 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTumor Detection, Segmentation and Classification Challenge on Automated 3D Breast Ultrasound: The TDSC-ABUS Challenge
Jan 26, 2025



Breast cancer is one of the most common causes of death among women worldwide. Early detection helps in reducing the number of deaths. Automated 3D Breast Ultrasound (ABUS) is a newer approach for breast screening, which has many advantages over handheld mammography such as safety, speed, and higher detection rate of breast cancer. Tumor detection, segmentation, and classification are key components in the analysis of medical images, especially challenging in the context of 3D ABUS due to the significant variability in tumor size and shape, unclear tumor boundaries, and a low signal-to-noise ratio. The lack of publicly accessible, well-labeled ABUS datasets further hinders the advancement of systems for breast tumor analysis. Addressing this gap, we have organized the inaugural Tumor Detection, Segmentation, and Classification Challenge on Automated 3D Breast Ultrasound 2023 (TDSC-ABUS2023). This initiative aims to spearhead research in this field and create a definitive benchmark for tasks associated with 3D ABUS image analysis. In this paper, we summarize the top-performing algorithms from the challenge and provide critical analysis for ABUS image examination. We offer the TDSC-ABUS challenge as an open-access platform at https://tdsc-abus2023.grand-challenge.org/ to benchmark and inspire future developments in algorithmic research.
Data Generation using Texture Co-occurrence and Spatial Self-Similarity for Debiasing
Oct 15, 2021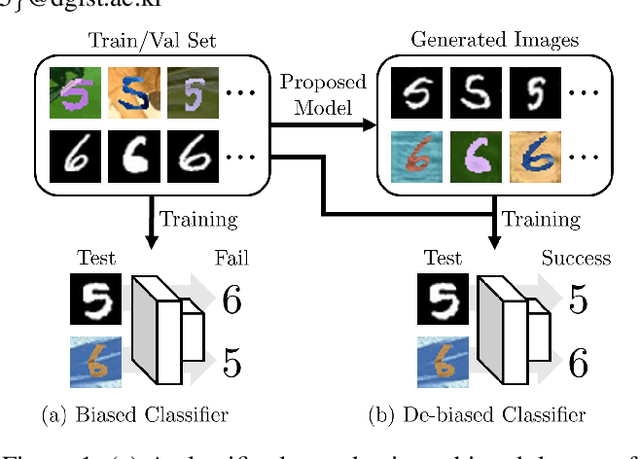
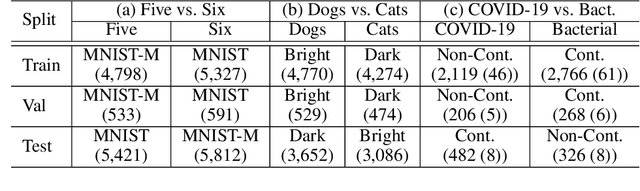
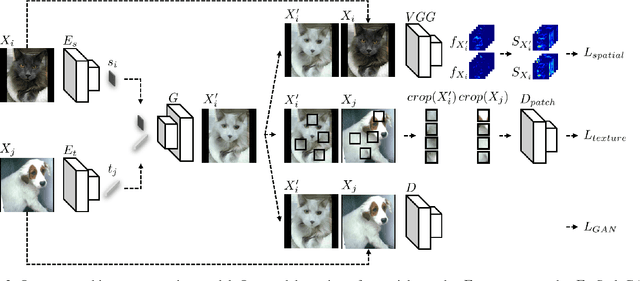
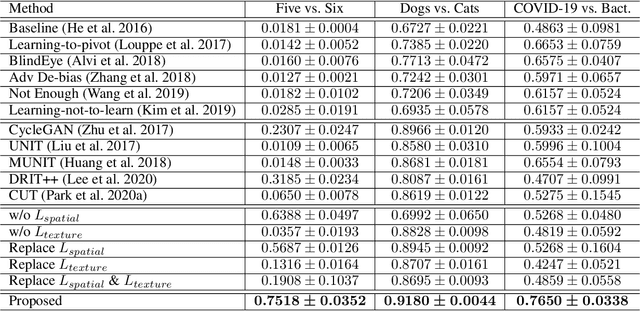
Classification models trained on biased datasets usually perform poorly on out-of-distribution samples since biased representations are embedded into the model. Recently, adversarial learning methods have been proposed to disentangle biased representations, but it is challenging to discard only the biased features without altering other relevant information. In this paper, we propose a novel de-biasing approach that explicitly generates additional images using texture representations of oppositely labeled images to enlarge the training dataset and mitigate the effect of biases when training a classifier. Every new generated image contains similar spatial information from a source image while transferring textures from a target image of opposite label. Our model integrates a texture co-occurrence loss that determines whether a generated image's texture is similar to that of the target, and a spatial self-similarity loss that determines whether the spatial details between the generated and source images are well preserved. Both generated and original training images are further used to train a classifier that is able to avoid learning unknown bias representations. We employ three distinct artificially designed datasets with known biases to demonstrate the ability of our method to mitigate bias information, and report competitive performance over existing state-of-the-art methods.
Mixing-AdaSIN: Constructing a de-biased dataset using Adaptive Structural Instance Normalization and texture Mixing
Mar 26, 2021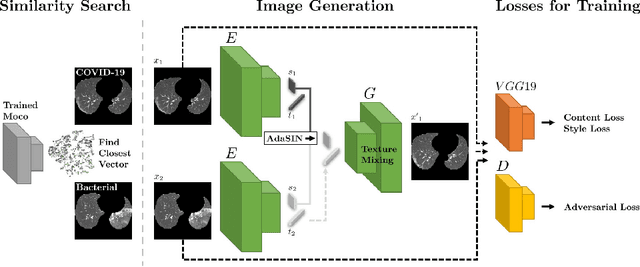
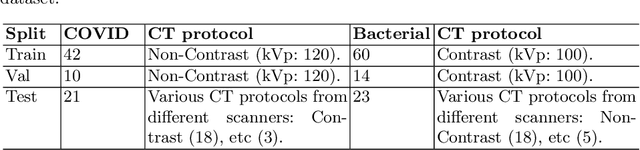
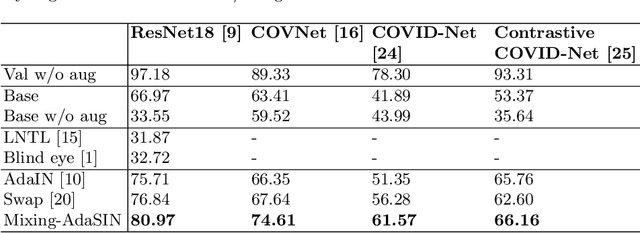
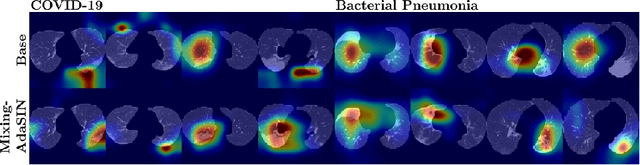
Following the pandemic outbreak, several works have proposed to diagnose COVID-19 with deep learning in computed tomography (CT); reporting performance on-par with experts. However, models trained/tested on the same in-distribution data may rely on the inherent data biases for successful prediction, failing to generalize on out-of-distribution samples or CT with different scanning protocols. Early attempts have partly addressed bias-mitigation and generalization through augmentation or re-sampling, but are still limited by collection costs and the difficulty of quantifying bias in medical images. In this work, we propose Mixing-AdaSIN; a bias mitigation method that uses a generative model to generate de-biased images by mixing texture information between different labeled CT scans with semantically similar features. Here, we use Adaptive Structural Instance Normalization (AdaSIN) to enhance de-biasing generation quality and guarantee structural consistency. Following, a classifier trained with the generated images learns to correctly predict the label without bias and generalizes better. To demonstrate the efficacy of our method, we construct a biased COVID-19 vs. bacterial pneumonia dataset based on CT protocols and compare with existing state-of-the-art de-biasing methods. Our experiments show that classifiers trained with de-biased generated images report improved in-distribution performance and generalization on an external COVID-19 dataset.
2018 Robotic Scene Segmentation Challenge
Feb 03, 2020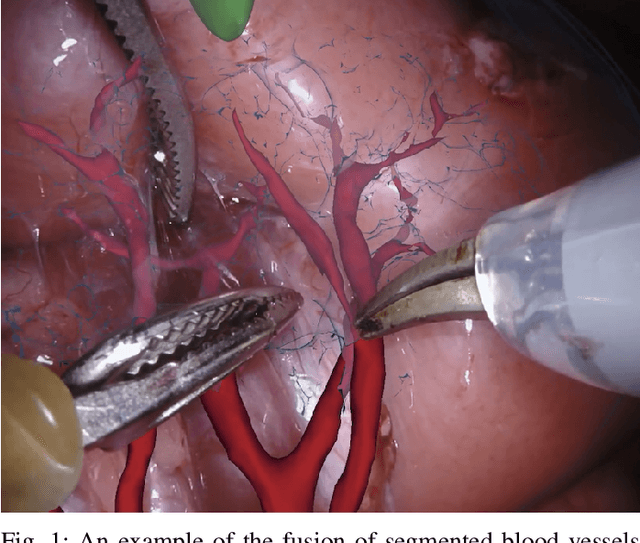
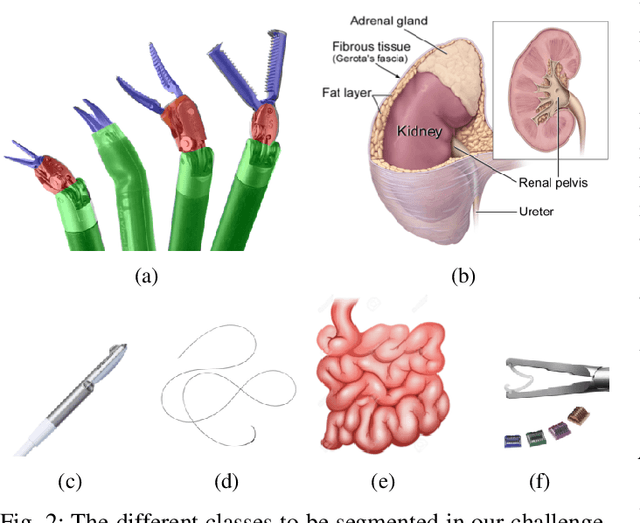
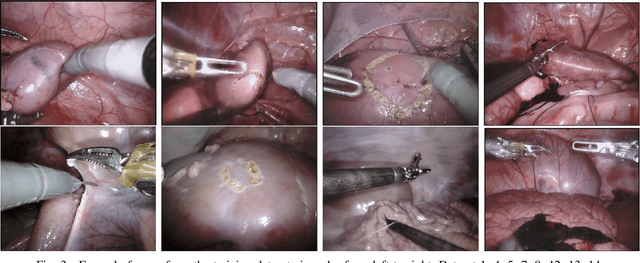
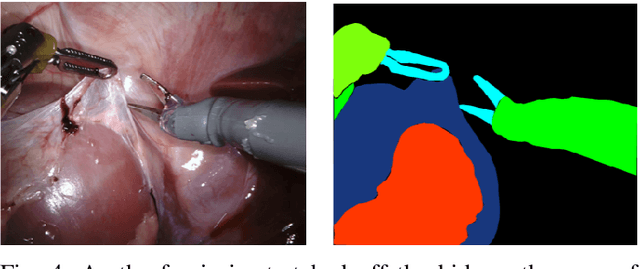
In 2015 we began a sub-challenge at the EndoVis workshop at MICCAI in Munich using endoscope images of ex-vivo tissue with automatically generated annotations from robot forward kinematics and instrument CAD models. However, the limited background variation and simple motion rendered the dataset uninformative in learning about which techniques would be suitable for segmentation in real surgery. In 2017, at the same workshop in Quebec we introduced the robotic instrument segmentation dataset with 10 teams participating in the challenge to perform binary, articulating parts and type segmentation of da Vinci instruments. This challenge included realistic instrument motion and more complex porcine tissue as background and was widely addressed with modifications on U-Nets and other popular CNN architectures. In 2018 we added to the complexity by introducing a set of anatomical objects and medical devices to the segmented classes. To avoid over-complicating the challenge, we continued with porcine data which is dramatically simpler than human tissue due to the lack of fatty tissue occluding many organs.
Standardized Assessment of Automatic Segmentation of White Matter Hyperintensities and Results of the WMH Segmentation Challenge
Apr 01, 2019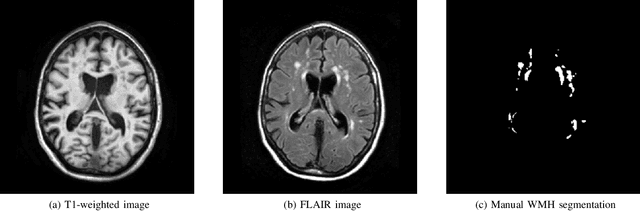
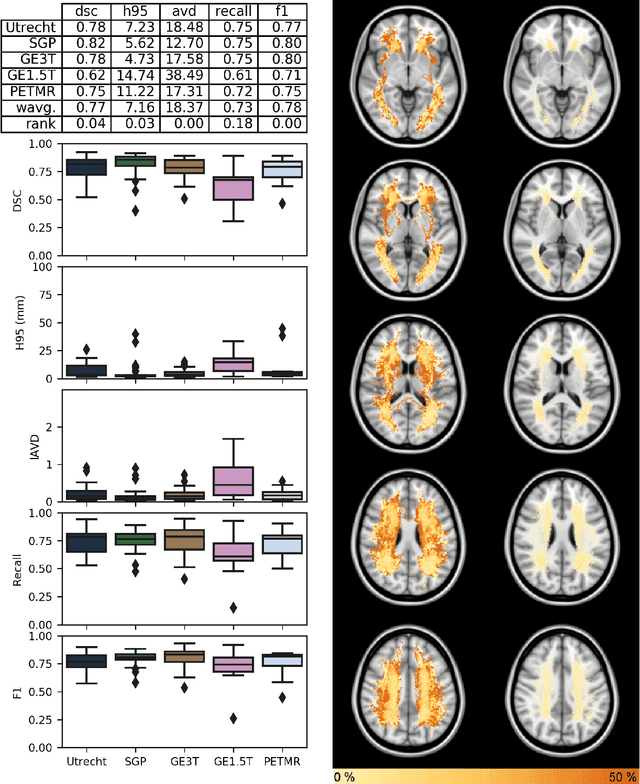
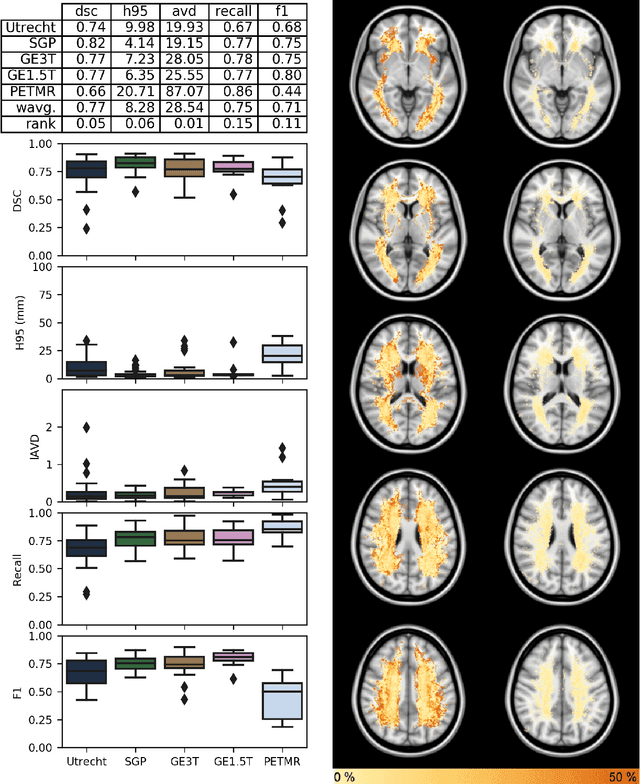
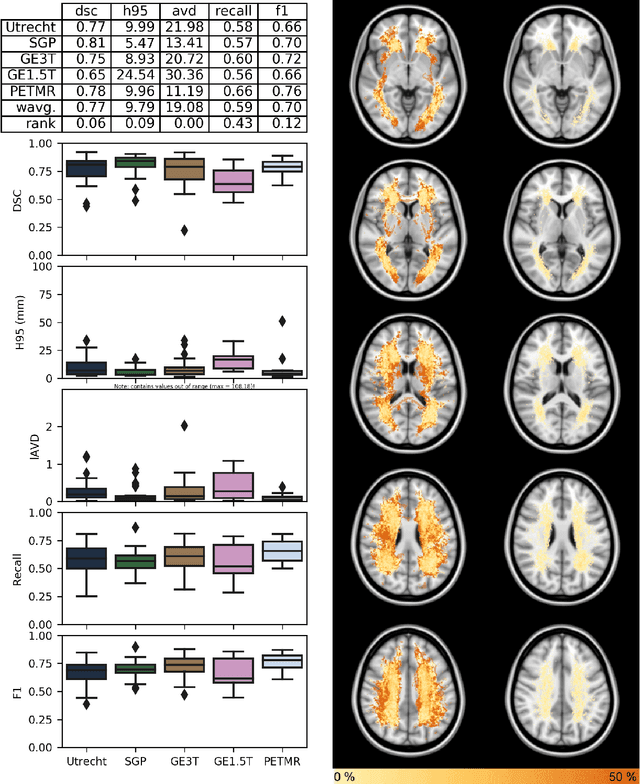
Quantification of cerebral white matter hyperintensities (WMH) of presumed vascular origin is of key importance in many neurological research studies. Currently, measurements are often still obtained from manual segmentations on brain MR images, which is a laborious procedure. Automatic WMH segmentation methods exist, but a standardized comparison of the performance of such methods is lacking. We organized a scientific challenge, in which developers could evaluate their method on a standardized multi-center/-scanner image dataset, giving an objective comparison: the WMH Segmentation Challenge (https://wmh.isi.uu.nl/). Sixty T1+FLAIR images from three MR scanners were released with manual WMH segmentations for training. A test set of 110 images from five MR scanners was used for evaluation. Segmentation methods had to be containerized and submitted to the challenge organizers. Five evaluation metrics were used to rank the methods: (1) Dice similarity coefficient, (2) modified Hausdorff distance (95th percentile), (3) absolute log-transformed volume difference, (4) sensitivity for detecting individual lesions, and (5) F1-score for individual lesions. Additionally, methods were ranked on their inter-scanner robustness. Twenty participants submitted their method for evaluation. This paper provides a detailed analysis of the results. In brief, there is a cluster of four methods that rank significantly better than the other methods, with one clear winner. The inter-scanner robustness ranking shows that not all methods generalize to unseen scanners. The challenge remains open for future submissions and provides a public platform for method evaluation.