 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on Real-World Face Restoration: Methods and Results
Apr 20, 2025This paper provides a review of the NTIRE 2025 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural, realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. The track of the challenge evaluates performance using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 141 registrants, with 13 teams submitting valid models, and ultimately, 10 teams achieved a valid score in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
GLAD: Towards Better Reconstruction with Global and Local Adaptive Diffusion Models for Unsupervised Anomaly Detection
Jun 11, 2024



Diffusion models have shown superior performance on unsupervised anomaly detection tasks. Since trained with normal data only, diffusion models tend to reconstruct normal counterparts of test images with certain noises added. However, these methods treat all potential anomalies equally, which may cause two main problems. From the global perspective, the difficulty of reconstructing images with different anomalies is uneven. Therefore, instead of utilizing the same setting for all samples, we propose to predict a particular denoising step for each sample by evaluating the difference between image contents and the priors extracted from diffusion models. From the local perspective, reconstructing abnormal regions differs from normal areas even in the same image. Theoretically, the diffusion model predicts a noise for each step, typically following a standard Gaussian distribution. However, due to the difference between the anomaly and its potential normal counterpart, the predicted noise in abnormal regions will inevitably deviate from the standard Gaussian distribution. To this end, we propose introducing synthetic abnormal samples in training to encourage the diffusion models to break through the limitation of standard Gaussian distribution, and a spatial-adaptive feature fusion scheme is utilized during inference. With the above modifications, we propose a global and local adaptive diffusion model (abbreviated to GLAD) for unsupervised anomaly detection, which introduces appealing flexibility and achieves anomaly-free reconstruction while retaining as much normal information as possible. Extensive experiments are conducted on three commonly used anomaly detection datasets (MVTec-AD, MPDD, and VisA) and a printed circuit board dataset (PCB-Bank) we integrated, showing the effectiveness of the proposed method.
MetaF2N: Blind Image Super-Resolution by Learning Efficient Model Adaptation from Faces
Sep 15, 2023Due to their highly structured characteristics, faces are easier to recover than natural scenes for blind image super-resolution. Therefore, we can extract the degradation representation of an image from the low-quality and recovered face pairs. Using the degradation representation, realistic low-quality images can then be synthesized to fine-tune the super-resolution model for the real-world low-quality image. However, such a procedure is time-consuming and laborious, and the gaps between recovered faces and the ground-truths further increase the optimization uncertainty. To facilitate efficient model adaptation towards image-specific degradations, we propose a method dubbed MetaF2N, which leverages the contained Faces to fine-tune model parameters for adapting to the whole Natural image in a Meta-learning framework. The degradation extraction and low-quality image synthesis steps are thus circumvented in our MetaF2N, and it requires only one fine-tuning step to get decent performance. Considering the gaps between the recovered faces and ground-truths, we further deploy a MaskNet for adaptively predicting loss weights at different positions to reduce the impact of low-confidence areas. To evaluate our proposed MetaF2N, we have collected a real-world low-quality dataset with one or multiple faces in each image, and our MetaF2N achieves superior performance on both synthetic and real-world datasets. Source code, pre-trained models, and collected datasets are available at https://github.com/yinzhicun/MetaF2N.
Reversed Image Signal Processing and RAW Reconstruction. AIM 2022 Challenge Report
Oct 20, 2022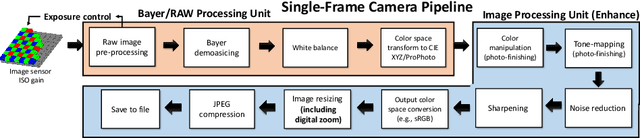
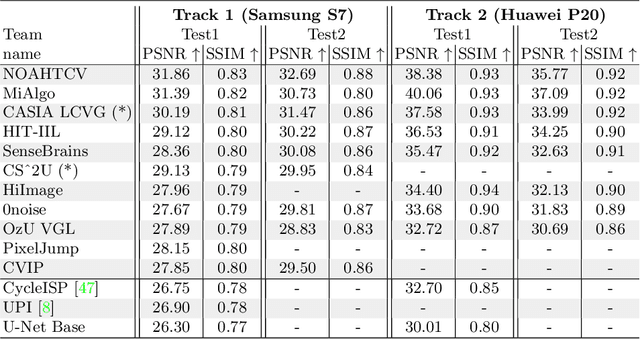
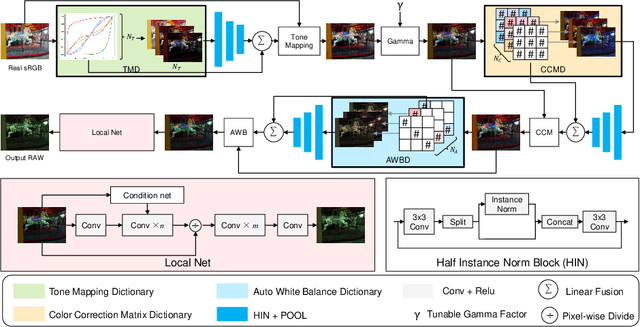
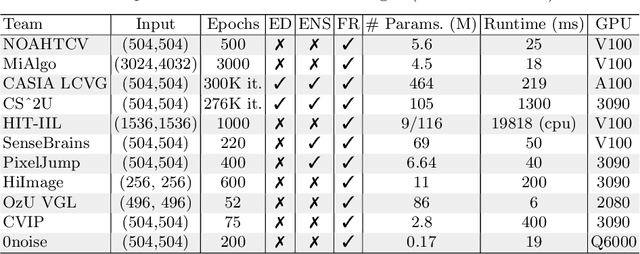
Cameras capture sensor RAW images and transform them into pleasant RGB images, suitable for the human eyes, using their integrated Image Signal Processor (ISP). Numerous low-level vision tasks operate in the RAW domain (e.g. image denoising, white balance) due to its linear relationship with the scene irradiance, wide-range of information at 12bits, and sensor designs. Despite this, RAW image datasets are scarce and more expensive to collect than the already large and public RGB datasets. This paper introduces the AIM 2022 Challenge on Reversed Image Signal Processing and RAW Reconstruction. We aim to recover raw sensor images from the corresponding RGBs without metadata and, by doing this, "reverse" the ISP transformation. The proposed methods and benchmark establish the state-of-the-art for this low-level vision inverse problem, and generating realistic raw sensor readings can potentially benefit other tasks such as denoising and super-resolution.