 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgehunt
Papers and Code
Hunt Instead of Wait: Evaluating Deep Data Research on Large Language Models
Feb 02, 2026The agency expected of Agentic Large Language Models goes beyond answering correctly, requiring autonomy to set goals and decide what to explore. We term this investigatory intelligence, distinguishing it from executional intelligence, which merely completes assigned tasks. Data Science provides a natural testbed, as real-world analysis starts from raw data rather than explicit queries, yet few benchmarks focus on it. To address this, we introduce Deep Data Research (DDR), an open-ended task where LLMs autonomously extract key insights from databases, and DDR-Bench, a large-scale, checklist-based benchmark that enables verifiable evaluation. Results show that while frontier models display emerging agency, long-horizon exploration remains challenging. Our analysis highlights that effective investigatory intelligence depends not only on agent scaffolding or merely scaling, but also on intrinsic strategies of agentic models.
Emergent Cooperation in Quantum Multi-Agent Reinforcement Learning Using Communication
Jan 26, 2026Emergent cooperation in classical Multi-Agent Reinforcement Learning has gained significant attention, particularly in the context of Sequential Social Dilemmas (SSDs). While classical reinforcement learning approaches have demonstrated capability for emergent cooperation, research on extending these methods to Quantum Multi-Agent Reinforcement Learning remains limited, particularly through communication. In this paper, we apply communication approaches to quantum Q-Learning agents: the Mutual Acknowledgment Token Exchange (MATE) protocol, its extension Mutually Endorsed Distributed Incentive Acknowledgment Token Exchange (MEDIATE), the peer rewarding mechanism Gifting, and Reinforced Inter-Agent Learning (RIAL). We evaluate these approaches in three SSDs: the Iterated Prisoner's Dilemma, Iterated Stag Hunt, and Iterated Game of Chicken. Our experimental results show that approaches using MATE with temporal-difference measure (MATE\textsubscript{TD}), AutoMATE, MEDIATE-I, and MEDIATE-S achieved high cooperation levels across all dilemmas, demonstrating that communication is a viable mechanism for fostering emergent cooperation in Quantum Multi-Agent Reinforcement Learning.
Information Farming: From Berry Picking to Berry Growing
Jan 18, 2026The classic paradigms of Berry Picking and Information Foraging Theory have framed users as gatherers, opportunistically searching across distributed sources to satisfy evolving information needs. However, the rise of GenAI is driving a fundamental transformation in how people produce, structure, and reuse information - one that these paradigms no longer fully capture. This transformation is analogous to the Neolithic Revolution, when societies shifted from hunting and gathering to cultivation. Generative technologies empower users to "farm" information by planting seeds in the form of prompts, cultivating workflows over time, and harvesting richly structured, relevant yields within their own plots, rather than foraging across others people's patches. In this perspectives paper, we introduce the notion of Information Farming as a conceptual framework and argue that it represents a natural evolution in how people engage with information. Drawing on historical analogy and empirical evidence, we examine the benefits and opportunities of information farming, its implications for design and evaluation, and the accompanying risks posed by this transition. We hypothesize that as GenAI technologies proliferate, cultivating information will increasingly supplant transient, patch-based foraging as a dominant mode of engagement, marking a broader shift in human-information interaction and its study.
* ACM CHIIR 2026
XAI-MeD: Explainable Knowledge Guided Neuro-Symbolic Framework for Domain Generalization and Rare Class Detection in Medical Imaging
Jan 05, 2026Explainability domain generalization and rare class reliability are critical challenges in medical AI where deep models often fail under real world distribution shifts and exhibit bias against infrequent clinical conditions This paper introduces XAIMeD an explainable medical AI framework that integrates clinically accurate expert knowledge into deep learning through a unified neuro symbolic architecture XAIMeD is designed to improve robustness under distribution shift enhance rare class sensitivity and deliver transparent clinically aligned interpretations The framework encodes clinical expertise as logical connectives over atomic medical propositions transforming them into machine checkable class specific rules Their diagnostic utility is quantified through weighted feature satisfaction scores enabling a symbolic reasoning branch that complements neural predictions A confidence weighted fusion integrates symbolic and deep outputs while a Hunt inspired adaptive routing mechanism guided by Entropy Imbalance Gain EIG and Rare Class Gini mitigates class imbalance high intra class variability and uncertainty We evaluate XAIMeD across diverse modalities on four challenging tasks i Seizure Onset Zone SOZ localization from rs fMRI ii Diabetic Retinopathy grading across 6 multicenter datasets demonstrate substantial performance improvements including 6 percent gains in cross domain generalization and a 10 percent improved rare class F1 score far outperforming state of the art deep learning baselines Ablation studies confirm that the clinically grounded symbolic components act as effective regularizers ensuring robustness to distribution shifts XAIMeD thus provides a principled clinically faithful and interpretable approach to multimodal medical AI.
Hunting for "Oddballs" with Machine Learning: Detecting Anomalous Exoplanets Using a Deep-Learned Low-Dimensional Representation of Transit Spectra with Autoencoders
Jan 05, 2026This study explores the application of autoencoder-based machine learning techniques for anomaly detection to identify exoplanet atmospheres with unconventional chemical signatures using a low-dimensional data representation. We use the Atmospheric Big Challenge (ABC) database, a publicly available dataset with over 100,000 simulated exoplanet spectra, to construct an anomaly detection scenario by defining CO2-rich atmospheres as anomalies and CO2-poor atmospheres as the normal class. We benchmarked four different anomaly detection strategies: Autoencoder Reconstruction Loss, One-Class Support Vector Machine (1 class-SVM), K-means Clustering, and Local Outlier Factor (LOF). Each method was evaluated in both the original spectral space and the autoencoder's latent space using Receiver Operating Characteristic (ROC) curves and Area Under the Curve (AUC) metrics. To test the performance of the different methods under realistic conditions, we introduced Gaussian noise levels ranging from 10 to 50 ppm. Our results indicate that anomaly detection is consistently more effective when performed within the latent space across all noise levels. Specifically, K-means clustering in the latent space emerged as a stable and high-performing method. We demonstrate that this anomaly detection approach is robust to noise levels up to 30 ppm (consistent with realistic space-based observations) and remains viable even at 50 ppm when leveraging latent space representations. On the other hand, the performance of the anomaly detection methods applied directly in the raw spectral space degrades significantly with increasing the level of noise. This suggests that autoencoder-driven dimensionality reduction offers a robust methodology for flagging chemically anomalous targets in large-scale surveys where exhaustive retrievals are computationally prohibitive.
The Discovery Gap: How Product Hunt Startups Vanish in LLM Organic Discovery Queries
Jan 01, 2026When someone asks ChatGPT to recommend a project management tool, which products show up in the response? And more importantly for startup founders: will their newly launched product ever appear? This research set out to answer these questions. I randomly selected 112 startups from the top 500 products featured on the 2025 Product Hunt leaderboard and tested each one across 2,240 queries to two different large language models: ChatGPT (gpt-4o-mini) and Perplexity (sonar with web search). The results were striking. When users asked about products by name, both LLMs recognized them almost perfectly: 99.4% for ChatGPT and 94.3% for Perplexity. But when users asked discovery-style questions like "What are the best AI tools launched this year?" the success rates collapsed to 3.32% and 8.29% respectively. That's a gap of 30-to-1 for ChatGPT. Perhaps the most surprising finding was that Generative Engine Optimization (GEO), the practice of optimizing website content for AI visibility, showed no correlation with actual discovery rates. Products with high GEO scores were no more likely to appear in organic queries than products with low scores. What did matter? For Perplexity, traditional SEO signals like referring domains (r = +0.319, p < 0.001) and Product Hunt ranking (r = -0.286, p = 0.002) predicted visibility. After cleaning the Reddit data for false positives, community presence also emerged as significant (r = +0.395, p = 0.002). The practical takeaway is counterintuitive: don't optimize for AI discovery directly. Instead, build the SEO foundation first and LLM visibility will follow.
HeadHunt-VAD: Hunting Robust Anomaly-Sensitive Heads in MLLM for Tuning-Free Video Anomaly Detection
Dec 23, 2025
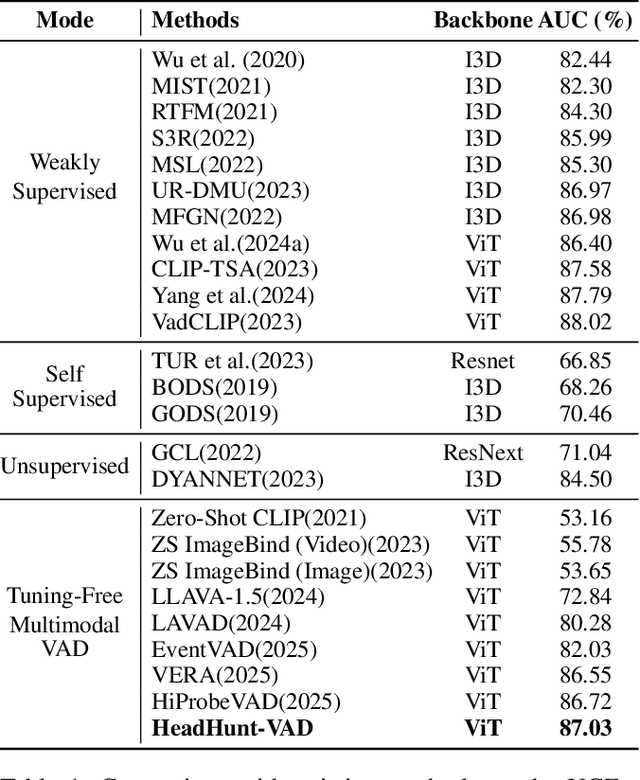
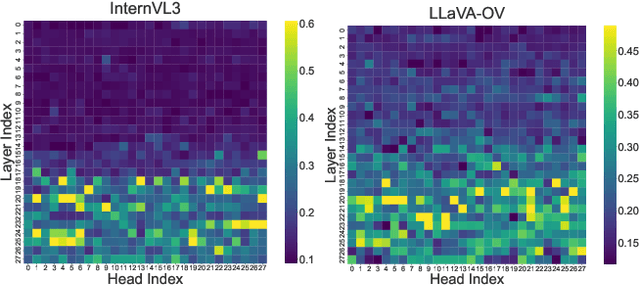
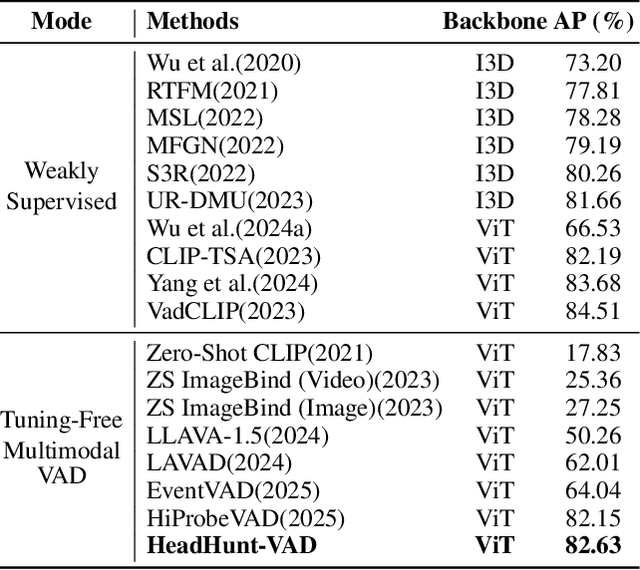
Video Anomaly Detection (VAD) aims to locate events that deviate from normal patterns in videos. Traditional approaches often rely on extensive labeled data and incur high computational costs. Recent tuning-free methods based on Multimodal Large Language Models (MLLMs) offer a promising alternative by leveraging their rich world knowledge. However, these methods typically rely on textual outputs, which introduces information loss, exhibits normalcy bias, and suffers from prompt sensitivity, making them insufficient for capturing subtle anomalous cues. To address these constraints, we propose HeadHunt-VAD, a novel tuning-free VAD paradigm that bypasses textual generation by directly hunting robust anomaly-sensitive internal attention heads within the frozen MLLM. Central to our method is a Robust Head Identification module that systematically evaluates all attention heads using a multi-criteria analysis of saliency and stability, identifying a sparse subset of heads that are consistently discriminative across diverse prompts. Features from these expert heads are then fed into a lightweight anomaly scorer and a temporal locator, enabling efficient and accurate anomaly detection with interpretable outputs. Extensive experiments show that HeadHunt-VAD achieves state-of-the-art performance among tuning-free methods on two major VAD benchmarks while maintaining high efficiency, validating head-level probing in MLLMs as a powerful and practical solution for real-world anomaly detection.
Empowering smart app development with SolidGPT: an edge-cloud hybrid AI agent framework
Dec 09, 2025The integration of Large Language Models (LLMs) into mobile and software development workflows faces a persistent tension among three demands: semantic awareness, developer productivity, and data privacy. Traditional cloud-based tools offer strong reasoning but risk data exposure and latency, while on-device solutions lack full-context understanding across codebase and developer tooling. We introduce SolidGPT, an open-source, edge-cloud hybrid developer assistant built on GitHub, designed to enhance code and workspace semantic search. SolidGPT enables developers to: talk to your codebase: interactively query code and project structure, discovering the right methods and modules without manual searching. Automate software project workflows: generate PRDs, task breakdowns, Kanban boards, and even scaffold web app beginnings, with deep integration via VSCode and Notion. Configure private, extensible agents: onboard private code folders (up to approximately 500 files), connect Notion, customize AI agent personas via embedding and in-context training, and deploy via Docker, CLI, or VSCode extension. In practice, SolidGPT empowers developer productivity through: Semantic-rich code navigation: no more hunting through files or wondering where a feature lives. Integrated documentation and task management: seamlessly sync generated PRD content and task boards into developer workflows. Privacy-first design: running locally via Docker or VSCode, with full control over code and data, while optionally reaching out to LLM APIs as needed. By combining interactive code querying, automated project scaffolding, and human-AI collaboration, SolidGPT provides a practical, privacy-respecting edge assistant that accelerates real-world development workflows, ideal for intelligent mobile and software engineering contexts.
Characterizing Lane-Changing Behavior in Mixed Traffic
Dec 08, 2025Characterizing and understanding lane-changing behavior in the presence of automated vehicles (AVs) is crucial to ensuring safety and efficiency in mixed traffic. Accordingly, this study aims to characterize the interactions between the lane-changing vehicle (active vehicle) and the vehicle directly impacted by the maneuver in the target lane (passive vehicle). Utilizing real-world trajectory data from the Waymo Open Motion Dataset (WOMD), this study explores patterns in lane-changing behavior and provides insight into how these behaviors evolve under different AV market penetration rates (MPRs). In particular, we propose a game-theoretic framework to analyze cooperative and defective behaviors in mixed traffic, applied to the 7,636 observed lane-changing events in the WOMD. First, we utilize k-means clustering to classify vehicles as cooperative or defective, revealing that the proportions of cooperative AVs are higher than those of HDVs in both active and passive roles. Next, we jointly estimate the utilities of active and passive vehicles to model their behaviors using the quantal response equilibrium framework. Empirical payoff tables are then constructed based on these utilities. Using these payoffs, we analyze the presence of social dilemmas and examine the evolution of cooperative behaviors using evolutionary game theory. Our results reveal the presence of social dilemmas in approximately 4% and 11% of lane-changing events for active and passive vehicles, respectively, with most classified as Stag Hunt or Prisoner's Dilemma (Chicken Game rarely observed). Moreover, the Monte Carlo simulation results show that repeated lane-changing interactions consistently lead to increased cooperative behavior over time, regardless of the AV penetration rate.
Semi-supervised Vertex Hunting, with Applications in Network and Text Analysis
Oct 26, 2025Vertex hunting (VH) is the task of estimating a simplex from noisy data points and has many applications in areas such as network and text analysis. We introduce a new variant, semi-supervised vertex hunting (SSVH), in which partial information is available in the form of barycentric coordinates for some data points, known only up to an unknown transformation. To address this problem, we develop a method that leverages properties of orthogonal projection matrices, drawing on novel insights from linear algebra. We establish theoretical error bounds for our method and demonstrate that it achieves a faster convergence rate than existing unsupervised VH algorithms. Finally, we apply SSVH to two practical settings, semi-supervised network mixed membership estimation and semi-supervised topic modeling, resulting in efficient and scalable algorithms.