 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistic Knowledge Can Enhance Encoder-Decoder Models (If You Let It)
Feb 27, 2024
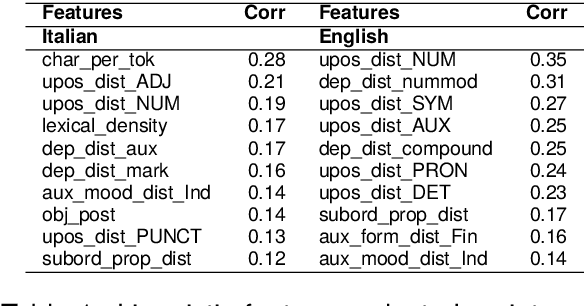
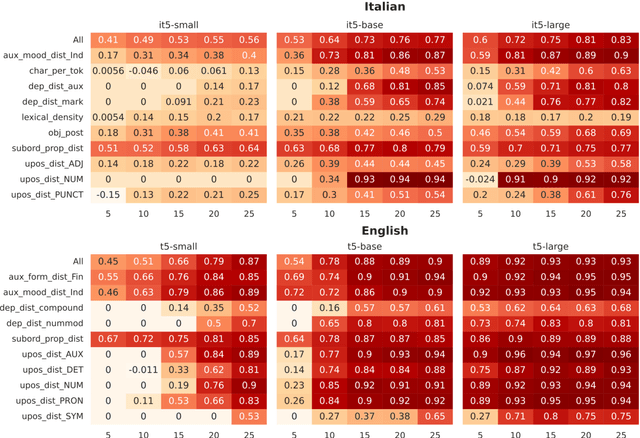
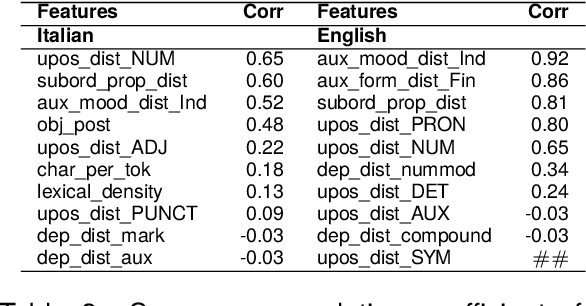
In this paper, we explore the impact of augmenting pre-trained Encoder-Decoder models, specifically T5, with linguistic knowledge for the prediction of a target task. In particular, we investigate whether fine-tuning a T5 model on an intermediate task that predicts structural linguistic properties of sentences modifies its performance in the target task of predicting sentence-level complexity. Our study encompasses diverse experiments conducted on Italian and English datasets, employing both monolingual and multilingual T5 models at various sizes. Results obtained for both languages and in cross-lingual configurations show that linguistically motivated intermediate fine-tuning has generally a positive impact on target task performance, especially when applied to smaller models and in scenarios with limited data availability.
Linguistic Profiling of a Neural Language Model
Oct 30, 2020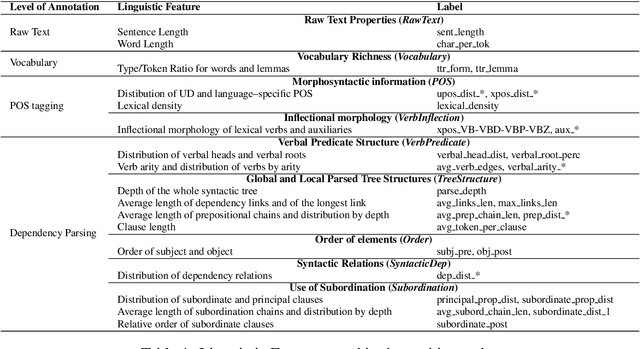
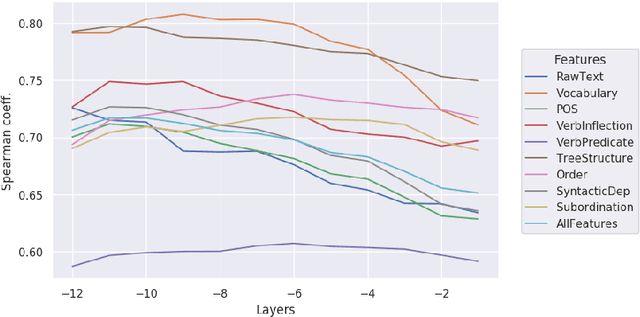

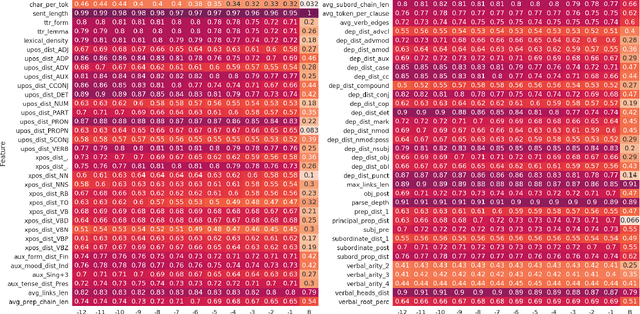
In this paper we investigate the linguistic knowledge learned by a Neural Language Model (NLM) before and after a fine-tuning process and how this knowledge affects its predictions during several classification problems. We use a wide set of probing tasks, each of which corresponds to a distinct sentence-level feature extracted from different levels of linguistic annotation. We show that BERT is able to encode a wide range of linguistic characteristics, but it tends to lose this information when trained on specific downstream tasks. We also find that BERT's capacity to encode different kind of linguistic properties has a positive influence on its predictions: the more it stores readable linguistic information, the higher will be its capacity of predicting the correct label.