 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnfolder: Fast localization and image rectification of a document with a crease from folding in half
Dec 01, 2023Presentation of folded documents is not an uncommon case in modern society. Digitizing such documents by capturing them with a smartphone camera can be tricky since a crease can divide the document contents into separate planes. To unfold the document, one could hold the edges potentially obscuring it in a captured image. While there are many geometrical rectification methods, they were usually developed for arbitrary bends and folds. We consider such algorithms and propose a novel approach Unfolder developed specifically for images of documents with a crease from folding in half. Unfolder is robust to projective distortions of the document image and does not fragment the image in the vicinity of a crease after rectification. A new Folded Document Images dataset was created to investigate the rectification accuracy of folded (2, 3, 4, and 8 folds) documents. The dataset includes 1600 images captured when document placed on a table and when held in hand. The Unfolder algorithm allowed for a recognition error rate of 0.33, which is better than the advanced neural network methods DocTr (0.44) and DewarpNet (0.57). The average runtime for Unfolder was only 0.25 s/image on an iPhone XR.
Advanced Hough-based method for on-device document localization
Jun 18, 2021
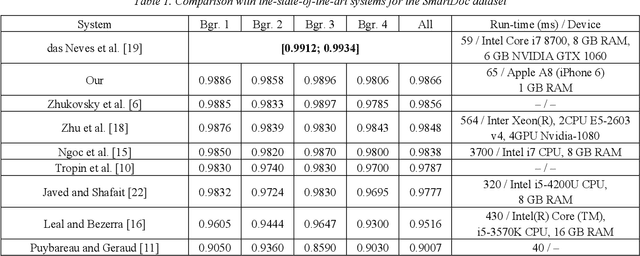


The demand for on-device document recognition systems increases in conjunction with the emergence of more strict privacy and security requirements. In such systems, there is no data transfer from the end device to a third-party information processing servers. The response time is vital to the user experience of on-device document recognition. Combined with the unavailability of discrete GPUs, powerful CPUs, or a large RAM capacity on consumer-grade end devices such as smartphones, the time limitations put significant constraints on the computational complexity of the applied algorithms for on-device execution. In this work, we consider document location in an image without prior knowledge of the document content or its internal structure. In accordance with the published works, at least 5 systems offer solutions for on-device document location. All these systems use a location method which can be considered Hough-based. The precision of such systems seems to be lower than that of the state-of-the-art solutions which were not designed to account for the limited computational resources. We propose an advanced Hough-based method. In contrast with other approaches, it accounts for the geometric invariants of the central projection model and combines both edge and color features for document boundary detection. The proposed method allowed for the second best result for SmartDoc dataset in terms of precision, surpassed by U-net like neural network. When evaluated on a more challenging MIDV-500 dataset, the proposed algorithm guaranteed the best precision compared to published methods. Our method retained the applicability to on-device computations.
A Low Computational Approach for Price Tag Recognition
Dec 04, 2019


In this work we discuss the task of search, localization and recognition of price zone within a photograph of the price tag. The task is being addressed for the case when image is acquired by small-scale digital camera and calculation device has significant resource constraints. The proposed approach is based on Niblack binarization algorithm, analysis and clasterization of connected components in conditions of known price tag geometrical model. The algorithm was tested on a private dataset and has shown high quality.
On the use of FHT, its modification for practical applications and the structure of Hough image
Nov 14, 2018This work focuses on the Fast Hough Transform (FHT) algorithm proposed by M.L. Brady. We propose how to modify the standard FHT to calculate sums along lines within any given range of their inclination angles. We also describe a new way to visualise Hough-image based on regrouping of accumulator space around its center. Finally, we prove that using Brady parameterization transforms any line into a figure of type "angle".