 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact Tensor Pooling for Visual Question Answering
Paper and Code
Jun 20, 2017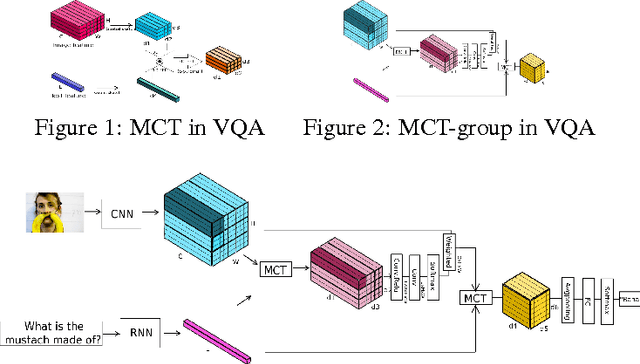
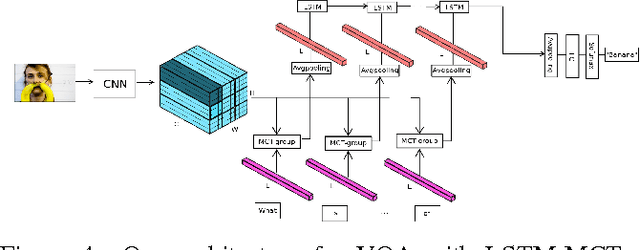
Performing high level cognitive tasks requires the integration of feature maps with drastically different structure. In Visual Question Answering (VQA) image descriptors have spatial structures, while lexical inputs inherently follow a temporal sequence. The recently proposed Multimodal Compact Bilinear pooling (MCB) forms the outer products, via count-sketch approximation, of the visual and textual representation at each spatial location. While this procedure preserves spatial information locally, outer-products are taken independently for each fiber of the activation tensor, and therefore do not include spatial context. In this work, we introduce multi-dimensional sketch ({MD-sketch}), a novel extension of count-sketch to tensors. Using this new formulation, we propose Multimodal Compact Tensor Pooling (MCT) to fully exploit the global spatial context during bilinear pooling operations. Contrarily to MCB, our approach preserves spatial context by directly convolving the MD-sketch from the visual tensor features with the text vector feature using higher order FFT. Furthermore we apply MCT incrementally at each step of the question embedding and accumulate the multi-modal vectors with a second LSTM layer before the final answer is chosen.