 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStress-testing Machine Generated Text Detection: Shifting Language Models Writing Style to Fool Detectors
May 30, 2025Recent advancements in Generative AI and Large Language Models (LLMs) have enabled the creation of highly realistic synthetic content, raising concerns about the potential for malicious use, such as misinformation and manipulation. Moreover, detecting Machine-Generated Text (MGT) remains challenging due to the lack of robust benchmarks that assess generalization to real-world scenarios. In this work, we present a pipeline to test the resilience of state-of-the-art MGT detectors (e.g., Mage, Radar, LLM-DetectAIve) to linguistically informed adversarial attacks. To challenge the detectors, we fine-tune language models using Direct Preference Optimization (DPO) to shift the MGT style toward human-written text (HWT). This exploits the detectors' reliance on stylistic clues, making new generations more challenging to detect. Additionally, we analyze the linguistic shifts induced by the alignment and which features are used by detectors to detect MGT texts. Our results show that detectors can be easily fooled with relatively few examples, resulting in a significant drop in detection performance. This highlights the importance of improving detection methods and making them robust to unseen in-domain texts.
Optimizing LLMs for Italian: Reducing Token Fertility and Enhancing Efficiency Through Vocabulary Adaptation
Apr 23, 2025The number of pretrained Large Language Models (LLMs) is increasing steadily, though the majority are designed predominantly for the English language. While state-of-the-art LLMs can handle other languages, due to language contamination or some degree of multilingual pretraining data, they are not optimized for non-English languages, leading to inefficient encoding (high token "fertility") and slower inference speed. In this work, we thoroughly compare a variety of vocabulary adaptation techniques for optimizing English LLMs for the Italian language, and put forward Semantic Alignment Vocabulary Adaptation (SAVA), a novel method that leverages neural mapping for vocabulary substitution. SAVA achieves competitive performance across multiple downstream tasks, enhancing grounded alignment strategies. We adapt two LLMs: Mistral-7b-v0.1, reducing token fertility by 25\%, and Llama-3.1-8B, optimizing the vocabulary and reducing the number of parameters by 1 billion. We show that, following the adaptation of the vocabulary, these models can recover their performance with a relatively limited stage of continual training on the target language. Finally, we test the capabilities of the adapted models on various multi-choice and generative tasks.
Contextualized Counterspeech: Strategies for Adaptation, Personalization, and Evaluation
Dec 10, 2024
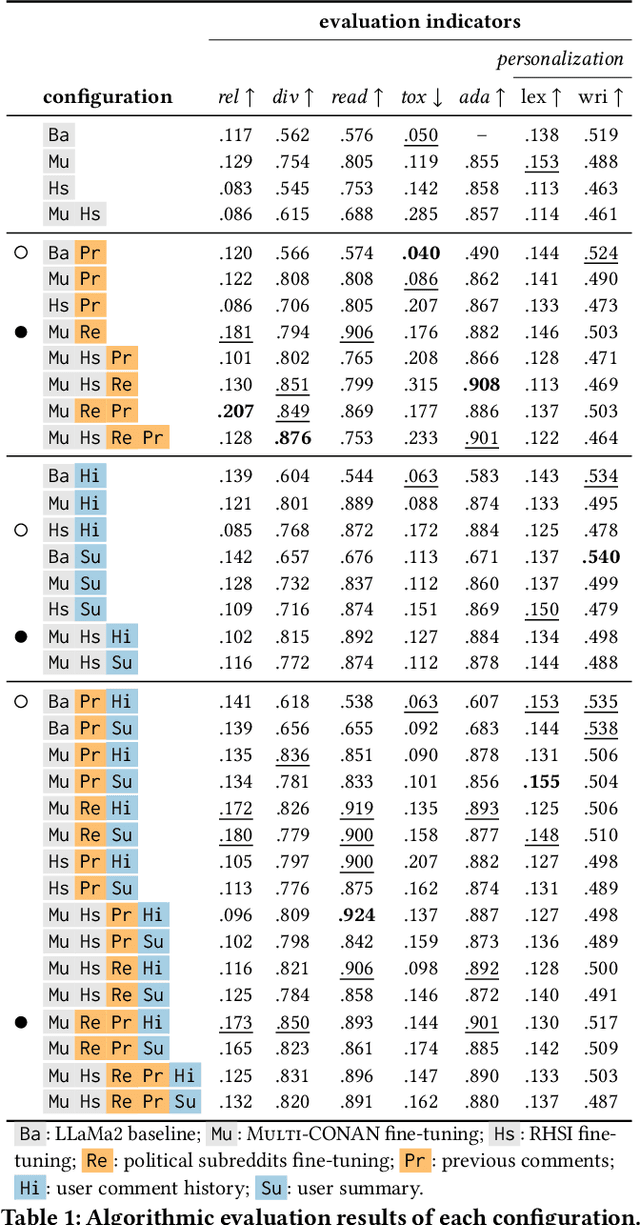
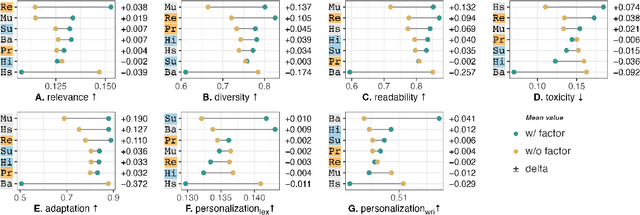

AI-generated counterspeech offers a promising and scalable strategy to curb online toxicity through direct replies that promote civil discourse. However, current counterspeech is one-size-fits-all, lacking adaptation to the moderation context and the users involved. We propose and evaluate multiple strategies for generating tailored counterspeech that is adapted to the moderation context and personalized for the moderated user. We instruct an LLaMA2-13B model to generate counterspeech, experimenting with various configurations based on different contextual information and fine-tuning strategies. We identify the configurations that generate persuasive counterspeech through a combination of quantitative indicators and human evaluations collected via a pre-registered mixed-design crowdsourcing experiment. Results show that contextualized counterspeech can significantly outperform state-of-the-art generic counterspeech in adequacy and persuasiveness, without compromising other characteristics. Our findings also reveal a poor correlation between quantitative indicators and human evaluations, suggesting that these methods assess different aspects and highlighting the need for nuanced evaluation methodologies. The effectiveness of contextualized AI-generated counterspeech and the divergence between human and algorithmic evaluations underscore the importance of increased human-AI collaboration in content moderation.
Leveraging Large Language Models for Mobile App Review Feature Extraction
Aug 02, 2024
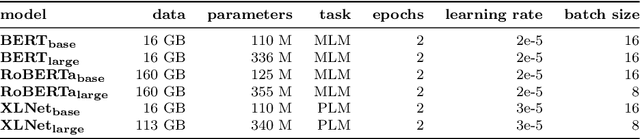

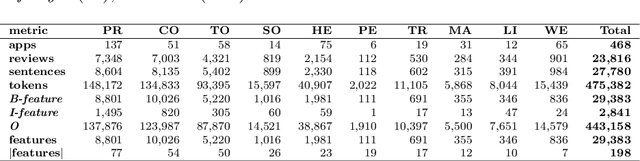
Mobile app review analysis presents unique challenges due to the low quality, subjective bias, and noisy content of user-generated documents. Extracting features from these reviews is essential for tasks such as feature prioritization and sentiment analysis, but it remains a challenging task. Meanwhile, encoder-only models based on the Transformer architecture have shown promising results for classification and information extraction tasks for multiple software engineering processes. This study explores the hypothesis that encoder-only large language models can enhance feature extraction from mobile app reviews. By leveraging crowdsourced annotations from an industrial context, we redefine feature extraction as a supervised token classification task. Our approach includes extending the pre-training of these models with a large corpus of user reviews to improve contextual understanding and employing instance selection techniques to optimize model fine-tuning. Empirical evaluations demonstrate that this method improves the precision and recall of extracted features and enhances performance efficiency. Key contributions include a novel approach to feature extraction, annotated datasets, extended pre-trained models, and an instance selection mechanism for cost-effective fine-tuning. This research provides practical methods and empirical evidence in applying large language models to natural language processing tasks within mobile app reviews, offering improved performance in feature extraction.
AI "News" Content Farms Are Easy to Make and Hard to Detect: A Case Study in Italian
Jun 17, 2024Large Language Models (LLMs) are increasingly used as "content farm" models (CFMs), to generate synthetic text that could pass for real news articles. This is already happening even for languages that do not have high-quality monolingual LLMs. We show that fine-tuning Llama (v1), mostly trained on English, on as little as 40K Italian news articles, is sufficient for producing news-like texts that native speakers of Italian struggle to identify as synthetic. We investigate three LLMs and three methods of detecting synthetic texts (log-likelihood, DetectGPT, and supervised classification), finding that they all perform better than human raters, but they are all impractical in the real world (requiring either access to token likelihood information or a large dataset of CFM texts). We also explore the possibility of creating a proxy CFM: an LLM fine-tuned on a similar dataset to one used by the real "content farm". We find that even a small amount of fine-tuning data suffices for creating a successful detector, but we need to know which base LLM is used, which is a major challenge. Our results suggest that there are currently no practical methods for detecting synthetic news-like texts 'in the wild', while generating them is too easy. We highlight the urgency of more NLP research on this problem.
Fine-tuning with HED-IT: The impact of human post-editing for dialogical language models
Jun 11, 2024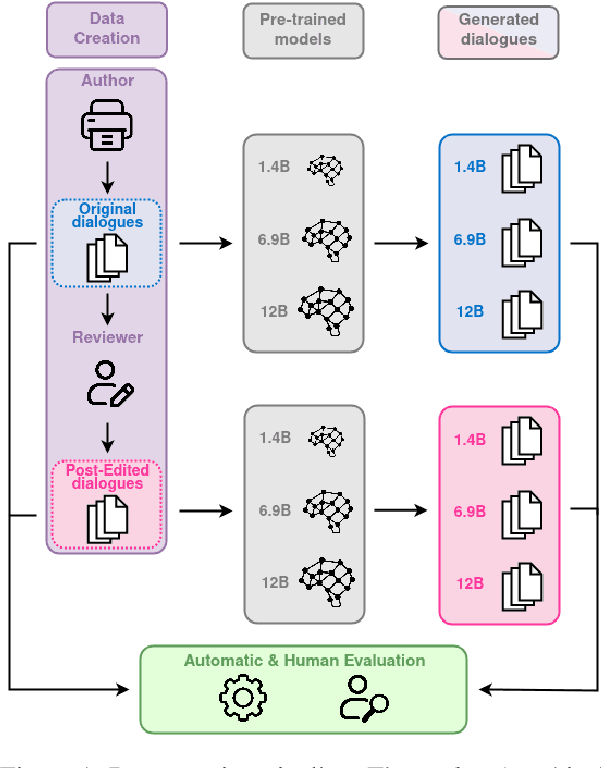

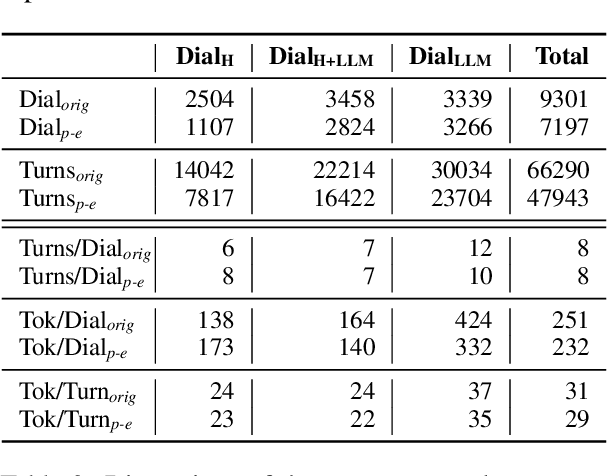

Automatic methods for generating and gathering linguistic data have proven effective for fine-tuning Language Models (LMs) in languages less resourced than English. Still, while there has been emphasis on data quantity, less attention has been given to its quality. In this work, we investigate the impact of human intervention on machine-generated data when fine-tuning dialogical models. In particular, we study (1) whether post-edited dialogues exhibit higher perceived quality compared to the originals that were automatically generated; (2) whether fine-tuning with post-edited dialogues results in noticeable differences in the generated outputs; and (3) whether post-edited dialogues influence the outcomes when considering the parameter size of the LMs. To this end we created HED-IT, a large-scale dataset where machine-generated dialogues are paired with the version post-edited by humans. Using both the edited and unedited portions of HED-IT, we fine-tuned three different sizes of an LM. Results from both human and automatic evaluation show that the different quality of training data is clearly perceived and it has an impact also on the models trained on such data. Additionally, our findings indicate that larger models are less sensitive to data quality, whereas this has a crucial impact on smaller models. These results enhance our comprehension of the impact of human intervention on training data in the development of high-quality LMs.
Linguistic Knowledge Can Enhance Encoder-Decoder Models (If You Let It)
Feb 27, 2024
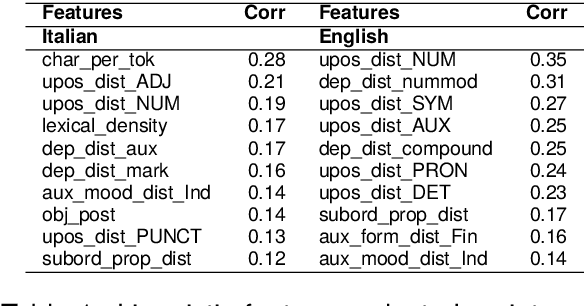
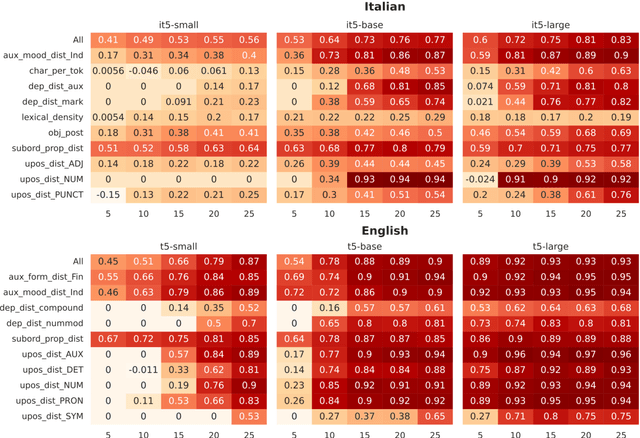
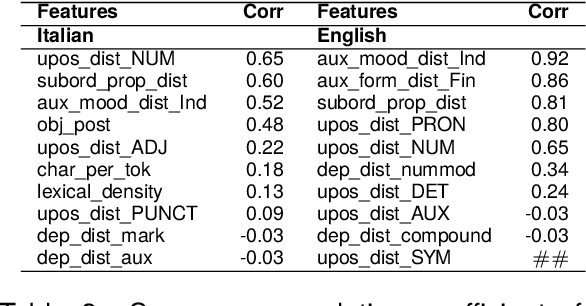
In this paper, we explore the impact of augmenting pre-trained Encoder-Decoder models, specifically T5, with linguistic knowledge for the prediction of a target task. In particular, we investigate whether fine-tuning a T5 model on an intermediate task that predicts structural linguistic properties of sentences modifies its performance in the target task of predicting sentence-level complexity. Our study encompasses diverse experiments conducted on Italian and English datasets, employing both monolingual and multilingual T5 models at various sizes. Results obtained for both languages and in cross-lingual configurations show that linguistically motivated intermediate fine-tuning has generally a positive impact on target task performance, especially when applied to smaller models and in scenarios with limited data availability.
Outliers Dimensions that Disrupt Transformers Are Driven by Frequency
May 23, 2022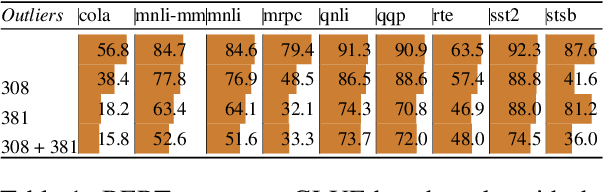
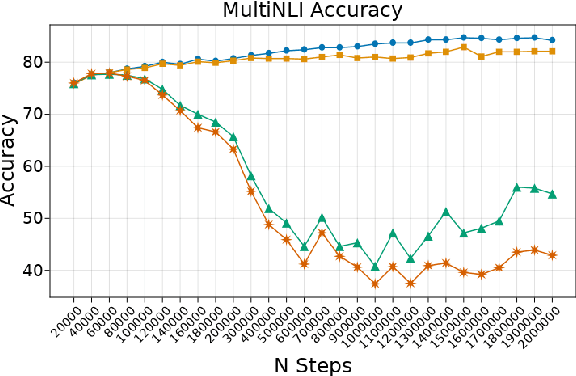
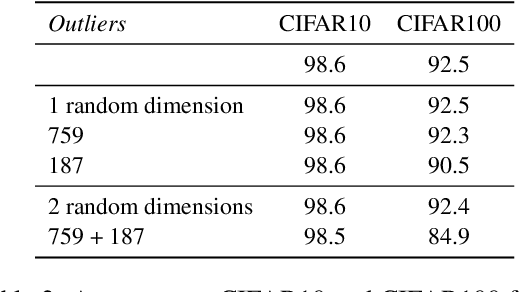
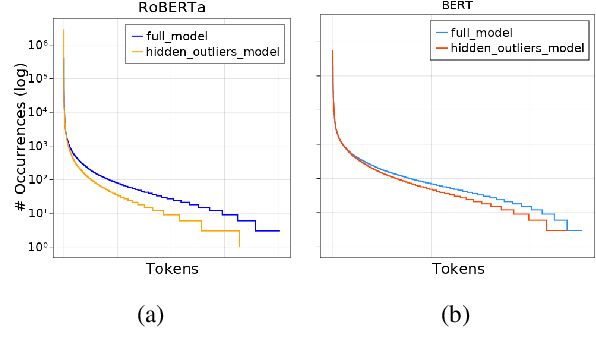
Transformer-based language models are known to display anisotropic behavior: the token embeddings are not homogeneously spread in space, but rather accumulate along certain directions. A related recent finding is the outlier phenomenon: the parameters in the final element of Transformer layers that consistently have unusual magnitude in the same dimension across the model, and significantly degrade its performance if disabled. We replicate the evidence for the outlier phenomenon and we link it to the geometry of the embedding space. Our main finding is that in both BERT and RoBERTa the token frequency, known to contribute to anisotropicity, also contributes to the outlier phenomenon. In its turn, the outlier phenomenon contributes to the "vertical" self-attention pattern that enables the model to focus on the special tokens. We also find that, surprisingly, the outlier effect on the model performance varies by layer, and that variance is also related to the correlation between outlier magnitude and encoded token frequency.
On the interaction of automatic evaluation and task framing in headline style transfer
Jan 05, 2021

An ongoing debate in the NLG community concerns the best way to evaluate systems, with human evaluation often being considered the most reliable method, compared to corpus-based metrics. However, tasks involving subtle textual differences, such as style transfer, tend to be hard for humans to perform. In this paper, we propose an evaluation method for this task based on purposely-trained classifiers, showing that it better reflects system differences than traditional metrics such as BLEU and ROUGE.
Linguistic Profiling of a Neural Language Model
Oct 30, 2020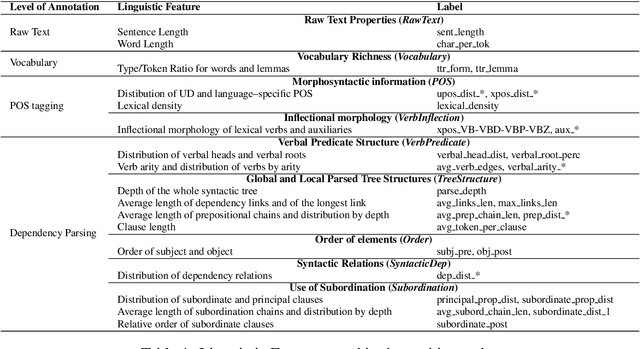
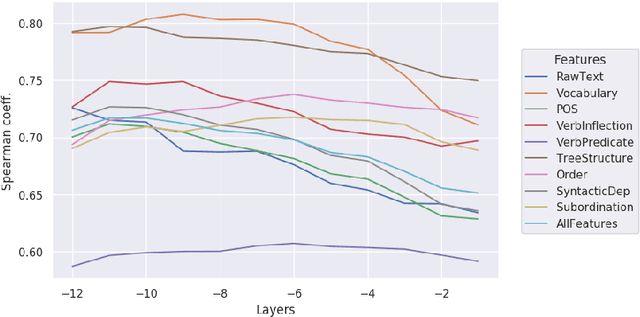

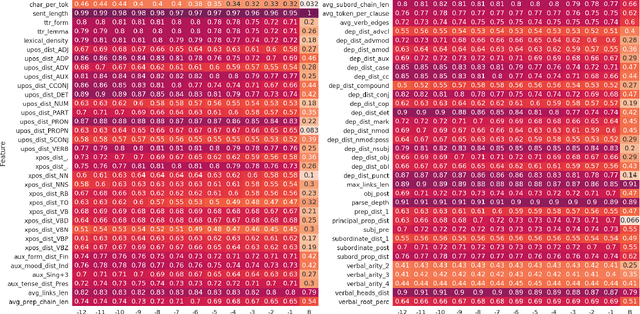
In this paper we investigate the linguistic knowledge learned by a Neural Language Model (NLM) before and after a fine-tuning process and how this knowledge affects its predictions during several classification problems. We use a wide set of probing tasks, each of which corresponds to a distinct sentence-level feature extracted from different levels of linguistic annotation. We show that BERT is able to encode a wide range of linguistic characteristics, but it tends to lose this information when trained on specific downstream tasks. We also find that BERT's capacity to encode different kind of linguistic properties has a positive influence on its predictions: the more it stores readable linguistic information, the higher will be its capacity of predicting the correct label.