 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the interaction of automatic evaluation and task framing in headline style transfer
Jan 05, 2021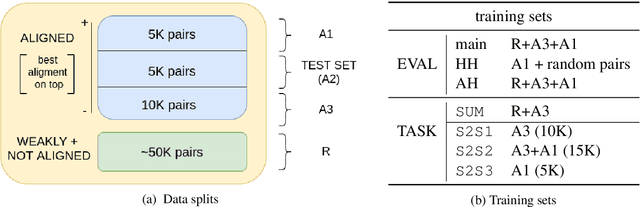

An ongoing debate in the NLG community concerns the best way to evaluate systems, with human evaluation often being considered the most reliable method, compared to corpus-based metrics. However, tasks involving subtle textual differences, such as style transfer, tend to be hard for humans to perform. In this paper, we propose an evaluation method for this task based on purposely-trained classifiers, showing that it better reflects system differences than traditional metrics such as BLEU and ROUGE.
GePpeTto Carves Italian into a Language Model
Apr 29, 2020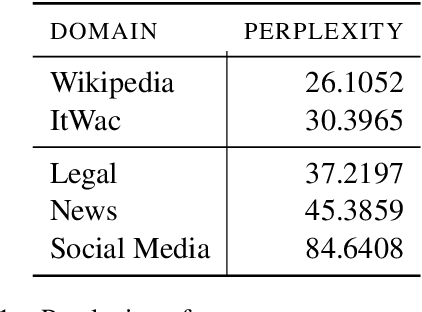
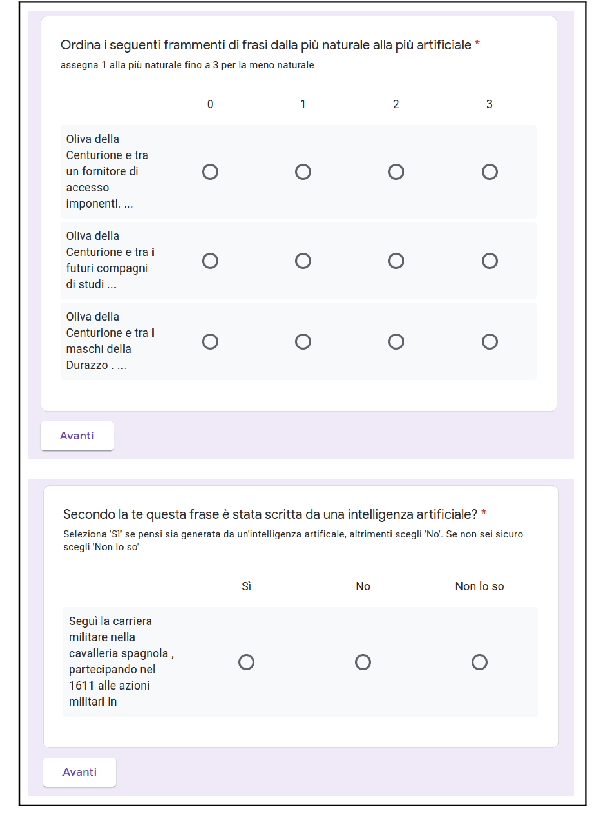
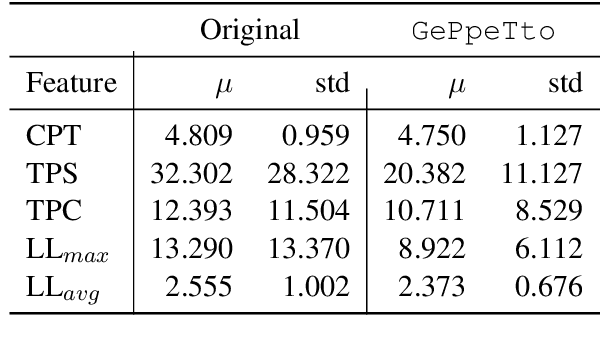

In the last few years, pre-trained neural architectures have provided impressive improvements across several NLP tasks. Still, generative language models are available mainly for English. We develop GePpeTto, the first generative language model for Italian, built using the GPT-2 architecture. We provide a thorough analysis of GePpeTto's quality by means of both an automatic and a human-based evaluation. The automatic assessment consists in (i) calculating perplexity across different genres and (ii) a profiling analysis over GePpeTto's writing characteristics. We find that GePpeTto's production is a sort of bonsai version of human production, with shorter but yet complex sentences. Human evaluation is performed over a sentence completion task, where GePpeTto's output is judged as natural more often than not, and much closer to the original human texts than to a simpler language model which we take as baseline.