and research in readability, then we report a study on correlations between readability measures and human judgment, and between readability measures and ATS evaluation metrics. We identify that in general, readability measures do not correlate well with automatic metrics and human judgment. We argue that as the three different angles from which simplification can be assessed tend to exhibit rather low correlations with one another, there is a need for a clear definition of the construct in ATS.