 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Impairment: Leveraging Insights from Clinical Linguistics in Language Modelling Research
Dec 20, 2024This position paper investigates the potential of integrating insights from language impairment research and its clinical treatment to develop human-inspired learning strategies and evaluation frameworks for language models (LMs). We inspect the theoretical underpinnings underlying some influential linguistically motivated training approaches derived from neurolinguistics and, particularly, aphasiology, aimed at enhancing the recovery and generalization of linguistic skills in aphasia treatment, with a primary focus on those targeting the syntactic domain. We highlight how these insights can inform the design of rigorous assessments for LMs, specifically in their handling of complex syntactic phenomena, as well as their implications for developing human-like learning strategies, aligning with efforts to create more sustainable and cognitively plausible natural language processing (NLP) models.
Linguistic Profiling of a Neural Language Model
Oct 30, 2020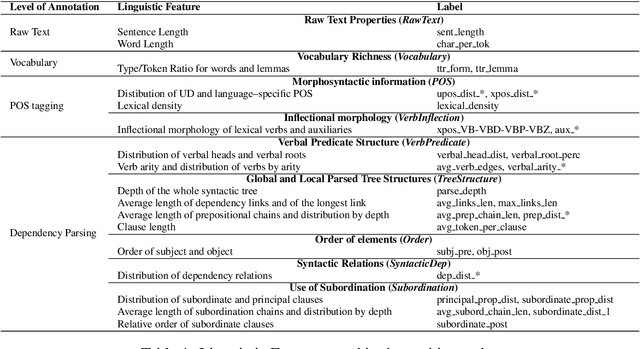
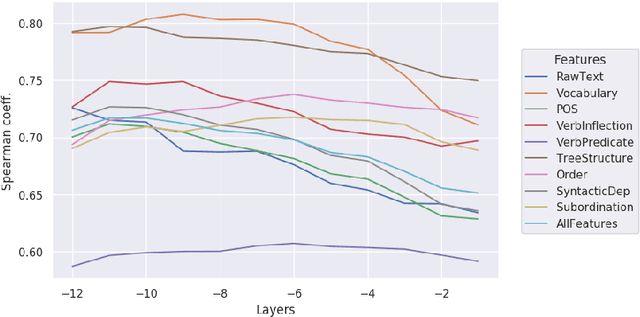

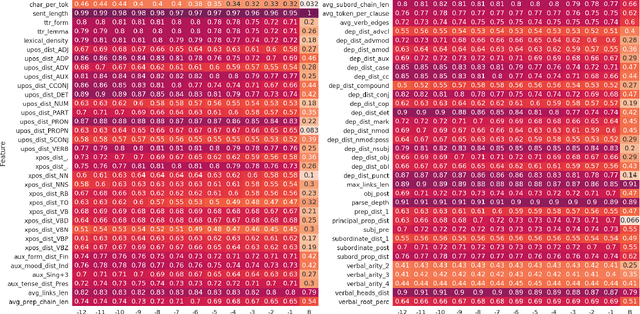
In this paper we investigate the linguistic knowledge learned by a Neural Language Model (NLM) before and after a fine-tuning process and how this knowledge affects its predictions during several classification problems. We use a wide set of probing tasks, each of which corresponds to a distinct sentence-level feature extracted from different levels of linguistic annotation. We show that BERT is able to encode a wide range of linguistic characteristics, but it tends to lose this information when trained on specific downstream tasks. We also find that BERT's capacity to encode different kind of linguistic properties has a positive influence on its predictions: the more it stores readable linguistic information, the higher will be its capacity of predicting the correct label.