 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixLacune: Segmentation of lacunes of presumed vascular origin
Aug 05, 2021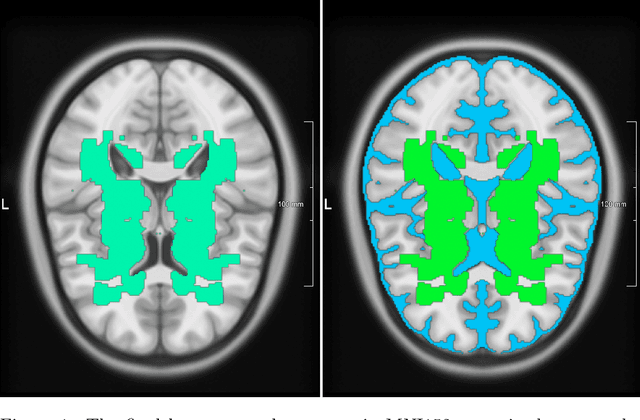
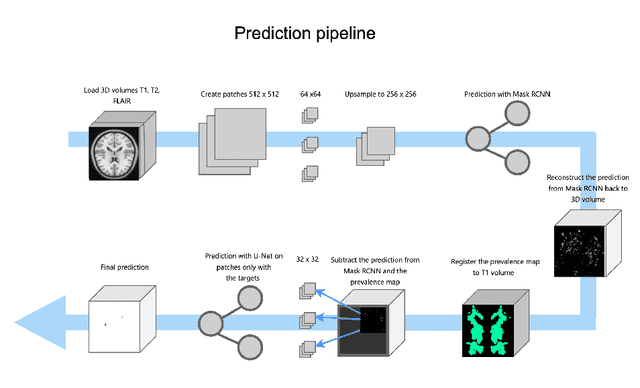
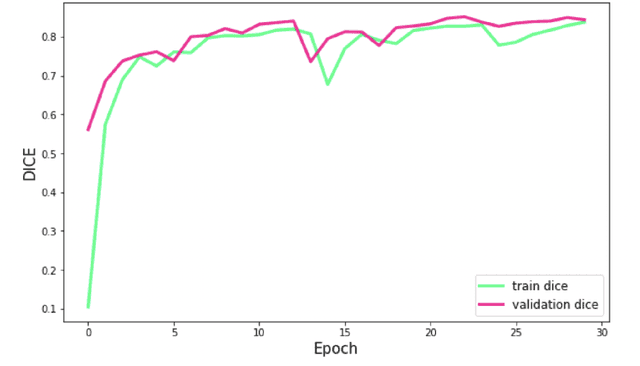
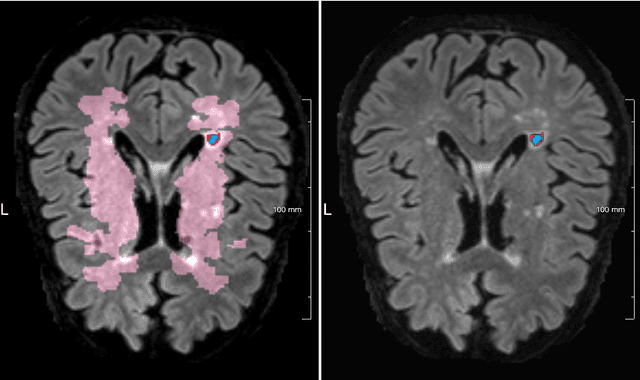
Lacunes of presumed vascular origin are fluid-filled cavities of between 3 - 15 mm in diameter, visible on T1 and FLAIR brain MRI. Quantification of lacunes relies on manual annotation or semi-automatic / interactive approaches; and almost no automatic methods exist for this task. In this work, we present a two-stage approach to segment lacunes of presumed vascular origin: (1) detection with Mask R-CNN followed by (2) segmentation with a U-Net CNN. Data originates from Task 3 of the "Where is VALDO?" challenge and consists of 40 training subjects. We report the mean DICE on the training set of 0.83 and on the validation set of 0.84. Source code is available at: https://github.com/hjkuijf/MixLacune . The docker container hjkuijf/mixlacune can be pulled from https://hub.docker.com/r/hjkuijf/mixlacune .
Standardized Assessment of Automatic Segmentation of White Matter Hyperintensities and Results of the WMH Segmentation Challenge
Apr 01, 2019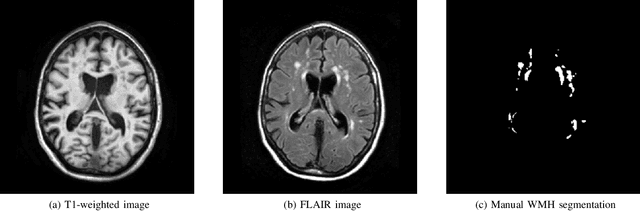
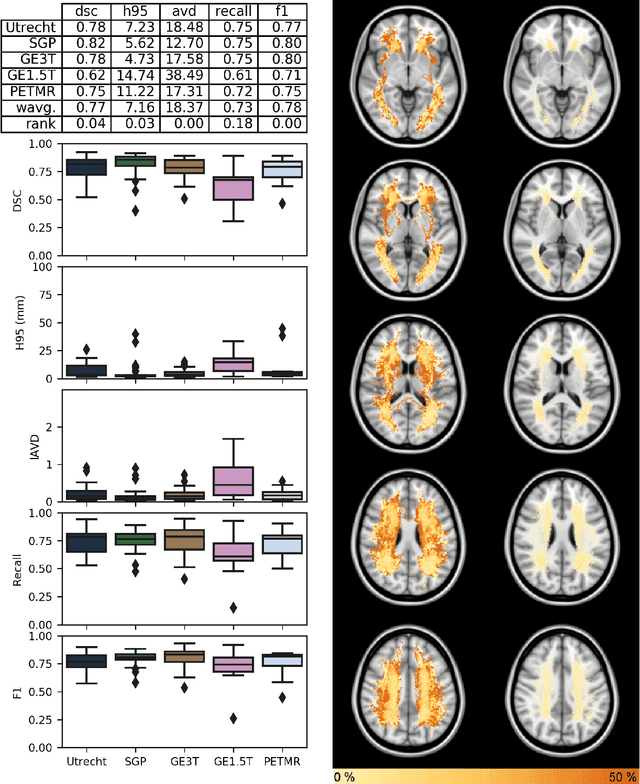
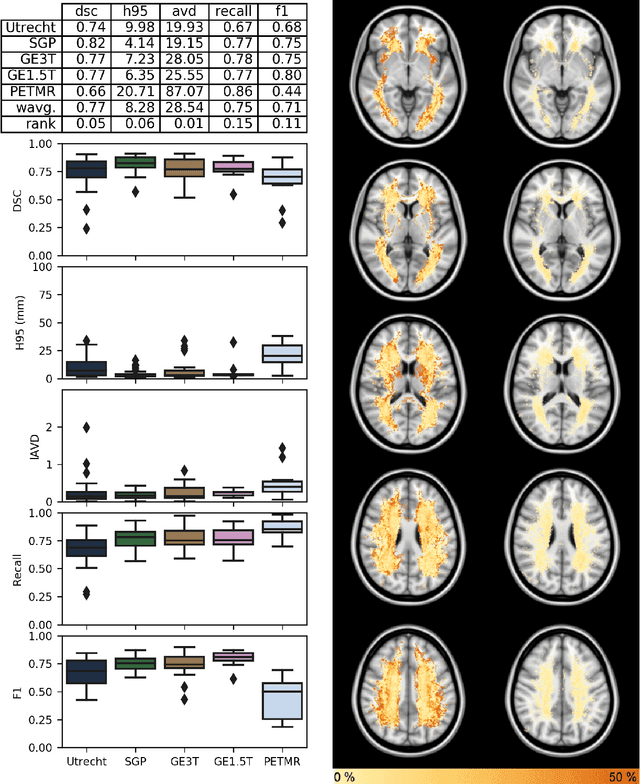
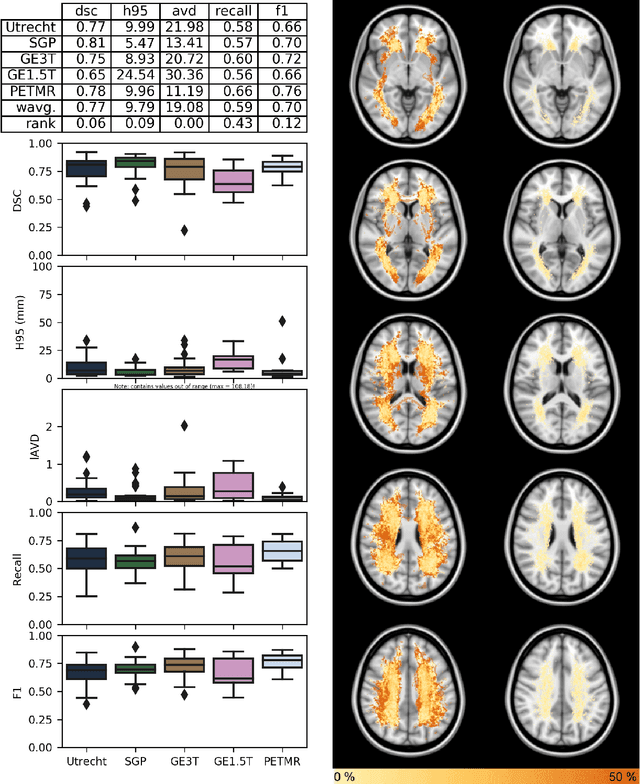
Quantification of cerebral white matter hyperintensities (WMH) of presumed vascular origin is of key importance in many neurological research studies. Currently, measurements are often still obtained from manual segmentations on brain MR images, which is a laborious procedure. Automatic WMH segmentation methods exist, but a standardized comparison of the performance of such methods is lacking. We organized a scientific challenge, in which developers could evaluate their method on a standardized multi-center/-scanner image dataset, giving an objective comparison: the WMH Segmentation Challenge (https://wmh.isi.uu.nl/). Sixty T1+FLAIR images from three MR scanners were released with manual WMH segmentations for training. A test set of 110 images from five MR scanners was used for evaluation. Segmentation methods had to be containerized and submitted to the challenge organizers. Five evaluation metrics were used to rank the methods: (1) Dice similarity coefficient, (2) modified Hausdorff distance (95th percentile), (3) absolute log-transformed volume difference, (4) sensitivity for detecting individual lesions, and (5) F1-score for individual lesions. Additionally, methods were ranked on their inter-scanner robustness. Twenty participants submitted their method for evaluation. This paper provides a detailed analysis of the results. In brief, there is a cluster of four methods that rank significantly better than the other methods, with one clear winner. The inter-scanner robustness ranking shows that not all methods generalize to unseen scanners. The challenge remains open for future submissions and provides a public platform for method evaluation.