 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Mar 30, 2024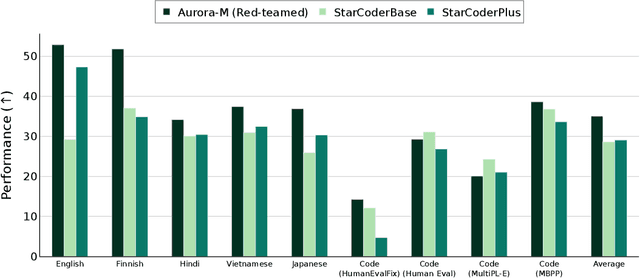

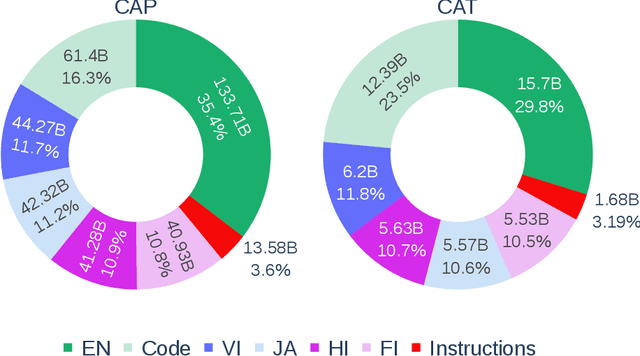
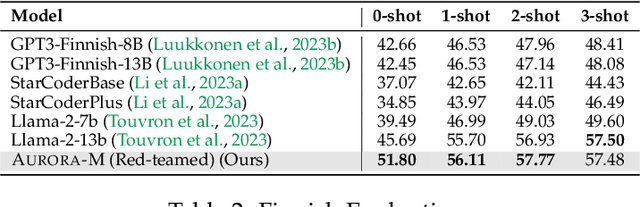
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
Learning Causal State Representations of Partially Observable Environments
Jun 25, 2019
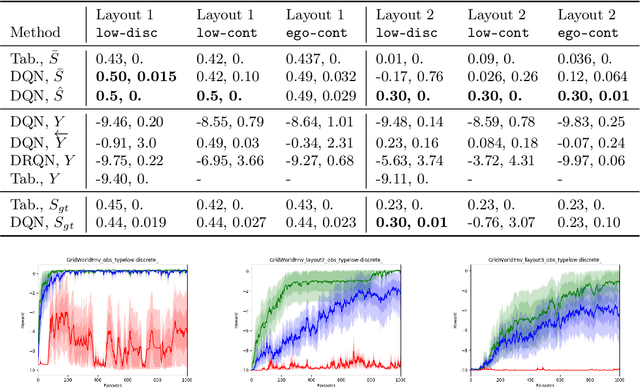


Intelligent agents can cope with sensory-rich environments by learning task-agnostic state abstractions. In this paper, we propose mechanisms to approximate causal states, which optimally compress the joint history of actions and observations in partially-observable Markov decision processes. Our proposed algorithm extracts causal state representations from RNNs that are trained to predict subsequent observations given the history. We demonstrate that these learned task-agnostic state abstractions can be used to efficiently learn policies for reinforcement learning problems with rich observation spaces. We evaluate agents using multiple partially observable navigation tasks with both discrete (GridWorld) and continuous (VizDoom, ALE) observation processes that cannot be solved by traditional memory-limited methods. Our experiments demonstrate systematic improvement of the DQN and tabular models using approximate causal state representations with respect to recurrent-DQN baselines trained with raw inputs.
Tensor Regression Networks
Jul 24, 2018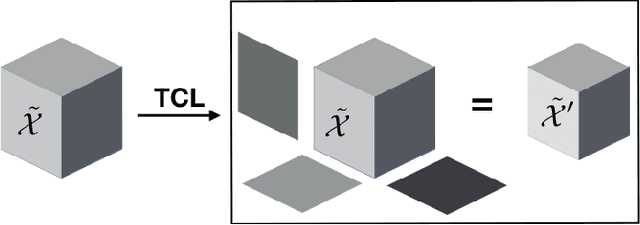
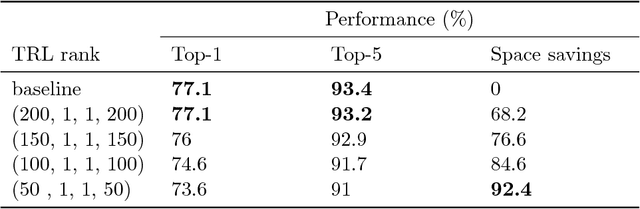

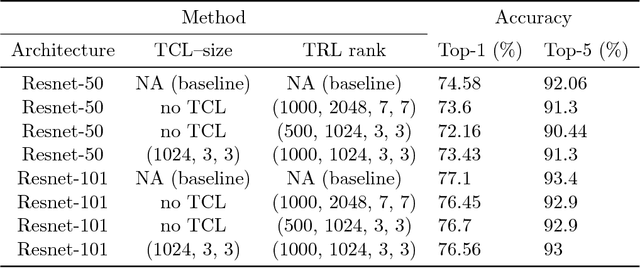
Convolutional neural networks typically consist of many convolutional layers followed by several fully-connected layers. While convolutional layers map between high-order activation tensors, the fully-connected layers operate on flattened activation vectors. Despite its success, this approach has notable drawbacks. Flattening discards multilinear structure in the activations, and fully-connected layers require many parameters. We address these problems by incorporating tensor algebraic operations that preserve multilinear structure at every layer. First, we introduce Tensor Contraction Layers (TCLs) that reduce the dimensionality of their input while preserving their multilinear structure using tensor contraction. Next, we introduce Tensor Regression Layers (TRLs), to express outputs through a low-rank multilinear mapping from a high-order activation tensor to an output tensor of arbitrary order. We learn the contraction and regression factors end-to-end, and by imposing low rank on both, we produce accurate nets with few parameters. Additionally, our layers regularize networks by imposing low-rank constraints on the activations (TCL) and regression weights (TRL). Experiments on ImageNet show that, applied to VGG and ResNet architectures, TCLs and TRLs reduce the number of parameters compared to fully-connected layers by more than 65% without impacting accuracy.
Question Type Guided Attention in Visual Question Answering
Jul 18, 2018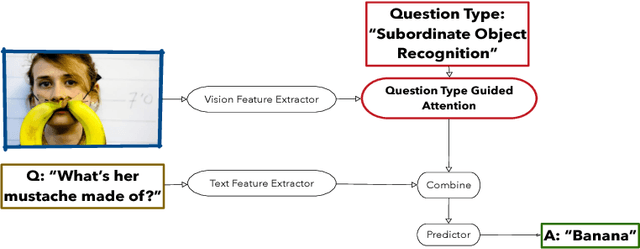
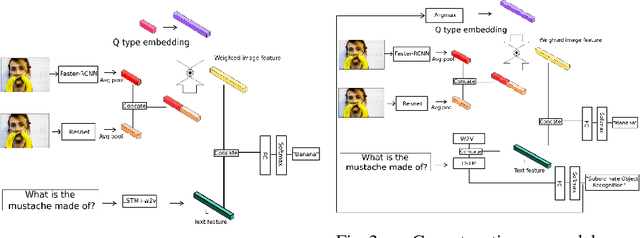
Visual Question Answering (VQA) requires integration of feature maps with drastically different structures and focus of the correct regions. Image descriptors have structures at multiple spatial scales, while lexical inputs inherently follow a temporal sequence and naturally cluster into semantically different question types. A lot of previous works use complex models to extract feature representations but neglect to use high-level information summary such as question types in learning. In this work, we propose Question Type-guided Attention (QTA). It utilizes the information of question type to dynamically balance between bottom-up and top-down visual features, respectively extracted from ResNet and Faster R-CNN networks. We experiment with multiple VQA architectures with extensive input ablation studies over the TDIUC dataset and show that QTA systematically improves the performance by more than 5% across multiple question type categories such as "Activity Recognition", "Utility" and "Counting" on TDIUC dataset. By adding QTA on the state-of-art model MCB, we achieve 3% improvement for overall accuracy. Finally, we propose a multi-task extension to predict question types which generalizes QTA to applications that lack of question type, with minimal performance loss.
Born Again Neural Networks
Jun 29, 2018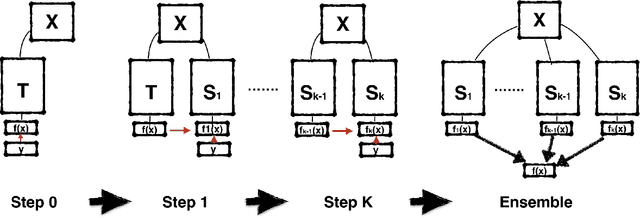


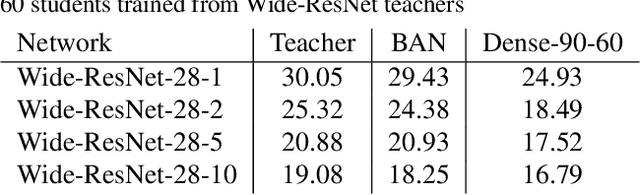
Knowledge distillation (KD) consists of transferring knowledge from one machine learning model (the teacher}) to another (the student). Commonly, the teacher is a high-capacity model with formidable performance, while the student is more compact. By transferring knowledge, one hopes to benefit from the student's compactness. %we desire a compact model with performance close to the teacher's. We study KD from a new perspective: rather than compressing models, we train students parameterized identically to their teachers. Surprisingly, these {Born-Again Networks (BANs), outperform their teachers significantly, both on computer vision and language modeling tasks. Our experiments with BANs based on DenseNets demonstrate state-of-the-art performance on the CIFAR-10 (3.5%) and CIFAR-100 (15.5%) datasets, by validation error. Additional experiments explore two distillation objectives: (i) Confidence-Weighted by Teacher Max (CWTM) and (ii) Dark Knowledge with Permuted Predictions (DKPP). Both methods elucidate the essential components of KD, demonstrating a role of the teacher outputs on both predicted and non-predicted classes. We present experiments with students of various capacities, focusing on the under-explored case where students overpower teachers. Our experiments show significant advantages from transferring knowledge between DenseNets and ResNets in either direction.
Compact Tensor Pooling for Visual Question Answering
Jun 20, 2017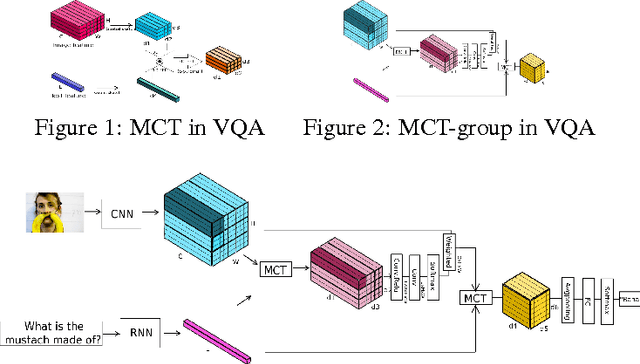
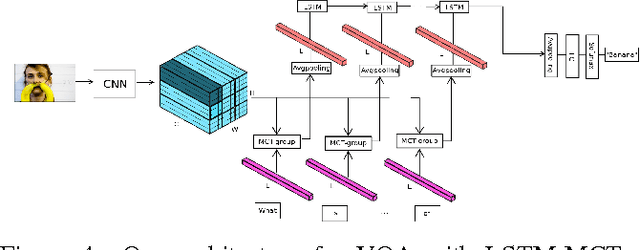
Performing high level cognitive tasks requires the integration of feature maps with drastically different structure. In Visual Question Answering (VQA) image descriptors have spatial structures, while lexical inputs inherently follow a temporal sequence. The recently proposed Multimodal Compact Bilinear pooling (MCB) forms the outer products, via count-sketch approximation, of the visual and textual representation at each spatial location. While this procedure preserves spatial information locally, outer-products are taken independently for each fiber of the activation tensor, and therefore do not include spatial context. In this work, we introduce multi-dimensional sketch ({MD-sketch}), a novel extension of count-sketch to tensors. Using this new formulation, we propose Multimodal Compact Tensor Pooling (MCT) to fully exploit the global spatial context during bilinear pooling operations. Contrarily to MCB, our approach preserves spatial context by directly convolving the MD-sketch from the visual tensor features with the text vector feature using higher order FFT. Furthermore we apply MCT incrementally at each step of the question embedding and accumulate the multi-modal vectors with a second LSTM layer before the final answer is chosen.
Tensor Contraction Layers for Parsimonious Deep Nets
Jun 01, 2017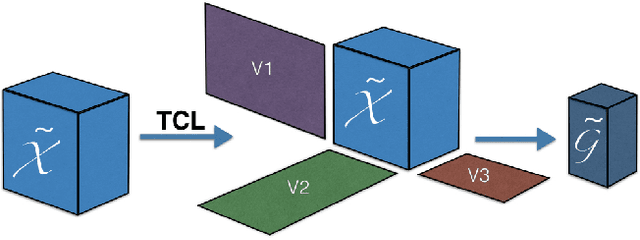
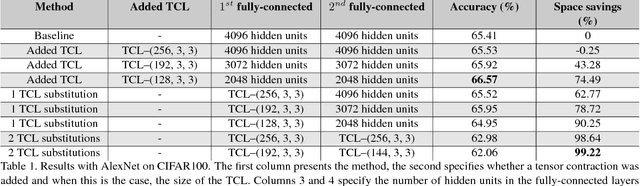
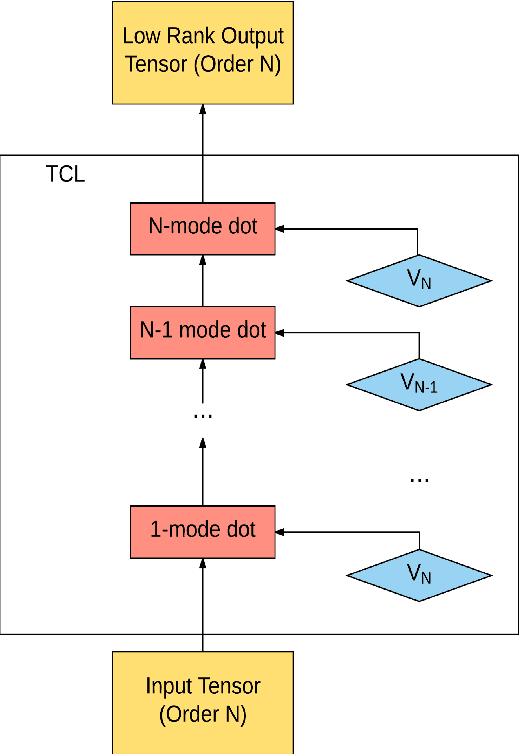

Tensors offer a natural representation for many kinds of data frequently encountered in machine learning. Images, for example, are naturally represented as third order tensors, where the modes correspond to height, width, and channels. Tensor methods are noted for their ability to discover multi-dimensional dependencies, and tensor decompositions in particular, have been used to produce compact low-rank approximations of data. In this paper, we explore the use of tensor contractions as neural network layers and investigate several ways to apply them to activation tensors. Specifically, we propose the Tensor Contraction Layer (TCL), the first attempt to incorporate tensor contractions as end-to-end trainable neural network layers. Applied to existing networks, TCLs reduce the dimensionality of the activation tensors and thus the number of model parameters. We evaluate the TCL on the task of image recognition, augmenting two popular networks (AlexNet, VGG). The resulting models are trainable end-to-end. Applying the TCL to the task of image recognition, using the CIFAR100 and ImageNet datasets, we evaluate the effect of parameter reduction via tensor contraction on performance. We demonstrate significant model compression without significant impact on the accuracy and, in some cases, improved performance.
Active Long Term Memory Networks
Jun 07, 2016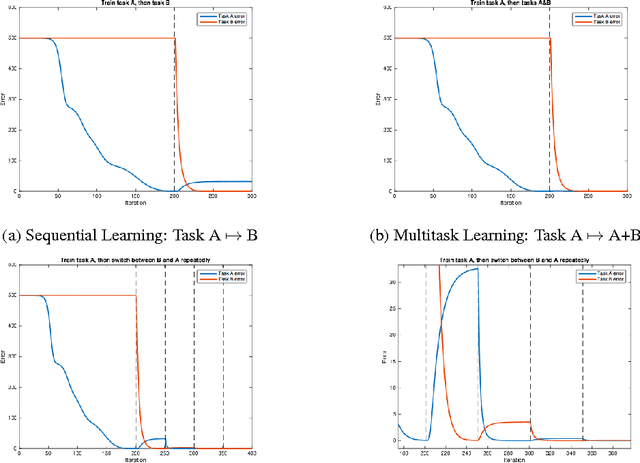

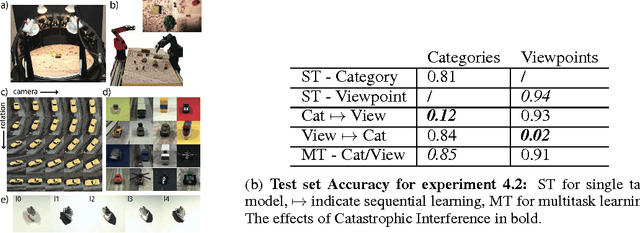
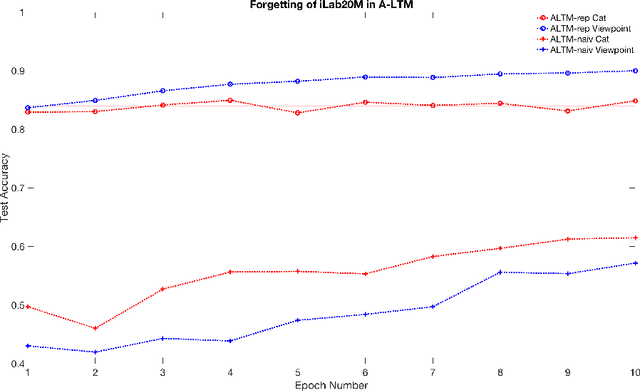
Continual Learning in artificial neural networks suffers from interference and forgetting when different tasks are learned sequentially. This paper introduces the Active Long Term Memory Networks (A-LTM), a model of sequential multi-task deep learning that is able to maintain previously learned association between sensory input and behavioral output while acquiring knew knowledge. A-LTM exploits the non-convex nature of deep neural networks and actively maintains knowledge of previously learned, inactive tasks using a distillation loss. Distortions of the learned input-output map are penalized but hidden layers are free to transverse towards new local optima that are more favorable for the multi-task objective. We re-frame the McClelland's seminal Hippocampal theory with respect to Catastrophic Inference (CI) behavior exhibited by modern deep architectures trained with back-propagation and inhomogeneous sampling of latent factors across epochs. We present empirical results of non-trivial CI during continual learning in Deep Linear Networks trained on the same task, in Convolutional Neural Networks when the task shifts from predicting semantic to graphical factors and during domain adaptation from simple to complex environments. We present results of the A-LTM model's ability to maintain viewpoint recognition learned in the highly controlled iLab-20M dataset with 10 object categories and 88 camera viewpoints, while adapting to the unstructured domain of Imagenet with 1,000 object categories.
Sparse Predictive Structure of Deconvolved Functional Brain Networks
Oct 24, 2013
The functional and structural representation of the brain as a complex network is marked by the fact that the comparison of noisy and intrinsically correlated high-dimensional structures between experimental conditions or groups shuns typical mass univariate methods. Furthermore most network estimation methods cannot distinguish between real and spurious correlation arising from the convolution due to nodes' interaction, which thus introduces additional noise in the data. We propose a machine learning pipeline aimed at identifying multivariate differences between brain networks associated to different experimental conditions. The pipeline (1) leverages the deconvolved individual contribution of each edge and (2) maps the task into a sparse classification problem in order to construct the associated "sparse deconvolved predictive network", i.e., a graph with the same nodes of those compared but whose edge weights are defined by their relevance for out of sample predictions in classification. We present an application of the proposed method by decoding the covert attention direction (left or right) based on the single-trial functional connectivity matrix extracted from high-frequency magnetoencephalography (MEG) data. Our results demonstrate how network deconvolution matched with sparse classification methods outperforms typical approaches for MEG decoding.