 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Knowledge Distillation for PET-Free Amyloid-Beta Detection from MRI
Apr 14, 2026Detecting amyloid-$β$ (A$β$) positivity is crucial for early diagnosis of Alzheimer's disease but typically requires PET imaging, which is costly, invasive, and not widely accessible, limiting its use for population-level screening. We address this gap by proposing a PET-guided knowledge distillation framework that enables A$β$ prediction from MRI alone, without requiring non-imaging clinical covariates or PET at inference. Our approach employs a BiomedCLIP-based teacher model that learns PET-MRI alignment via cross-modal attention and triplet contrastive learning with PET-informed (Centiloid-aware) online negative sampling. An MRI-only student then mimics the teacher via feature-level and logit-level distillation. Evaluated across four MRI contrasts (T1w, T2w, FLAIR, T2*) and two independent datasets, our approach demonstrates effective knowledge transfer (best AUC: 0.74 on OASIS-3, 0.68 on ADNI) while maintaining interpretability and eliminating the need for clinical variables. Saliency analysis confirms that predictions focus on anatomically relevant cortical regions, supporting the clinical viability of PET-free A$β$ screening. Code is available at https://github.com/FrancescoChiumento/pet-guided-mri-amyloid-detection.
Hold-One-Shot-Out (HOSO) for Validation-Free Few-Shot CLIP Adapters
Mar 04, 2026In many CLIP adaptation methods, a blending ratio hyperparameter controls the trade-off between general pretrained CLIP knowledge and the limited, dataset-specific supervision from the few-shot cases. Most few-shot CLIP adaptation techniques report results by ablation of the blending ratio on the test set or require additional validation sets to select the blending ratio per dataset, and thus are not strictly few-shot. We present a simple, validation-free method for learning the blending ratio in CLIP adaptation. Hold-One-Shot-Out (HOSO) presents a novel approach for CLIP-Adapter-style methods to compete in the newly established validation-free setting. CLIP-Adapter with HOSO (HOSO-Adapter) learns the blending ratio using a one-shot, hold-out set, while the adapter trains on the remaining few-shot support examples. Under the validation-free few-shot protocol, HOSO-Adapter outperforms the CLIP-Adapter baseline by more than 4 percentage points on average across 11 standard few-shot datasets. Interestingly, in the 8- and 16-shot settings, HOSO-Adapter outperforms CLIP-Adapter even with the optimal blending ratio selected on the test set. Ablation studies validate the use of a one-shot hold-out mechanism, decoupled training, and improvements over the naively learnt blending ratio baseline. Code is released here: https://github.com/chris-vorster/HOSO-Adapter
Underrepresented in Foundation Model Pretraining Data? A One-Shot Probe
Mar 04, 2026Large-scale Vision-Language Foundation Models (VLFMs), such as CLIP, now underpin a wide range of computer vision research and applications. VLFMs are often adapted to various domain-specific tasks. However, VLFM performance on novel, specialised, or underrepresented domains remains inconsistent. Evaluating VLFMs typically requires labelled test sets, which are often unavailable for niche domains of interest, particularly those from the Global South. We address this gap by proposing a highly data-efficient method to predict a VLFM's zero-shot accuracy on a target domain using only a single labelled image per class. Our approach uses a Large Language Model to generate plausible counterfactual descriptions of a given image. By measuring the VLFM's ability to distinguish the correct description from these hard negatives, we engineer features that capture the VLFM's discriminative power in its shared embedding space. A linear regressor trained on these similarity scores estimates the VLFM's zero-shot test accuracy across various visual domains with a Pearson-r correlation of 0.96. We demonstrate our method's performance across five diverse datasets, including standard benchmark datasets and underrepresented datasets from Africa. Our work provides a low-cost, reliable tool for probing VLFMs, enabling researchers and practitioners to make informed decisions about data annotation efforts before committing significant resources. The model training code, generated captions and counterfactuals are released here: https://github.com/chris-vorster/PreLabellingProbe.
VLSM-Ensemble: Ensembling CLIP-based Vision-Language Models for Enhanced Medical Image Segmentation
Sep 05, 2025Vision-language models and their adaptations to image segmentation tasks present enormous potential for producing highly accurate and interpretable results. However, implementations based on CLIP and BiomedCLIP are still lagging behind more sophisticated architectures such as CRIS. In this work, instead of focusing on text prompt engineering as is the norm, we attempt to narrow this gap by showing how to ensemble vision-language segmentation models (VLSMs) with a low-complexity CNN. By doing so, we achieve a significant Dice score improvement of 6.3% on the BKAI polyp dataset using the ensembled BiomedCLIPSeg, while other datasets exhibit gains ranging from 1% to 6%. Furthermore, we provide initial results on additional four radiology and non-radiology datasets. We conclude that ensembling works differently across these datasets (from outperforming to underperforming the CRIS model), indicating a topic for future investigation by the community. The code is available at https://github.com/juliadietlmeier/VLSM-Ensemble.
Parameter-Free Bio-Inspired Channel Attention for Enhanced Cardiac MRI Reconstruction
May 29, 2025Attention is a fundamental component of the human visual recognition system. The inclusion of attention in a convolutional neural network amplifies relevant visual features and suppresses the less important ones. Integrating attention mechanisms into convolutional neural networks enhances model performance and interpretability. Spatial and channel attention mechanisms have shown significant advantages across many downstream tasks in medical imaging. While existing attention modules have proven to be effective, their design often lacks a robust theoretical underpinning. In this study, we address this gap by proposing a non-linear attention architecture for cardiac MRI reconstruction and hypothesize that insights from ecological principles can guide the development of effective and efficient attention mechanisms. Specifically, we investigate a non-linear ecological difference equation that describes single-species population growth to devise a parameter-free attention module surpassing current state-of-the-art parameter-free methods.
Reinforcement Learning meets Masked Video Modeling : Trajectory-Guided Adaptive Token Selection
May 13, 2025Masked video modeling~(MVM) has emerged as a highly effective pre-training strategy for visual foundation models, whereby the model reconstructs masked spatiotemporal tokens using information from visible tokens. However, a key challenge in such approaches lies in selecting an appropriate masking strategy. Previous studies have explored predefined masking techniques, including random and tube-based masking, as well as approaches that leverage key motion priors, optical flow and semantic cues from externally pre-trained models. In this work, we introduce a novel and generalizable Trajectory-Aware Adaptive Token Sampler (TATS), which models the motion dynamics of tokens and can be seamlessly integrated into the masked autoencoder (MAE) framework to select motion-centric tokens in videos. Additionally, we propose a unified training strategy that enables joint optimization of both MAE and TATS from scratch using Proximal Policy Optimization (PPO). We show that our model allows for aggressive masking without compromising performance on the downstream task of action recognition while also ensuring that the pre-training remains memory efficient. Extensive experiments of the proposed approach across four benchmarks, including Something-Something v2, Kinetics-400, UCF101, and HMDB51, demonstrate the effectiveness, transferability, generalization, and efficiency of our work compared to other state-of-the-art methods.
Pinpoint Counterfactuals: Reducing social bias in foundation models via localized counterfactual generation
Dec 12, 2024
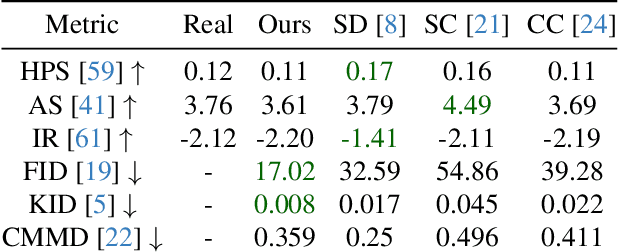

Foundation models trained on web-scraped datasets propagate societal biases to downstream tasks. While counterfactual generation enables bias analysis, existing methods introduce artifacts by modifying contextual elements like clothing and background. We present a localized counterfactual generation method that preserves image context by constraining counterfactual modifications to specific attribute-relevant regions through automated masking and guided inpainting. When applied to the Conceptual Captions dataset for creating gender counterfactuals, our method results in higher visual and semantic fidelity than state-of-the-art alternatives, while maintaining the performance of models trained using only real data on non-human-centric tasks. Models fine-tuned with our counterfactuals demonstrate measurable bias reduction across multiple metrics, including a decrease in gender classification disparity and balanced person preference scores, while preserving ImageNet zero-shot performance. The results establish a framework for creating balanced datasets that enable both accurate bias profiling and effective mitigation.
From Unimodal to Multimodal: Scaling up Projectors to Align Modalities
Sep 28, 2024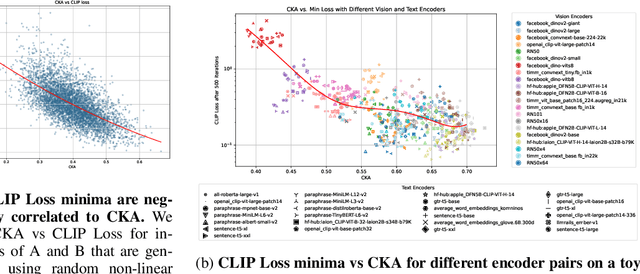
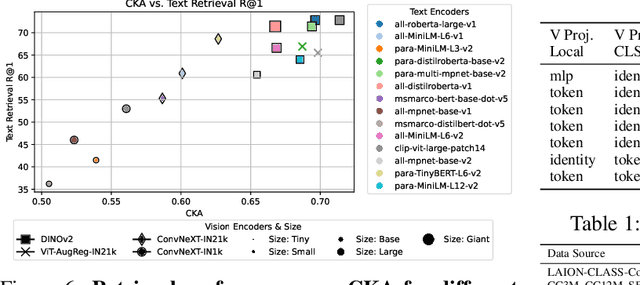

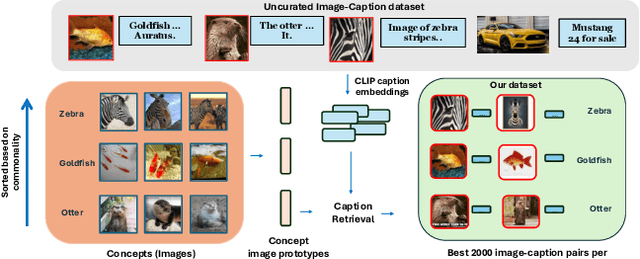
Recent contrastive multimodal vision-language models like CLIP have demonstrated robust open-world semantic understanding, becoming the standard image backbones for vision-language applications due to their aligned latent space. However, this practice has left powerful unimodal encoders for both vision and language underutilized in multimodal applications which raises a key question: Is there a plausible way to connect unimodal backbones for zero-shot vision-language tasks? To this end, we propose a novel approach that aligns vision and language modalities using only projection layers on pretrained, frozen unimodal encoders. Our method exploits the high semantic similarity between embedding spaces of well-trained vision and language models. It involves selecting semantically similar encoders in the latent space, curating a concept-rich dataset of image-caption pairs, and training simple MLP projectors. We evaluated our approach on 12 zero-shot classification datasets and 2 image-text retrieval datasets. Our best model, utilizing DINOv2 and All-Roberta-Large text encoder, achieves 76\(\%\) accuracy on ImageNet with a 20-fold reduction in data and 65 fold reduction in compute requirements. The proposed framework enhances the accessibility of model development while enabling flexible adaptation across diverse scenarios, offering an efficient approach to building multimodal models by utilizing existing unimodal architectures. Code and datasets will be released soon.
Synthetic Time Series for Anomaly Detection in Cloud Microservices
Jul 21, 2024



This paper proposes a framework for time series generation built to investigate anomaly detection in cloud microservices. In the field of cloud computing, ensuring the reliability of microservices is of paramount concern and yet a remarkably challenging task. Despite the large amount of research in this area, validation of anomaly detection algorithms in realistic environments is difficult to achieve. To address this challenge, we propose a framework to mimic the complex time series patterns representative of both normal and anomalous cloud microservices behaviors. We detail the pipeline implementation that allows deployment and management of microservices as well as the theoretical approach required to generate anomalies. Two datasets generated using the proposed framework have been made publicly available through GitHub.
An accurate detection is not all you need to combat label noise in web-noisy datasets
Jul 08, 2024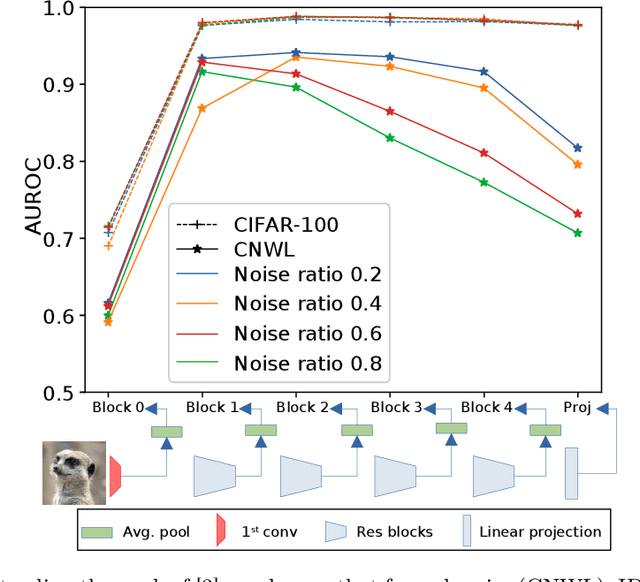
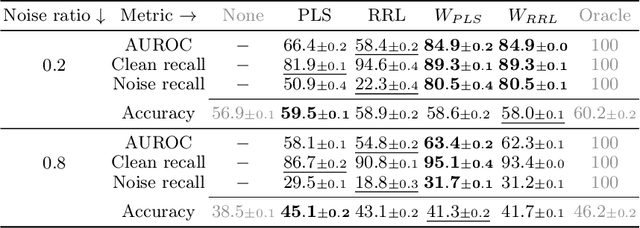

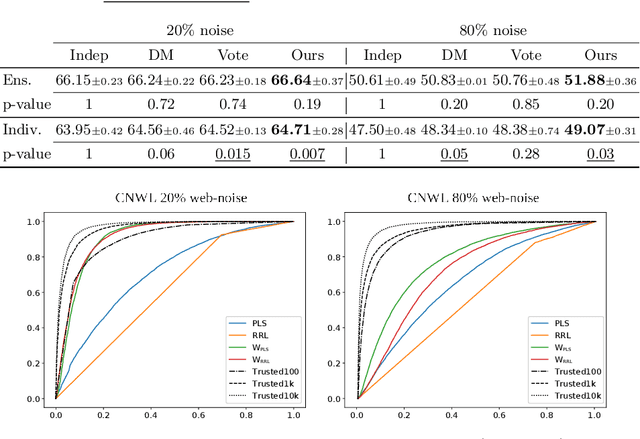
Training a classifier on web-crawled data demands learning algorithms that are robust to annotation errors and irrelevant examples. This paper builds upon the recent empirical observation that applying unsupervised contrastive learning to noisy, web-crawled datasets yields a feature representation under which the in-distribution (ID) and out-of-distribution (OOD) samples are linearly separable. We show that direct estimation of the separating hyperplane can indeed offer an accurate detection of OOD samples, and yet, surprisingly, this detection does not translate into gains in classification accuracy. Digging deeper into this phenomenon, we discover that the near-perfect detection misses a type of clean examples that are valuable for supervised learning. These examples often represent visually simple images, which are relatively easy to identify as clean examples using standard loss- or distance-based methods despite being poorly separated from the OOD distribution using unsupervised learning. Because we further observe a low correlation with SOTA metrics, this urges us to propose a hybrid solution that alternates between noise detection using linear separation and a state-of-the-art (SOTA) small-loss approach. When combined with the SOTA algorithm PLS, we substantially improve SOTA results for real-world image classification in the presence of web noise github.com/PaulAlbert31/LSA