 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmerging categories in scientific explanations
May 23, 2025Clear and effective explanations are essential for human understanding and knowledge dissemination. The scope of scientific research aiming to understand the essence of explanations has recently expanded from the social sciences to machine learning and artificial intelligence. Explanations for machine learning decisions must be impactful and human-like, and there is a lack of large-scale datasets focusing on human-like and human-generated explanations. This work aims to provide such a dataset by: extracting sentences that indicate explanations from scientific literature among various sources in the biotechnology and biophysics topic domains (e.g. PubMed's PMC Open Access subset); providing a multi-class notation derived inductively from the data; evaluating annotator consensus on the emerging categories. The sentences are organized in an openly-available dataset, with two different classifications (6-class and 3-class category annotation), and the 3-class notation achieves a 0.667 Krippendorf Alpha value.
Can summarization approximate simplification? A gold standard comparison
Jan 27, 2025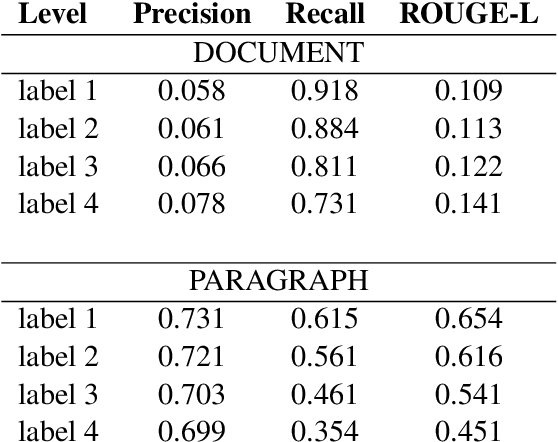
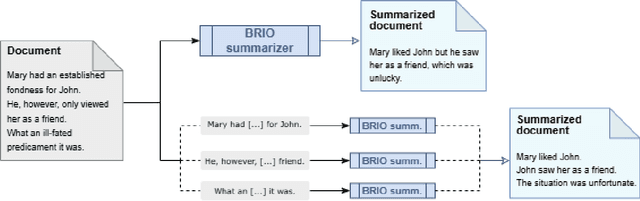
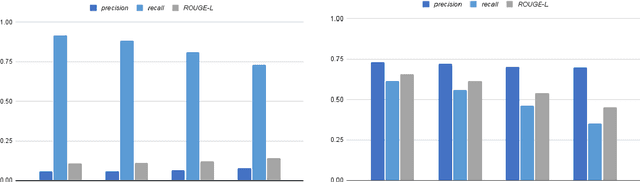
This study explores the overlap between text summarization and simplification outputs. While summarization evaluation methods are streamlined, simplification lacks cohesion, prompting the question: how closely can abstractive summarization resemble gold-standard simplification? We address this by applying two BART-based BRIO summarization methods to the Newsela corpus, comparing outputs with manually annotated simplifications and achieving a top ROUGE-L score of 0.654. This provides insight into where summarization and simplification outputs converge and differ.
Towards Unifying Evaluation of Counterfactual Explanations: Leveraging Large Language Models for Human-Centric Assessments
Oct 28, 2024



As machine learning models evolve, maintaining transparency demands more human-centric explainable AI techniques. Counterfactual explanations, with roots in human reasoning, identify the minimal input changes needed to obtain a given output and, hence, are crucial for supporting decision-making. Despite their importance, the evaluation of these explanations often lacks grounding in user studies and remains fragmented, with existing metrics not fully capturing human perspectives. To address this challenge, we developed a diverse set of 30 counterfactual scenarios and collected ratings across 8 evaluation metrics from 206 respondents. Subsequently, we fine-tuned different Large Language Models (LLMs) to predict average or individual human judgment across these metrics. Our methodology allowed LLMs to achieve an accuracy of up to 63% in zero-shot evaluations and 85% (over a 3-classes prediction) with fine-tuning across all metrics. The fine-tuned models predicting human ratings offer better comparability and scalability in evaluating different counterfactual explanation frameworks.