 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfhq
Papers and Code
Beyond the Loss Curve: Scaling Laws, Active Learning, and the Limits of Learning from Exact Posteriors
Jan 30, 2026How close are neural networks to the best they could possibly do? Standard benchmarks cannot answer this because they lack access to the true posterior p(y|x). We use class-conditional normalizing flows as oracles that make exact posteriors tractable on realistic images (AFHQ, ImageNet). This enables five lines of investigation. Scaling laws: Prediction error decomposes into irreducible aleatoric uncertainty and reducible epistemic error; the epistemic component follows a power law in dataset size, continuing to shrink even when total loss plateaus. Limits of learning: The aleatoric floor is exactly measurable, and architectures differ markedly in how they approach it: ResNets exhibit clean power-law scaling while Vision Transformers stall in low-data regimes. Soft labels: Oracle posteriors contain learnable structure beyond class labels: training with exact posteriors outperforms hard labels and yields near-perfect calibration. Distribution shift: The oracle computes exact KL divergence of controlled perturbations, revealing that shift type matters more than shift magnitude: class imbalance barely affects accuracy at divergence values where input noise causes catastrophic degradation. Active learning: Exact epistemic uncertainty distinguishes genuinely informative samples from inherently ambiguous ones, improving sample efficiency. Our framework reveals that standard metrics hide ongoing learning, mask architectural differences, and cannot diagnose the nature of distribution shift.
DragGANSpace: Latent Space Exploration and Control for GANs
Sep 26, 2025



This work integrates StyleGAN, DragGAN and Principal Component Analysis (PCA) to enhance the latent space efficiency and controllability of GAN-generated images. Style-GAN provides a structured latent space, DragGAN enables intuitive image manipulation, and PCA reduces dimensionality and facilitates cross-model alignment for more streamlined and interpretable exploration of latent spaces. We apply our techniques to the Animal Faces High Quality (AFHQ) dataset, and find that our approach of integrating PCA-based dimensionality reduction with the Drag-GAN framework for image manipulation retains performance while improving optimization efficiency. Notably, introducing PCA into the latent W+ layers of DragGAN can consistently reduce the total optimization time while maintaining good visual quality and even boosting the Structural Similarity Index Measure (SSIM) of the optimized image, particularly in shallower latent spaces (W+ layers = 3). We also demonstrate capability for aligning images generated by two StyleGAN models trained on similar but distinct data domains (AFHQ-Dog and AFHQ-Cat), and show that we can control the latent space of these aligned images to manipulate the images in an intuitive and interpretable manner. Our findings highlight the possibility for efficient and interpretable latent space control for a wide range of image synthesis and editing applications.
Machine Learning with Privacy for Protected Attributes
Jun 24, 2025



Differential privacy (DP) has become the standard for private data analysis. Certain machine learning applications only require privacy protection for specific protected attributes. Using naive variants of differential privacy in such use cases can result in unnecessary degradation of utility. In this work, we refine the definition of DP to create a more general and flexible framework that we call feature differential privacy (FDP). Our definition is simulation-based and allows for both addition/removal and replacement variants of privacy, and can handle arbitrary and adaptive separation of protected and non-protected features. We prove the properties of FDP, such as adaptive composition, and demonstrate its implications for limiting attribute inference attacks. We also propose a modification of the standard DP-SGD algorithm that satisfies FDP while leveraging desirable properties such as amplification via sub-sampling. We apply our framework to various machine learning tasks and show that it can significantly improve the utility of DP-trained models when public features are available. For example, we train diffusion models on the AFHQ dataset of animal faces and observe a drastic improvement in FID compared to DP, from 286.7 to 101.9 at $\epsilon=8$, assuming that the blurred version of a training image is available as a public feature. Overall, our work provides a new approach to private data analysis that can help reduce the utility cost of DP while still providing strong privacy guarantees.
Graph Flow Matching: Enhancing Image Generation with Neighbor-Aware Flow Fields
May 30, 2025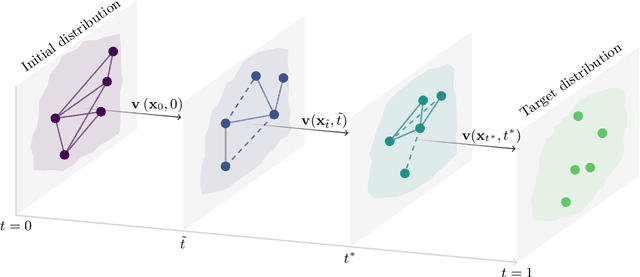
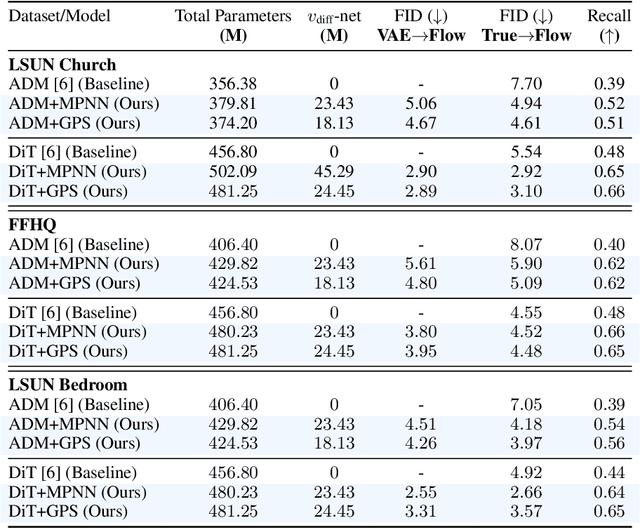

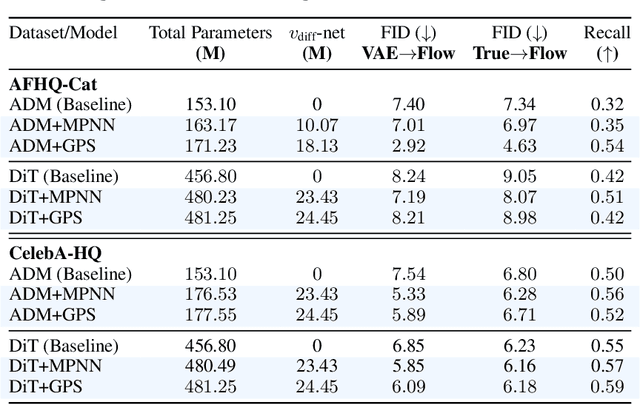
Flow matching casts sample generation as learning a continuous-time velocity field that transports noise to data. Existing flow matching networks typically predict each point's velocity independently, considering only its location and time along its flow trajectory, and ignoring neighboring points. However, this pointwise approach may overlook correlations between points along the generation trajectory that could enhance velocity predictions, thereby improving downstream generation quality. To address this, we propose Graph Flow Matching (GFM), a lightweight enhancement that decomposes the learned velocity into a reaction term -- any standard flow matching network -- and a diffusion term that aggregates neighbor information via a graph neural module. This reaction-diffusion formulation retains the scalability of deep flow models while enriching velocity predictions with local context, all at minimal additional computational cost. Operating in the latent space of a pretrained variational autoencoder, GFM consistently improves Fr\'echet Inception Distance (FID) and recall across five image generation benchmarks (LSUN Church, LSUN Bedroom, FFHQ, AFHQ-Cat, and CelebA-HQ at $256\times256$), demonstrating its effectiveness as a modular enhancement to existing flow matching architectures.
Accelerate TarFlow Sampling with GS-Jacobi Iteration
May 19, 2025Image generation models have achieved widespread applications. As an instance, the TarFlow model combines the transformer architecture with Normalizing Flow models, achieving state-of-the-art results on multiple benchmarks. However, due to the causal form of attention requiring sequential computation, TarFlow's sampling process is extremely slow. In this paper, we demonstrate that through a series of optimization strategies, TarFlow sampling can be greatly accelerated by using the Gauss-Seidel-Jacobi (abbreviated as GS-Jacobi) iteration method. Specifically, we find that blocks in the TarFlow model have varying importance: a small number of blocks play a major role in image generation tasks, while other blocks contribute relatively little; some blocks are sensitive to initial values and prone to numerical overflow, while others are relatively robust. Based on these two characteristics, we propose the Convergence Ranking Metric (CRM) and the Initial Guessing Metric (IGM): CRM is used to identify whether a TarFlow block is "simple" (converges in few iterations) or "tough" (requires more iterations); IGM is used to evaluate whether the initial value of the iteration is good. Experiments on four TarFlow models demonstrate that GS-Jacobi sampling can significantly enhance sampling efficiency while maintaining the quality of generated images (measured by FID), achieving speed-ups of 4.53x in Img128cond, 5.32x in AFHQ, 2.96x in Img64uncond, and 2.51x in Img64cond without degrading FID scores or sample quality. Code and checkpoints are accessible on https://github.com/encoreus/GS-Jacobi_for_TarFlow
U-Shape Mamba: State Space Model for faster diffusion
Apr 18, 2025Diffusion models have become the most popular approach for high-quality image generation, but their high computational cost still remains a significant challenge. To address this problem, we propose U-Shape Mamba (USM), a novel diffusion model that leverages Mamba-based layers within a U-Net-like hierarchical structure. By progressively reducing sequence length in the encoder and restoring it in the decoder through Mamba blocks, USM significantly lowers computational overhead while maintaining strong generative capabilities. Experimental results against Zigma, which is currently the most efficient Mamba-based diffusion model, demonstrate that USM achieves one-third the GFlops, requires less memory and is faster, while outperforming Zigma in image quality. Frechet Inception Distance (FID) is improved by 15.3, 0.84 and 2.7 points on AFHQ, CelebAHQ and COCO datasets, respectively. These findings highlight USM as a highly efficient and scalable solution for diffusion-based generative models, making high-quality image synthesis more accessible to the research community while reducing computational costs.
SemDiff: Generating Natural Unrestricted Adversarial Examples via Semantic Attributes Optimization in Diffusion Models
Apr 16, 2025Unrestricted adversarial examples (UAEs), allow the attacker to create non-constrained adversarial examples without given clean samples, posing a severe threat to the safety of deep learning models. Recent works utilize diffusion models to generate UAEs. However, these UAEs often lack naturalness and imperceptibility due to simply optimizing in intermediate latent noises. In light of this, we propose SemDiff, a novel unrestricted adversarial attack that explores the semantic latent space of diffusion models for meaningful attributes, and devises a multi-attributes optimization approach to ensure attack success while maintaining the naturalness and imperceptibility of generated UAEs. We perform extensive experiments on four tasks on three high-resolution datasets, including CelebA-HQ, AFHQ and ImageNet. The results demonstrate that SemDiff outperforms state-of-the-art methods in terms of attack success rate and imperceptibility. The generated UAEs are natural and exhibit semantically meaningful changes, in accord with the attributes' weights. In addition, SemDiff is found capable of evading different defenses, which further validates its effectiveness and threatening.
Generative Lines Matching Models
Dec 09, 2024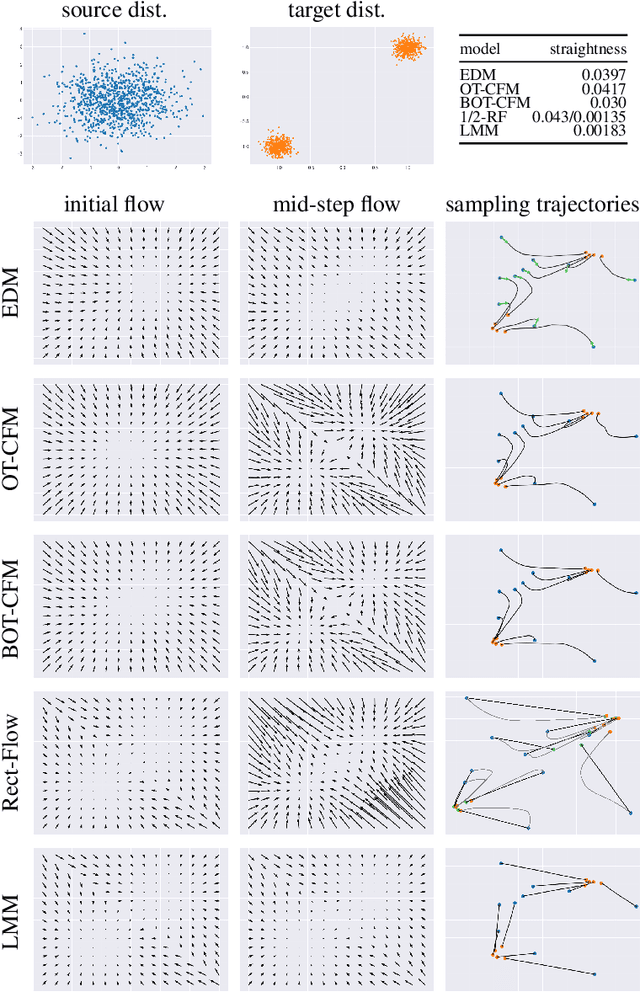



In this paper we identify the source of a singularity in the training loss of key denoising models, that causes the denoiser's predictions to collapse towards the mean of the source or target distributions. This degeneracy creates false basins of attraction, distorting the denoising trajectories and ultimately increasing the number of steps required to sample these models. We circumvent this artifact by leveraging the deterministic ODE-based samplers, offered by certain denoising diffusion and score-matching models, which establish a well-defined change-of-variables between the source and target distributions. Given this correspondence, we propose a new probability flow model, the Lines Matching Model (LMM), which matches globally straight lines interpolating the two distributions. We demonstrate that the flow fields produced by the LMM exhibit notable temporal consistency, resulting in trajectories with excellent straightness scores. Beyond its sampling efficiency, the LMM formulation allows us to enhance the fidelity of the generated samples by integrating domain-specific reconstruction and adversarial losses, and by optimizing its training for the sampling procedure used. Overall, the LMM achieves state-of-the-art FID scores with minimal NFEs on established benchmark datasets: 1.57/1.39 (NFE=1/2) on CIFAR-10, 1.47/1.17 on ImageNet 64x64, and 2.68/1.54 on AFHQ 64x64. Finally, we provide a theoretical analysis showing that the use of optimal transport to relate the two distributions suffers from a curse of dimensionality, where the pairing set size (mini-batch) must scale exponentially with the signal dimension.
Lazy Layers to Make Fine-Tuned Diffusion Models More Traceable
May 01, 2024



Foundational generative models should be traceable to protect their owners and facilitate safety regulation. To achieve this, traditional approaches embed identifiers based on supervisory trigger-response signals, which are commonly known as backdoor watermarks. They are prone to failure when the model is fine-tuned with nontrigger data. Our experiments show that this vulnerability is due to energetic changes in only a few 'busy' layers during fine-tuning. This yields a novel arbitrary-in-arbitrary-out (AIAO) strategy that makes watermarks resilient to fine-tuning-based removal. The trigger-response pairs of AIAO samples across various neural network depths can be used to construct watermarked subpaths, employing Monte Carlo sampling to achieve stable verification results. In addition, unlike the existing methods of designing a backdoor for the input/output space of diffusion models, in our method, we propose to embed the backdoor into the feature space of sampled subpaths, where a mask-controlled trigger function is proposed to preserve the generation performance and ensure the invisibility of the embedded backdoor. Our empirical studies on the MS-COCO, AFHQ, LSUN, CUB-200, and DreamBooth datasets confirm the robustness of AIAO; while the verification rates of other trigger-based methods fall from ~90% to ~70% after fine-tuning, those of our method remain consistently above 90%.
Parameter and Data-Efficient Spectral StyleDCGAN
Mar 31, 2024We present a simple, highly parameter, and data-efficient adversarial network for unconditional face generation. Our method: Spectral Style-DCGAN or SSD utilizes only 6.574 million parameters and 4739 dog faces from the Animal Faces HQ (AFHQ) dataset as training samples while preserving fidelity at low resolutions up to 64x64. Code available at https://github.com/Aryan-Garg/StyleDCGAN.