 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Large-scale Generative Ranking
May 08, 2025
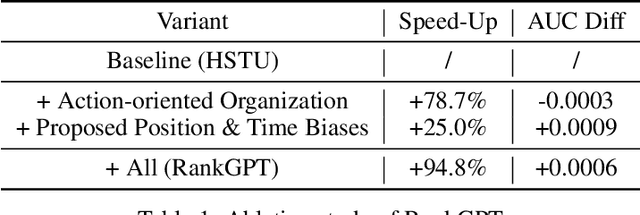
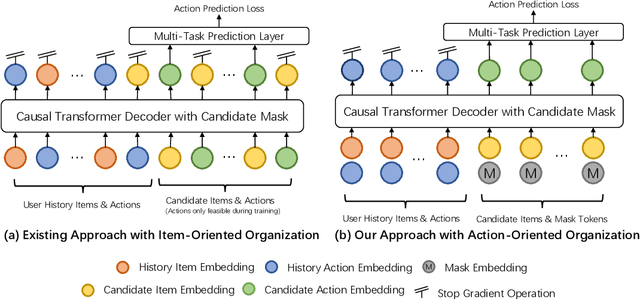

Generative recommendation has recently emerged as a promising paradigm in information retrieval. However, generative ranking systems are still understudied, particularly with respect to their effectiveness and feasibility in large-scale industrial settings. This paper investigates this topic at the ranking stage of Xiaohongshu's Explore Feed, a recommender system that serves hundreds of millions of users. Specifically, we first examine how generative ranking outperforms current industrial recommenders. Through theoretical and empirical analyses, we find that the primary improvement in effectiveness stems from the generative architecture, rather than the training paradigm. To facilitate efficient deployment of generative ranking, we introduce GenRank, a novel generative architecture for ranking. We validate the effectiveness and efficiency of our solution through online A/B experiments. The results show that GenRank achieves significant improvements in user satisfaction with nearly equivalent computational resources compared to the existing production system.
KnowledgeShovel: An AI-in-the-Loop Document Annotation System for Scientific Knowledge Base Construction
Oct 06, 2022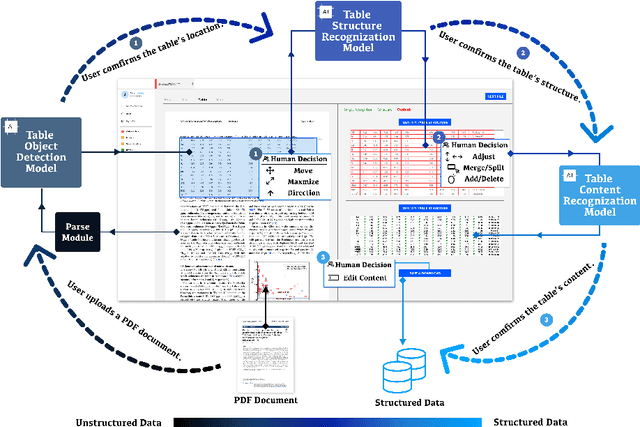
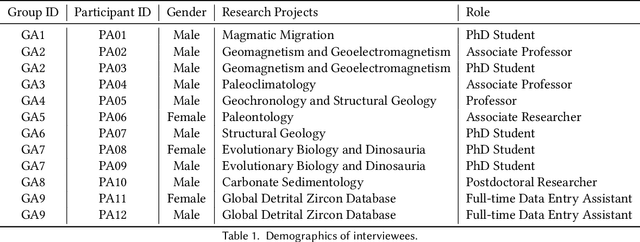
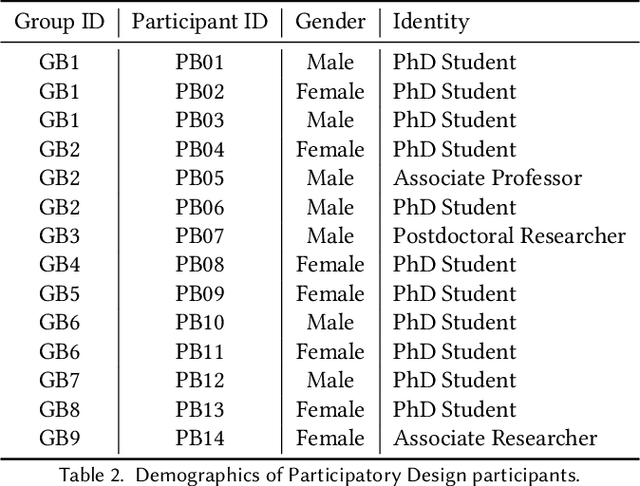
Constructing a comprehensive, accurate, and useful scientific knowledge base is crucial for human researchers synthesizing scientific knowledge and for enabling Al-driven scientific discovery. However, the current process is difficult, error-prone, and laborious due to (1) the enormous amount of scientific literature available; (2) the highly-specialized scientific domains; (3) the diverse modalities of information (text, figure, table); and, (4) the silos of scientific knowledge in different publications with inconsistent formats and structures. Informed by a formative study and iterated with participatory design workshops, we designed and developed KnowledgeShovel, an Al-in-the-Loop document annotation system for researchers to construct scientific knowledge bases. The design of KnowledgeShovel introduces a multi-step multi-modal human-AI collaboration pipeline that aligns with users' existing workflows to improve data accuracy while reducing the human burden. A follow-up user evaluation with 7 geoscience researchers shows that KnowledgeShovel can enable efficient construction of scientific knowledge bases with satisfactory accuracy.
DeepShovel: An Online Collaborative Platform for Data Extraction in Geoscience Literature with AI Assistance
Feb 24, 2022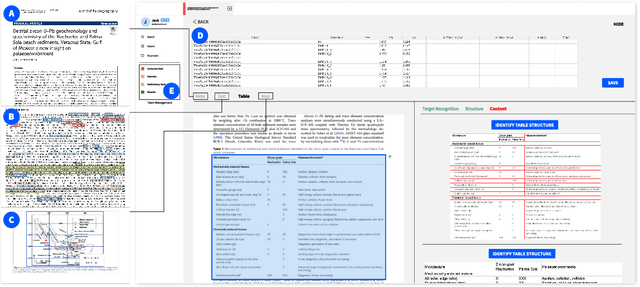
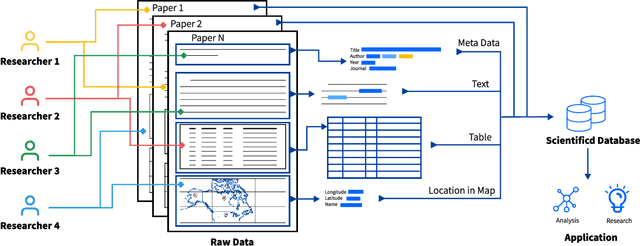

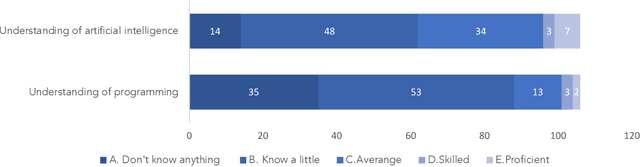
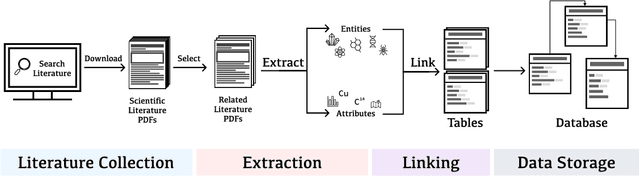
Geoscientists, as well as researchers in many fields, need to read a huge amount of literature to locate, extract, and aggregate relevant results and data to enable future research or to build a scientific database, but there is no existing system to support this use case well. In this paper, based on the findings of a formative study about how geoscientists collaboratively annotate literature and extract and aggregate data, we proposed DeepShovel, a publicly-available AI-assisted data extraction system to support their needs. DeepShovel leverages the state-of-the-art neural network models to support researcher(s) easily and accurately annotate papers (in the PDF format) and extract data from tables, figures, maps, etc. in a human-AI collaboration manner. A follow-up user evaluation with 14 researchers suggested DeepShovel improved users' efficiency of data extraction for building scientific databases, and encouraged teams to form a larger scale but more tightly-coupled collaboration.
Overlapping Community Detection in Temporal Text Networks
Jan 13, 2021
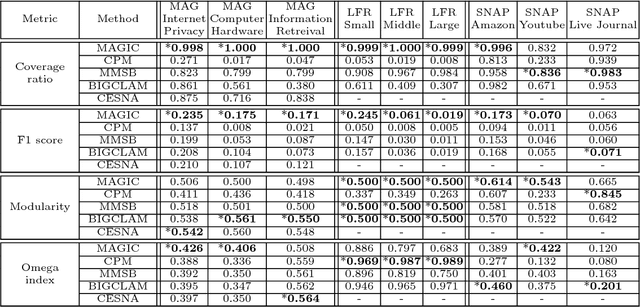


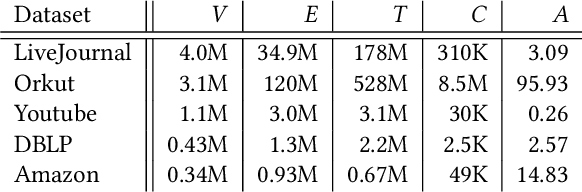
Analyzing the groups in the network based on same attributes, functions or connections between nodes is a way to understand network information. The task of discovering a series of node groups is called community detection. Generally, two types of information can be utilized to fulfill this task, i.e., the link structures and the node attributes. The temporal text network is a special kind of network that contains both sources of information. Typical representatives include online blog networks, the World Wide Web (WWW) and academic citation networks. In this paper, we study the problem of overlapping community detection in temporal text network. By examining 32 large temporal text networks, we find a lot of edges connecting two nodes with no common community and discover that nodes in the same community share similar textual contents. This scenario cannot be quantitatively modeled by practically all existing community detection methods. Motivated by these empirical observations, we propose MAGIC (Model Affiliation Graph with Interacting Communities), a generative model which captures community interactions and considers the information from both link structures and node attributes. Our experiments on 3 types of datasets show that MAGIC achieves large improvements over 4 state-of-the-art methods in terms of 4 widely-used metrics.
High-Order Relation Construction and Mining for Graph Matching
Oct 09, 2020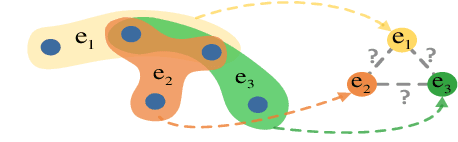
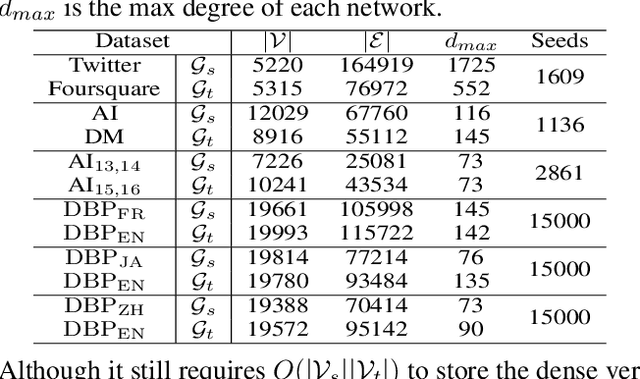
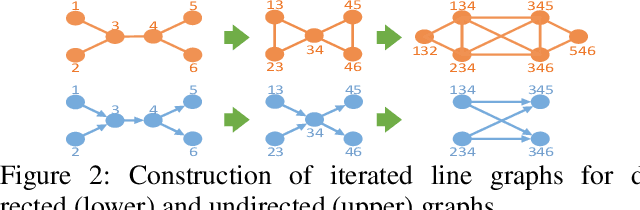
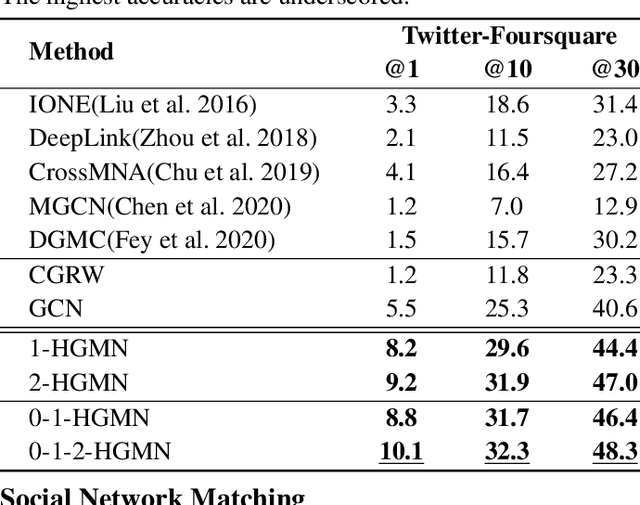
Graph matching pairs corresponding nodes across two or more graphs. The problem is difficult as it is hard to capture the structural similarity across graphs, especially on large graphs. We propose to incorporate high-order information for matching large-scale graphs. Iterated line graphs are introduced for the first time to describe such high-order information, based on which we present a new graph matching method, called High-order Graph Matching Network (HGMN), to learn not only the local structural correspondence, but also the hyperedge relations across graphs. We theoretically prove that iterated line graphs are more expressive than graph convolution networks in terms of aligning nodes. By imposing practical constraints, HGMN is made scalable to large-scale graphs. Experimental results on a variety of settings have shown that, HGMN acquires more accurate matching results than the state-of-the-art, verifying our method effectively captures the structural similarity across different graphs.
On Geometric Structure of Activation Spaces in Neural Networks
Apr 02, 2019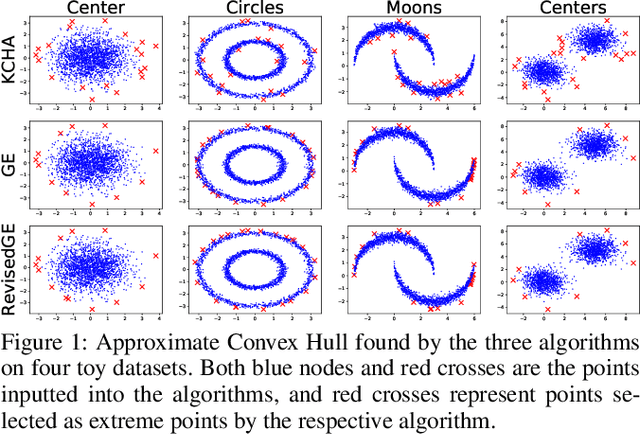

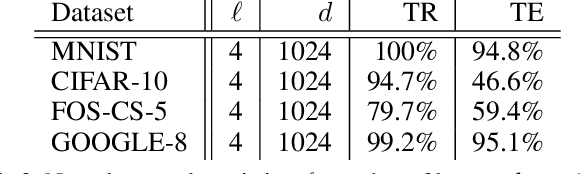
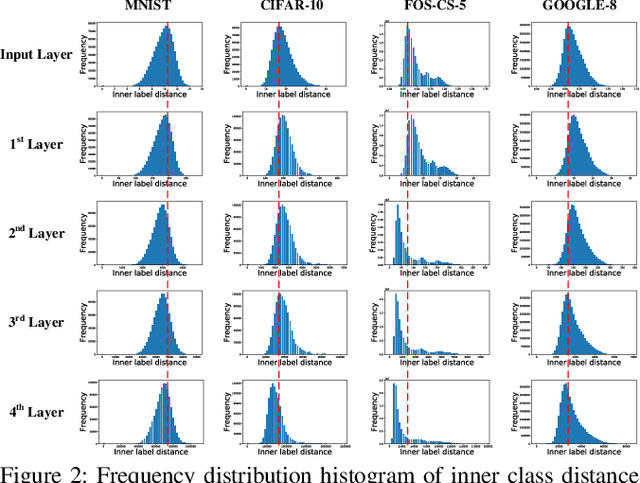
In this paper, we investigate the geometric structure of activation spaces of fully connected layers in neural networks and then show applications of this study. We propose an efficient approximation algorithm to characterize the convex hull of massive points in high dimensional space. Based on this new algorithm, four common geometric properties shared by the activation spaces are concluded, which gives a rather clear description of the activation spaces. We then propose an alternative classification method grounding on the geometric structure description, which works better than neural networks alone. Surprisingly, this data classification method can be an indicator of overfitting in neural networks. We believe our work reveals several critical intrinsic properties of modern neural networks and further gives a new metric for evaluating them.
CommunityGAN: Community Detection with Generative Adversarial Nets
Jan 23, 2019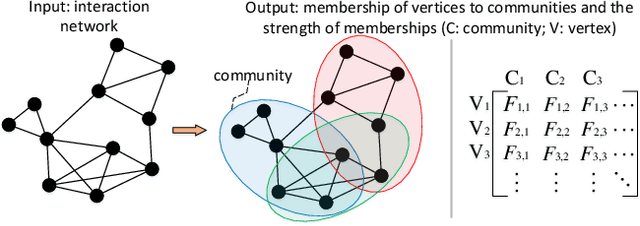
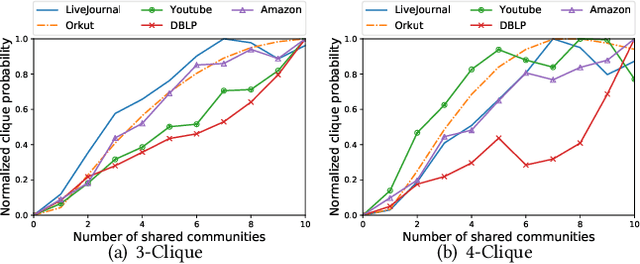
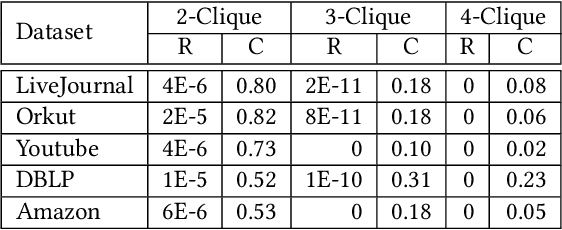
Community detection refers to the task of discovering groups of vertices sharing similar properties or functions so as to understand the network data. With the recent development of deep learning, graph representation learning techniques are also utilized for community detection. However, the communities can only be inferred by applying clustering algorithms based on learned vertex embeddings. These general cluster algorithms like K-means and Gaussian Mixture Model cannot output much overlapped communities, which have been proved to be very common in many real-world networks. In this paper, we propose CommunityGAN, a novel community detection framework that jointly solves overlapping community detection and graph representation learning. First, unlike the embedding of conventional graph representation learning algorithms where the vector entry values have no specific meanings, the embedding of CommunityGAN indicates the membership strength of vertices to communities. Second, a specifically designed Generative Adversarial Net (GAN) is adopted to optimize such embedding. Through the minimax competition between the motif-level generator and discriminator, both of them can alternatively and iteratively boost their performance and finally output a better community structure. Extensive experiments on synthetic data and real-world tasks demonstrate that CommunityGAN achieves substantial community detection performance gains over the state-of-the-art methods.
Predictive Modeling with Delayed Information: a Case Study in E-commerce Transaction Fraud Control
Nov 14, 2018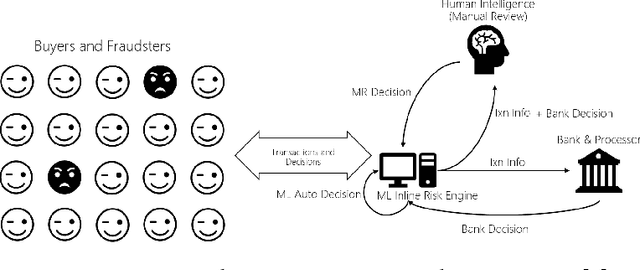
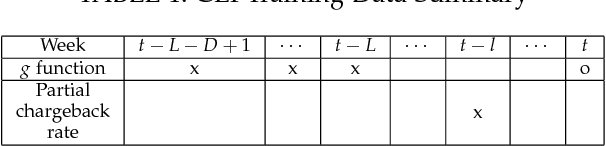
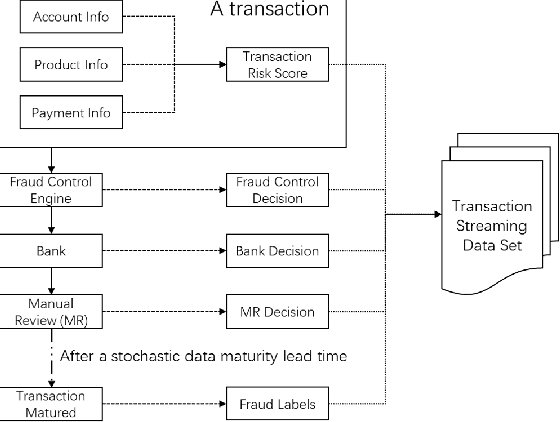
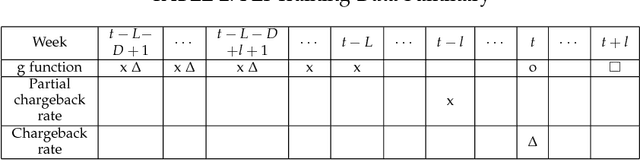
In Business Intelligence, accurate predictive modeling is the key for providing adaptive decisions. We studied predictive modeling problems in this research which was motivated by real-world cases that Microsoft data scientists encountered while dealing with e-commerce transaction fraud control decisions using transaction streaming data in an uncertain probabilistic decision environment. The values of most online transactions related features can return instantly, while the true fraud labels only return after a stochastic delay. Using partially mature data directly for predictive modeling in an uncertain probabilistic decision environment would lead to significant inaccuracy on risk decision-making. To improve accurate estimation of the probabilistic prediction environment, which leads to more accurate predictive modeling, two frameworks, Current Environment Inference (CEI) and Future Environment Inference (FEI), are proposed. These frameworks generated decision environment related features using long-term fully mature and short-term partially mature data, and the values of those features were estimated using varies of learning methods, including linear regression, random forest, gradient boosted tree, artificial neural network, and recurrent neural network. Performance tests were conducted using some e-commerce transaction data from Microsoft. Testing results suggested that proposed frameworks significantly improved the accuracy of decision environment estimation.
Discriminative Data-driven Self-adaptive Fraud Control Decision System with Incomplete Information
Oct 03, 2018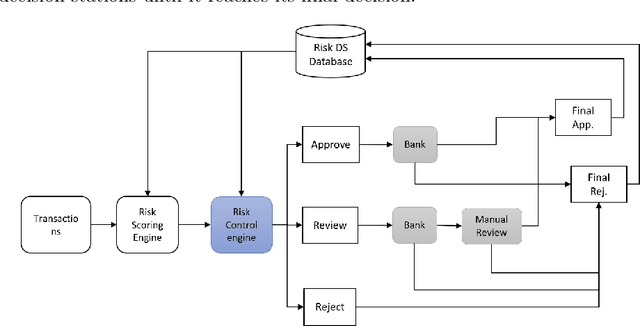
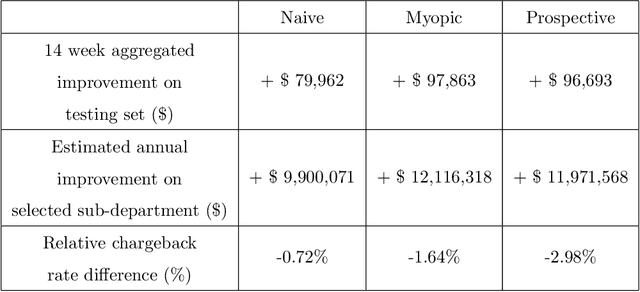
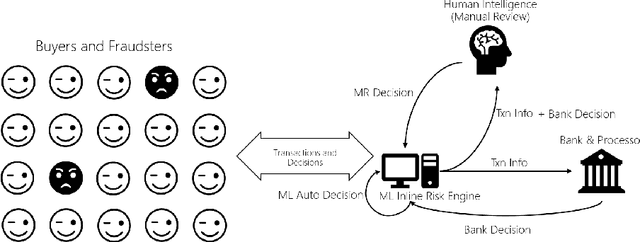
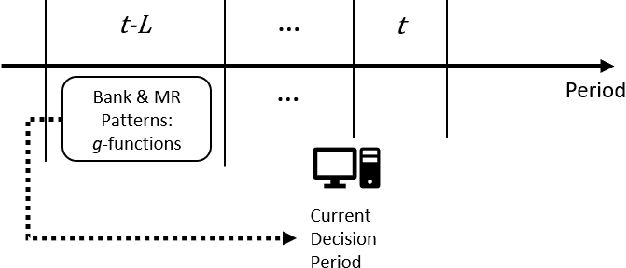
While E-commerce has been growing explosively and online shopping has become popular and even dominant in the present era, online transaction fraud control has drawn considerable attention in business practice and academic research. Conventional fraud control considers mainly the interactions of two major involved decision parties, i.e. merchants and fraudsters, to make fraud classification decision without paying much attention to dynamic looping effect arose from the decisions made by other profit-related parties. This paper proposes a novel fraud control framework that can quantify interactive effects of decisions made by different parties and can adjust fraud control strategies using data analytics, artificial intelligence, and dynamic optimization techniques. Three control models, Naive, Myopic and Prospective Controls, were developed based on the availability of data attributes and levels of label maturity. The proposed models are purely data-driven and self-adaptive in a real-time manner. The field test on Microsoft real online transaction data suggested that new systems could sizably improve the company's profit.
AceKG: A Large-scale Knowledge Graph for Academic Data Mining
Aug 07, 2018


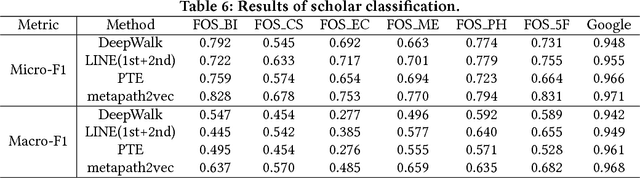
Most existing knowledge graphs (KGs) in academic domains suffer from problems of insufficient multi-relational information, name ambiguity and improper data format for large-scale machine processing. In this paper, we present AceKG, a new large-scale KG in academic domain. AceKG not only provides clean academic information, but also offers a large-scale benchmark dataset for researchers to conduct challenging data mining projects including link prediction, community detection and scholar classification. Specifically, AceKG describes 3.13 billion triples of academic facts based on a consistent ontology, including necessary properties of papers, authors, fields of study, venues and institutes, as well as the relations among them. To enrich the proposed knowledge graph, we also perform entity alignment with existing databases and rule-based inference. Based on AceKG, we conduct experiments of three typical academic data mining tasks and evaluate several state-of- the-art knowledge embedding and network representation learning approaches on the benchmark datasets built from AceKG. Finally, we discuss several promising research directions that benefit from AceKG.