 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandwritten Chinese Text Recognition
Handwritten Chinese text recognition is the process of transcribing handwritten Chinese characters into digital text.
Papers and Code
Enhancement of text recognition for hanja handwritten documents of Ancient Korea
Dec 14, 2024We implemented a high-performance optical character recognition model for classical handwritten documents using data augmentation with highly variable cropping within the document region. Optical character recognition in handwritten documents, especially classical documents, has been a challenging topic in many countries and research organizations due to its difficulty. Although many researchers have conducted research on this topic, the quality of classical texts over time and the unique stylistic characteristics of various authors have made it difficult, and it is clear that the recognition of hanja handwritten documents is a meaningful and special challenge, especially since hanja, which has been developed by reflecting the vocabulary, semantic, and syntactic features of the Joseon Dynasty, is different from classical Chinese characters. To study this challenge, we used 1100 cursive documents, which are small in size, and augmented 100 documents per document by cropping a randomly sized region within each document for training, and trained them using a two-stage object detection model, High resolution neural network (HRNet), and applied the resulting model to achieve a high inference recognition rate of 90% for cursive documents. Through this study, we also confirmed that the performance of OCR is affected by the simplified characters, variants, variant characters, common characters, and alternators of Chinese characters that are difficult to see in other studies, and we propose that the results of this study can be applied to optical character recognition of modern documents in multiple languages as well as other typefaces in classical documents.
General Detection-based Text Line Recognition
Sep 25, 2024



We introduce a general detection-based approach to text line recognition, be it printed (OCR) or handwritten (HTR), with Latin, Chinese, or ciphered characters. Detection-based approaches have until now been largely discarded for HTR because reading characters separately is often challenging, and character-level annotation is difficult and expensive. We overcome these challenges thanks to three main insights: (i) synthetic pre-training with sufficiently diverse data enables learning reasonable character localization for any script; (ii) modern transformer-based detectors can jointly detect a large number of instances, and, if trained with an adequate masking strategy, leverage consistency between the different detections; (iii) once a pre-trained detection model with approximate character localization is available, it is possible to fine-tune it with line-level annotation on real data, even with a different alphabet. Our approach, dubbed DTLR, builds on a completely different paradigm than state-of-the-art HTR methods, which rely on autoregressive decoding, predicting character values one by one, while we treat a complete line in parallel. Remarkably, we demonstrate good performance on a large range of scripts, usually tackled with specialized approaches. In particular, we improve state-of-the-art performances for Chinese script recognition on the CASIA v2 dataset, and for cipher recognition on the Borg and Copiale datasets. Our code and models are available at https://github.com/raphael-baena/DTLR.
Integrating Canonical Neural Units and Multi-Scale Training for Handwritten Text Recognition
Oct 24, 2024The segmentation-free research efforts for addressing handwritten text recognition can be divided into three categories: connectionist temporal classification (CTC), hidden Markov model and encoder-decoder methods. In this paper, inspired by the above three modeling methods, we propose a new recognition network by using a novel three-dimensional (3D) attention module and global-local context information. Based on the feature maps of the last convolutional layer, a series of 3D blocks with different resolutions are split. Then, these 3D blocks are fed into the 3D attention module to generate sequential visual features. Finally, by integrating the visual features and the corresponding global-local context features, a well-designed representation can be obtained. Main canonical neural units including attention mechanisms, fully-connected layer, recurrent unit and convolutional layer are efficiently organized into a network and can be jointly trained by the CTC loss and the cross-entropy loss. Experiments on the latest Chinese handwritten text datasets (the SCUT-HCCDoc and the SCUT-EPT) and one English handwritten text dataset (the IAM) show that the proposed method can make a new milestone.
HierCode: A Lightweight Hierarchical Codebook for Zero-shot Chinese Text Recognition
Mar 20, 2024

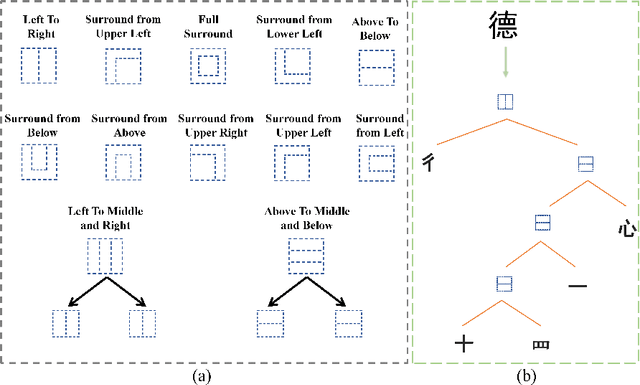

Text recognition, especially for complex scripts like Chinese, faces unique challenges due to its intricate character structures and vast vocabulary. Traditional one-hot encoding methods struggle with the representation of hierarchical radicals, recognition of Out-Of-Vocabulary (OOV) characters, and on-device deployment due to their computational intensity. To address these challenges, we propose HierCode, a novel and lightweight codebook that exploits the innate hierarchical nature of Chinese characters. HierCode employs a multi-hot encoding strategy, leveraging hierarchical binary tree encoding and prototype learning to create distinctive, informative representations for each character. This approach not only facilitates zero-shot recognition of OOV characters by utilizing shared radicals and structures but also excels in line-level recognition tasks by computing similarity with visual features, a notable advantage over existing methods. Extensive experiments across diverse benchmarks, including handwritten, scene, document, web, and ancient text, have showcased HierCode's superiority for both conventional and zero-shot Chinese character or text recognition, exhibiting state-of-the-art performance with significantly fewer parameters and fast inference speed.
DTrOCR: Decoder-only Transformer for Optical Character Recognition
Aug 30, 2023



Typical text recognition methods rely on an encoder-decoder structure, in which the encoder extracts features from an image, and the decoder produces recognized text from these features. In this study, we propose a simpler and more effective method for text recognition, known as the Decoder-only Transformer for Optical Character Recognition (DTrOCR). This method uses a decoder-only Transformer to take advantage of a generative language model that is pre-trained on a large corpus. We examined whether a generative language model that has been successful in natural language processing can also be effective for text recognition in computer vision. Our experiments demonstrated that DTrOCR outperforms current state-of-the-art methods by a large margin in the recognition of printed, handwritten, and scene text in both English and Chinese.
PageNet: Towards End-to-End Weakly Supervised Page-Level Handwritten Chinese Text Recognition
Jul 29, 2022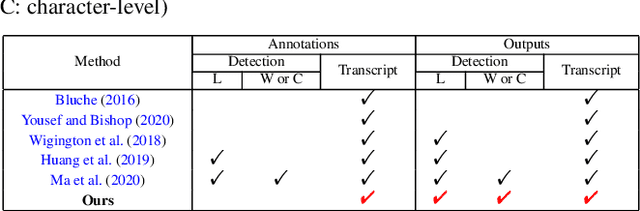
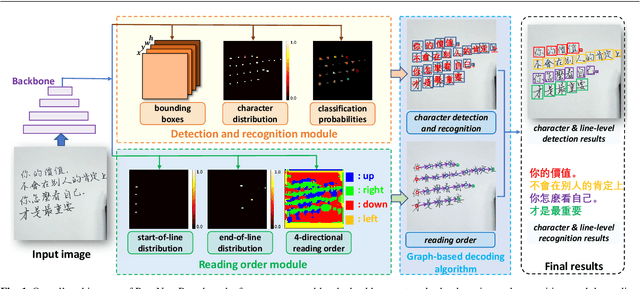
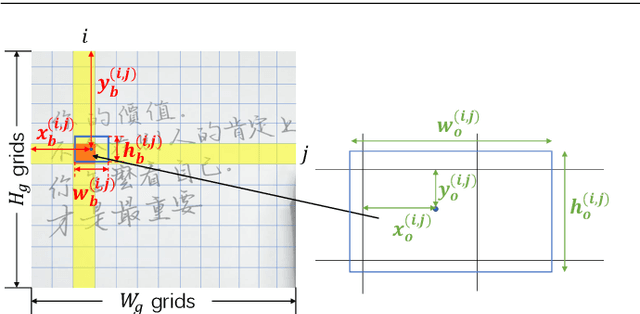

Handwritten Chinese text recognition (HCTR) has been an active research topic for decades. However, most previous studies solely focus on the recognition of cropped text line images, ignoring the error caused by text line detection in real-world applications. Although some approaches aimed at page-level text recognition have been proposed in recent years, they either are limited to simple layouts or require very detailed annotations including expensive line-level and even character-level bounding boxes. To this end, we propose PageNet for end-to-end weakly supervised page-level HCTR. PageNet detects and recognizes characters and predicts the reading order between them, which is more robust and flexible when dealing with complex layouts including multi-directional and curved text lines. Utilizing the proposed weakly supervised learning framework, PageNet requires only transcripts to be annotated for real data; however, it can still output detection and recognition results at both the character and line levels, avoiding the labor and cost of labeling bounding boxes of characters and text lines. Extensive experiments conducted on five datasets demonstrate the superiority of PageNet over existing weakly supervised and fully supervised page-level methods. These experimental results may spark further research beyond the realms of existing methods based on connectionist temporal classification or attention. The source code is available at https://github.com/shannanyinxiang/PageNet.
Recognition of Handwritten Chinese Text by Segmentation: A Segment-annotation-free Approach
Jul 29, 2022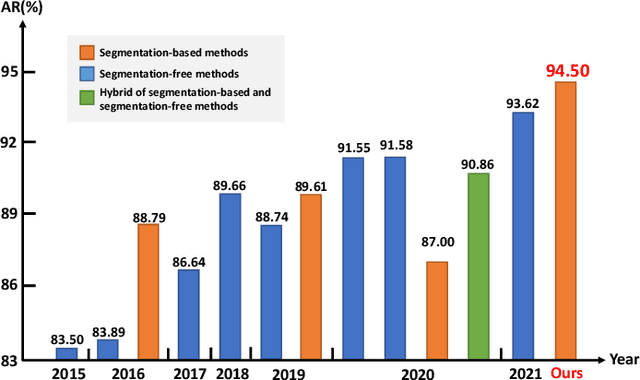


Online and offline handwritten Chinese text recognition (HTCR) has been studied for decades. Early methods adopted oversegmentation-based strategies but suffered from low speed, insufficient accuracy, and high cost of character segmentation annotations. Recently, segmentation-free methods based on connectionist temporal classification (CTC) and attention mechanism, have dominated the field of HCTR. However, people actually read text character by character, especially for ideograms such as Chinese. This raises the question: are segmentation-free strategies really the best solution to HCTR? To explore this issue, we propose a new segmentation-based method for recognizing handwritten Chinese text that is implemented using a simple yet efficient fully convolutional network. A novel weakly supervised learning method is proposed to enable the network to be trained using only transcript annotations; thus, the expensive character segmentation annotations required by previous segmentation-based methods can be avoided. Owing to the lack of context modeling in fully convolutional networks, we propose a contextual regularization method to integrate contextual information into the network during the training stage, which can further improve the recognition performance. Extensive experiments conducted on four widely used benchmarks, namely CASIA-HWDB, CASIA-OLHWDB, ICDAR2013, and SCUT-HCCDoc, show that our method significantly surpasses existing methods on both online and offline HCTR, and exhibits a considerably higher inference speed than CTC/attention-based approaches.
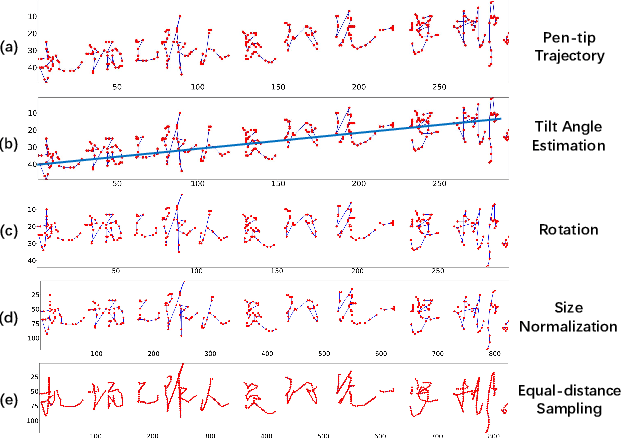
Recurrent neural network transducer for Japanese and Chinese offline handwritten text recognition
Jun 28, 2021


In this paper, we propose an RNN-Transducer model for recognizing Japanese and Chinese offline handwritten text line images. As far as we know, it is the first approach that adopts the RNN-Transducer model for offline handwritten text recognition. The proposed model consists of three main components: a visual feature encoder that extracts visual features from an input image by CNN and then encodes the visual features by BLSTM; a linguistic context encoder that extracts and encodes linguistic features from the input image by embedded layers and LSTM; and a joint decoder that combines and then decodes the visual features and the linguistic features into the final label sequence by fully connected and softmax layers. The proposed model takes advantage of both visual and linguistic information from the input image. In the experiments, we evaluated the performance of the proposed model on the two datasets: Kuzushiji and SCUT-EPT. Experimental results show that the proposed model achieves state-of-the-art performance on all datasets.
Offline Handwritten Chinese Text Recognition with Convolutional Neural Networks
Jun 28, 2020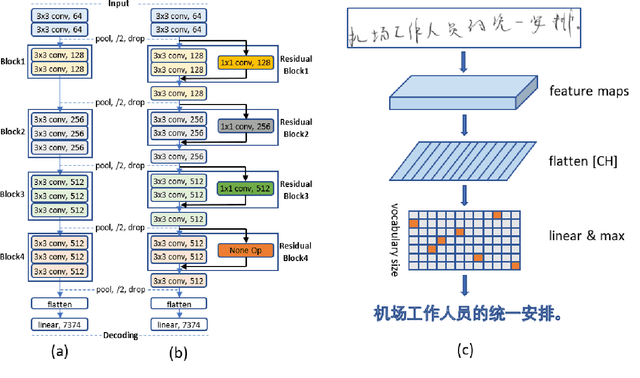
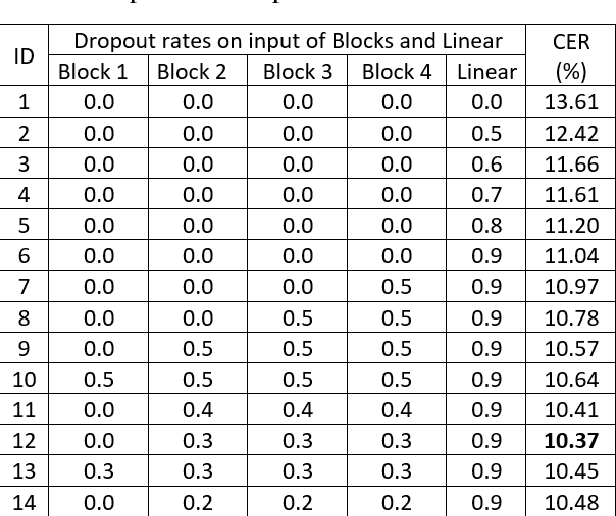
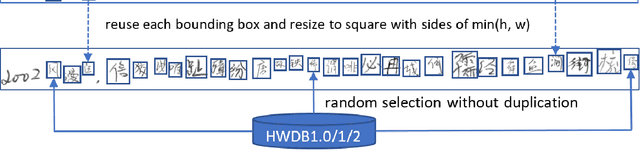
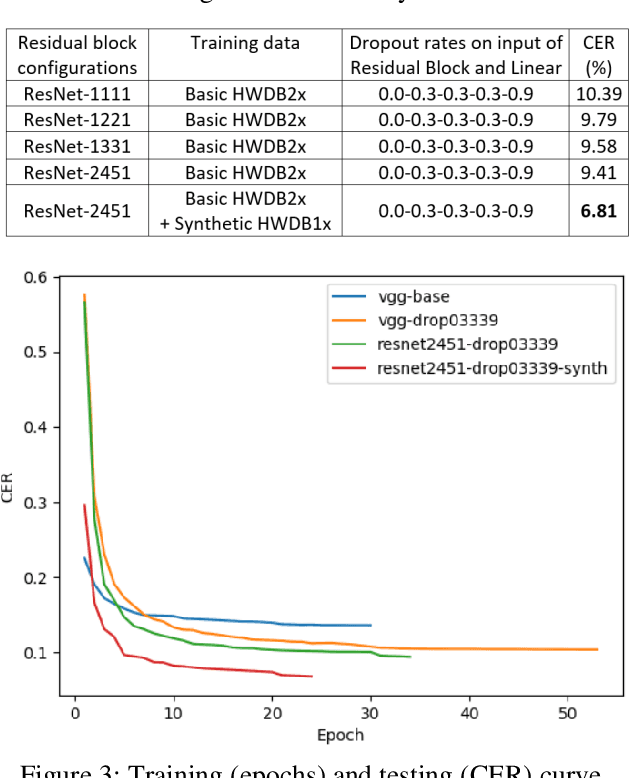
Deep learning based methods have been dominating the text recognition tasks in different and multilingual scenarios. The offline handwritten Chinese text recognition (HCTR) is one of the most challenging tasks because it involves thousands of characters, variant writing styles and complex data collection process. Recently, the recurrent-free architectures for text recognition appears to be competitive as its highly parallelism and comparable results. In this paper, we build the models using only the convolutional neural networks and use CTC as the loss function. To reduce the overfitting, we apply dropout after each max-pooling layer and with extreme high rate on the last one before the linear layer. The CASIA-HWDB database is selected to tune and evaluate the proposed models. With the existing text samples as templates, we randomly choose isolated character samples to synthesis more text samples for training. We finally achieve 6.81% character error rate (CER) on the ICDAR 2013 competition set, which is the best published result without language model correction.
Joint Architecture and Knowledge Distillation in Convolutional Neural Network for Offline Handwritten Chinese Text Recognition
Dec 17, 2019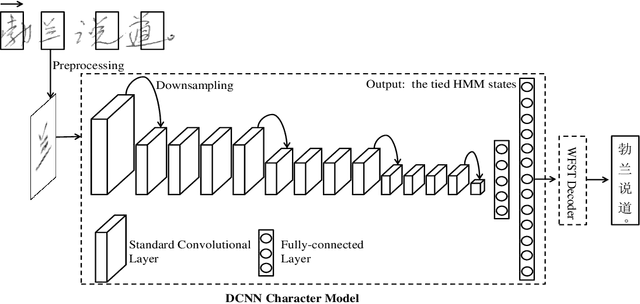
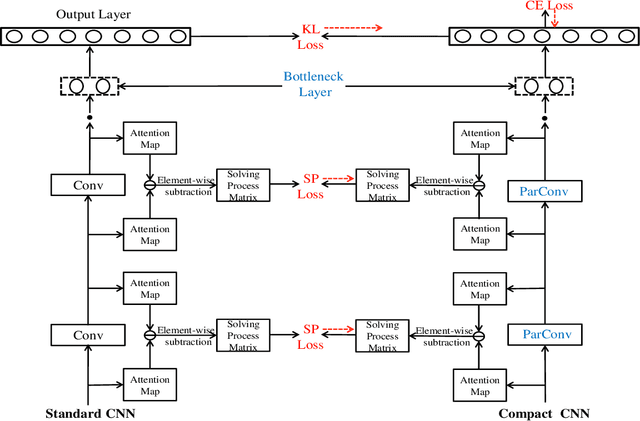
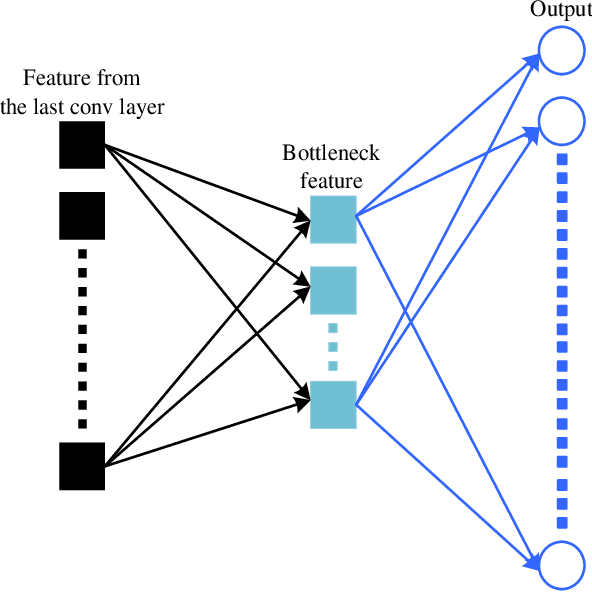
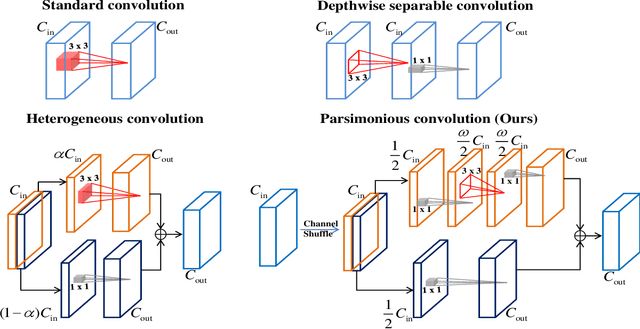
The technique of distillation helps transform cumbersome neural network into compact network so that the model can be deployed on alternative hardware devices. The main advantages of distillation based approaches include simple training process, supported by most off-the-shelf deep learning softwares and no special requirement of hardwares. In this paper, we propose a guideline to distill the architecture and knowledge of pre-trained standard CNNs simultaneously. We first make a quantitative analysis of the baseline network, including computational cost and storage overhead in different components. And then, according to the analysis results, optional strategies can be adopted to the compression of fully-connected layers. For vanilla convolution layers, the proposed parsimonious convolution (ParConv) block only consisting of depthwise separable convolution and pointwise convolution is used as a direct replacement without other adjustments such as the widths and depths in the network. Finally, the knowledge distillation with multiple losses is adopted to improve performance of the compact CNN. The proposed algorithm is first verified on offline handwritten Chinese text recognition (HCTR) where the CNNs are characterized by tens of thousands of output nodes and trained by hundreds of millions of training samples. Compared with the CNN in the state-of-the-art system, our proposed joint architecture and knowledge distillation can reduce the computational cost by >10x and model size by >8x with negligible accuracy loss. And then, by conducting experiments on one of the most popular data sets: MNIST, we demonstrate the proposed approach can also be successfully applied on mainstream backbone networks.