 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMidv
Papers and Code
IDNet: A Novel Dataset for Identity Document Analysis and Fraud Detection
Aug 03, 2024


Effective fraud detection and analysis of government-issued identity documents, such as passports, driver's licenses, and identity cards, are essential in thwarting identity theft and bolstering security on online platforms. The training of accurate fraud detection and analysis tools depends on the availability of extensive identity document datasets. However, current publicly available benchmark datasets for identity document analysis, including MIDV-500, MIDV-2020, and FMIDV, fall short in several respects: they offer a limited number of samples, cover insufficient varieties of fraud patterns, and seldom include alterations in critical personal identifying fields like portrait images, limiting their utility in training models capable of detecting realistic frauds while preserving privacy. In response to these shortcomings, our research introduces a new benchmark dataset, IDNet, designed to advance privacy-preserving fraud detection efforts. The IDNet dataset comprises 837,060 images of synthetically generated identity documents, totaling approximately 490 gigabytes, categorized into 20 types from $10$ U.S. states and 10 European countries. We evaluate the utility and present use cases of the dataset, illustrating how it can aid in training privacy-preserving fraud detection methods, facilitating the generation of camera and video capturing of identity documents, and testing schema unification and other identity document management functionalities.
Weakly Supervised Training for Hologram Verification in Identity Documents
Apr 26, 2024



We propose a method to remotely verify the authenticity of Optically Variable Devices (OVDs), often referred to as ``holograms'', in identity documents. Our method processes video clips captured with smartphones under common lighting conditions, and is evaluated on two public datasets: MIDV-HOLO and MIDV-2020. Thanks to a weakly-supervised training, we optimize a feature extraction and decision pipeline which achieves a new leading performance on MIDV-HOLO, while maintaining a high recall on documents from MIDV-2020 used as attack samples. It is also the first method, to date, to effectively address the photo replacement attack task, and can be trained on either genuine samples, attack samples, or both for increased performance. By enabling to verify OVD shapes and dynamics with very little supervision, this work opens the way towards the use of massive amounts of unlabeled data to build robust remote identity document verification systems on commodity smartphones. Code is available at https://github.com/EPITAResearchLab/pouliquen.24.icdar
IDTrust: Deep Identity Document Quality Detection with Bandpass Filtering
Mar 01, 2024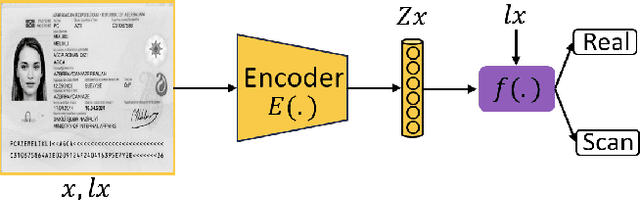
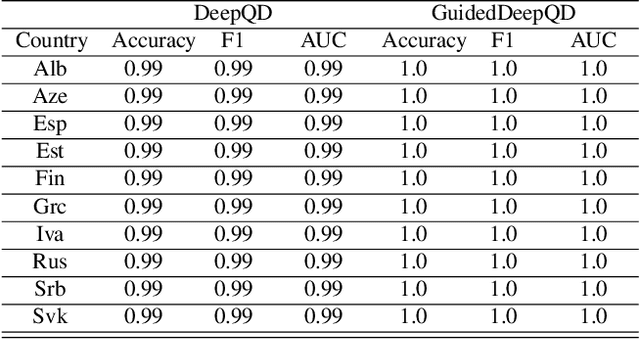
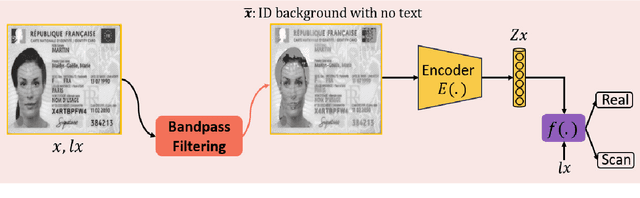
The increasing use of digital technologies and mobile-based registration procedures highlights the vital role of personal identity documents (IDs) in verifying users and safeguarding sensitive information. However, the rise in counterfeit ID production poses a significant challenge, necessitating the development of reliable and efficient automated verification methods. This paper introduces IDTrust, a deep-learning framework for assessing the quality of IDs. IDTrust is a system that enhances the quality of identification documents by using a deep learning-based approach. This method eliminates the need for relying on original document patterns for quality checks and pre-processing steps for alignment. As a result, it offers significant improvements in terms of dataset applicability. By utilizing a bandpass filtering-based method, the system aims to effectively detect and differentiate ID quality. Comprehensive experiments on the MIDV-2020 and L3i-ID datasets identify optimal parameters, significantly improving discrimination performance and effectively distinguishing between original and scanned ID documents.
HoughToRadon Transform: New Neural Network Layer for Features Improvement in Projection Space
Feb 05, 2024In this paper, we introduce HoughToRadon Transform layer, a novel layer designed to improve the speed of neural networks incorporated with Hough Transform to solve semantic image segmentation problems. By placing it after a Hough Transform layer, "inner" convolutions receive modified feature maps with new beneficial properties, such as a smaller area of processed images and parameter space linearity by angle and shift. These properties were not presented in Hough Transform alone. Furthermore, HoughToRadon Transform layer allows us to adjust the size of intermediate feature maps using two new parameters, thus allowing us to balance the speed and quality of the resulting neural network. Our experiments on the open MIDV-500 dataset show that this new approach leads to time savings in document segmentation tasks and achieves state-of-the-art 97.7% accuracy, outperforming HoughEncoder with larger computational complexity.
VS-Net: Multiscale Spatiotemporal Features for Lightweight Video Salient Document Detection
Jan 11, 2023



Video Salient Document Detection (VSDD) is an essential task of practical computer vision, which aims to highlight visually salient document regions in video frames. Previous techniques for VSDD focus on learning features without considering the cooperation among and across the appearance and motion cues and thus fail to perform in practical scenarios. Moreover, most of the previous techniques demand high computational resources, which limits the usage of such systems in resource-constrained settings. To handle these issues, we propose VS-Net, which captures multi-scale spatiotemporal information with the help of dilated depth-wise separable convolution and Approximation Rank Pooling. VS-Net extracts the key features locally from each frame across embedding sub-spaces and forwards the features between adjacent and parallel nodes, enhancing model performance globally. Our model generates saliency maps considering both the background and foreground simultaneously, making it perform better in challenging scenarios. The immense experiments regulated on the benchmark MIDV-500 dataset show that the VS-Net model outperforms state-of-the-art approaches in both time and robustness measures.
Identity Documents Authentication based on Forgery Detection of Guilloche Pattern
Jun 22, 2022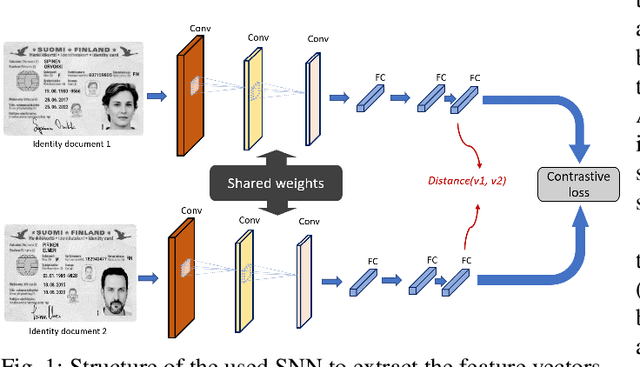

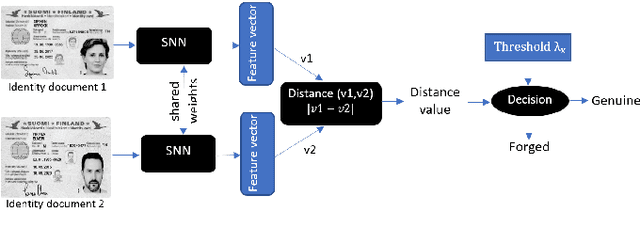

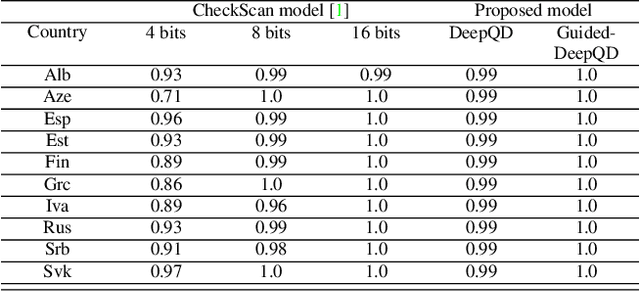
In cases such as digital enrolment via mobile and online services, identity document verification is critical in order to efficiently detect forgery and therefore build user trust in the digital world. In this paper, an authentication model for identity documents based on forgery detection of guilloche patterns is proposed. The proposed approach is made up of two steps: feature extraction and similarity measure between a pair of feature vectors of identity documents. The feature extraction step involves learning the similarity between a pair of identity documents via a convolutional neural network (CNN) architecture and ends by extracting highly discriminative features between them. While, the similarity measure step is applied to decide if a given identity document is authentic or forged. In this work, these two steps are combined together to achieve two objectives: (i) extracted features should have good anticollision (discriminative) capabilities to distinguish between a pair of identity documents belonging to different classes, (ii) checking out the conformity of the guilloche pattern of a given identity document and its similarity to the guilloche pattern of an authentic version of the same country. Experiments are conducted in order to analyze and identify the most proper parameters to achieve higher authentication performance. The experimental results are performed on the MIDV-2020 dataset. The results show the ability of the proposed approach to extract the relevant characteristics of the processed pair of identity documents in order to model the guilloche patterns, and thus distinguish them correctly. The implementation code and the forged dataset are provided here (https://drive.google.com/id-FDGP-1)
Tiny CNN for feature point description for document analysis: approach and dataset
Sep 09, 2021



In this paper, we study the problem of feature points description in the context of document analysis and template matching. Our study shows that the specific training data is required for the task especially if we are to train a lightweight neural network that will be usable on devices with limited computational resources. In this paper, we construct and provide a dataset with a method of training patches retrieval. We prove the effectiveness of this data by training a lightweight neural network and show how it performs in both documents and general patches matching. The training was done on the provided dataset in comparison with HPatches training dataset and for the testing we use HPatches testing framework and two publicly available datasets with various documents pictured on complex backgrounds: MIDV-500 and MIDV-2019.
MIDV-2020: A Comprehensive Benchmark Dataset for Identity Document Analysis
Jul 01, 2021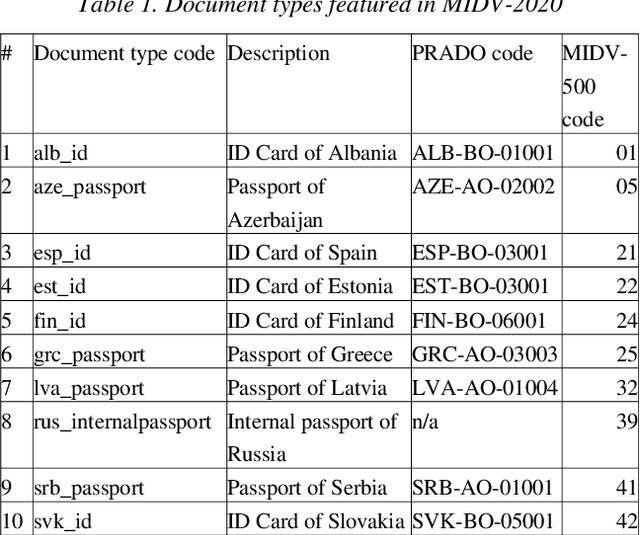

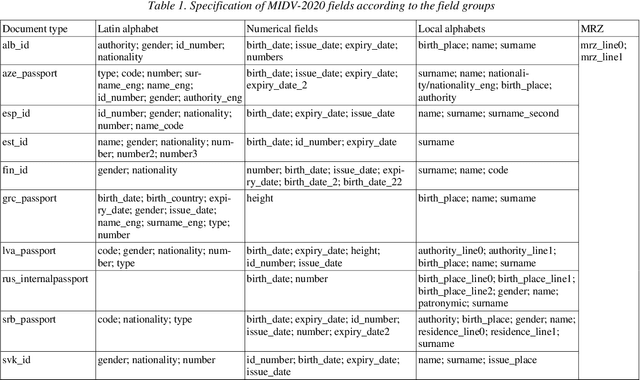

Identity documents recognition is an important sub-field of document analysis, which deals with tasks of robust document detection, type identification, text fields recognition, as well as identity fraud prevention and document authenticity validation given photos, scans, or video frames of an identity document capture. Significant amount of research has been published on this topic in recent years, however a chief difficulty for such research is scarcity of datasets, due to the subject matter being protected by security requirements. A few datasets of identity documents which are available lack diversity of document types, capturing conditions, or variability of document field values. In addition, the published datasets were typically designed only for a subset of document recognition problems, not for a complex identity document analysis. In this paper, we present a dataset MIDV-2020 which consists of 1000 video clips, 2000 scanned images, and 1000 photos of 1000 unique mock identity documents, each with unique text field values and unique artificially generated faces, with rich annotation. For the presented benchmark dataset baselines are provided for such tasks as document location and identification, text fields recognition, and face detection. With 72409 annotated images in total, to the date of publication the proposed dataset is the largest publicly available identity documents dataset with variable artificially generated data, and we believe that it will prove invaluable for advancement of the field of document analysis and recognition. The dataset is available for download at ftp://smartengines.com/midv-2020 and http://l3i-share.univ-lr.fr .
Advanced Hough-based method for on-device document localization
Jun 18, 2021
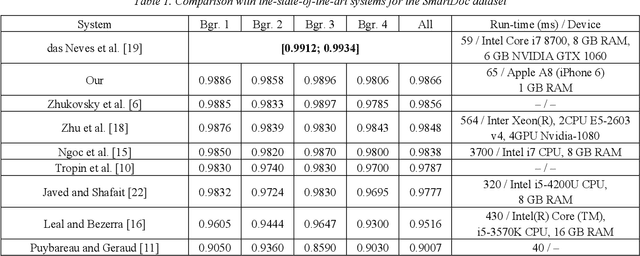


The demand for on-device document recognition systems increases in conjunction with the emergence of more strict privacy and security requirements. In such systems, there is no data transfer from the end device to a third-party information processing servers. The response time is vital to the user experience of on-device document recognition. Combined with the unavailability of discrete GPUs, powerful CPUs, or a large RAM capacity on consumer-grade end devices such as smartphones, the time limitations put significant constraints on the computational complexity of the applied algorithms for on-device execution. In this work, we consider document location in an image without prior knowledge of the document content or its internal structure. In accordance with the published works, at least 5 systems offer solutions for on-device document location. All these systems use a location method which can be considered Hough-based. The precision of such systems seems to be lower than that of the state-of-the-art solutions which were not designed to account for the limited computational resources. We propose an advanced Hough-based method. In contrast with other approaches, it accounts for the geometric invariants of the central projection model and combines both edge and color features for document boundary detection. The proposed method allowed for the second best result for SmartDoc dataset in terms of precision, surpassed by U-net like neural network. When evaluated on a more challenging MIDV-500 dataset, the proposed algorithm guaranteed the best precision compared to published methods. Our method retained the applicability to on-device computations.
Fast Implementation of 4-bit Convolutional Neural Networks for Mobile Devices
Sep 14, 2020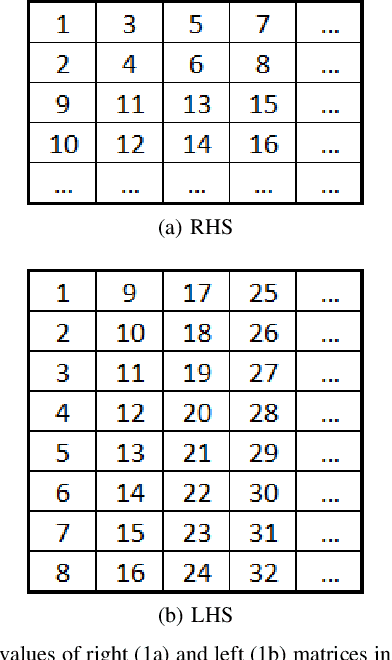
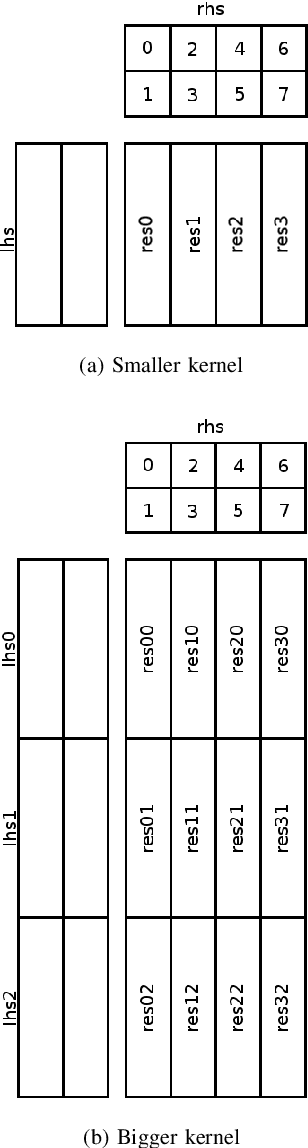

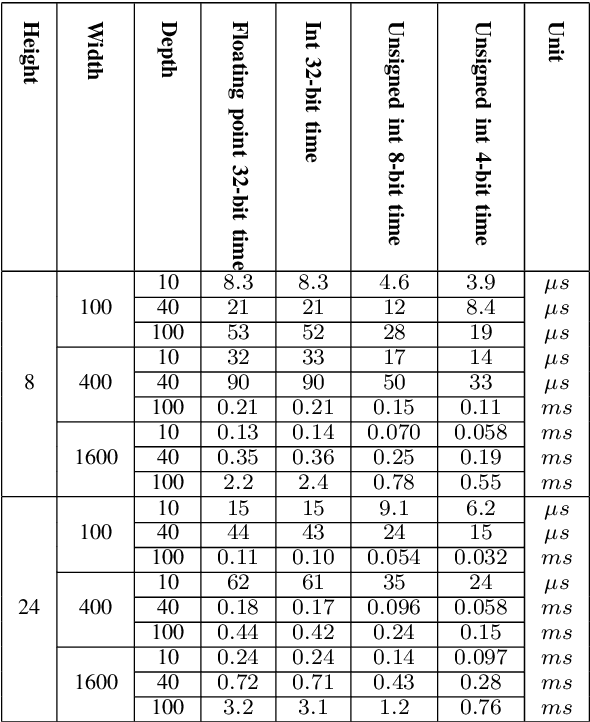
Quantized low-precision neural networks are very popular because they require less computational resources for inference and can provide high performance, which is vital for real-time and embedded recognition systems. However, their advantages are apparent for FPGA and ASIC devices, while general-purpose processor architectures are not always able to perform low-bit integer computations efficiently. The most frequently used low-precision neural network model for mobile central processors is an 8-bit quantized network. However, in a number of cases, it is possible to use fewer bits for weights and activations, and the only problem is the difficulty of efficient implementation. We introduce an efficient implementation of 4-bit matrix multiplication for quantized neural networks and perform time measurements on a mobile ARM processor. It shows 2.9 times speedup compared to standard floating-point multiplication and is 1.5 times faster than 8-bit quantized one. We also demonstrate a 4-bit quantized neural network for OCR recognition on the MIDV-500 dataset. 4-bit quantization gives 95.0% accuracy and 48% overall inference speedup, while an 8-bit quantized network gives 95.4% accuracy and 39% speedup. The results show that 4-bit quantization perfectly suits mobile devices, yielding good enough accuracy and low inference time.