 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Type Guided Attention in Visual Question Answering
Paper and Code
Jul 18, 2018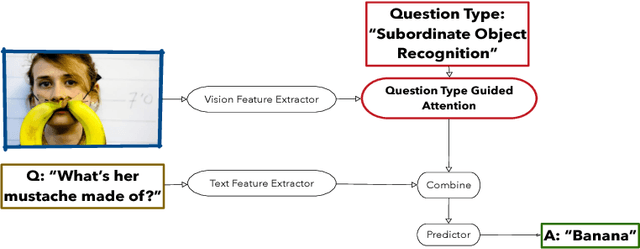
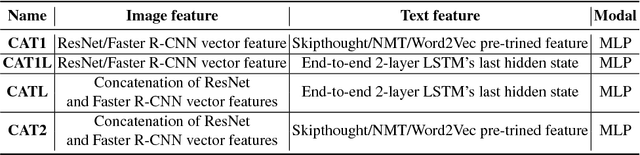
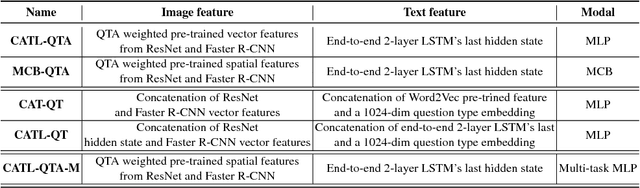
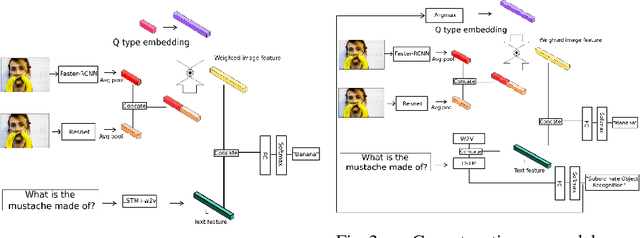
Visual Question Answering (VQA) requires integration of feature maps with drastically different structures and focus of the correct regions. Image descriptors have structures at multiple spatial scales, while lexical inputs inherently follow a temporal sequence and naturally cluster into semantically different question types. A lot of previous works use complex models to extract feature representations but neglect to use high-level information summary such as question types in learning. In this work, we propose Question Type-guided Attention (QTA). It utilizes the information of question type to dynamically balance between bottom-up and top-down visual features, respectively extracted from ResNet and Faster R-CNN networks. We experiment with multiple VQA architectures with extensive input ablation studies over the TDIUC dataset and show that QTA systematically improves the performance by more than 5% across multiple question type categories such as "Activity Recognition", "Utility" and "Counting" on TDIUC dataset. By adding QTA on the state-of-art model MCB, we achieve 3% improvement for overall accuracy. Finally, we propose a multi-task extension to predict question types which generalizes QTA to applications that lack of question type, with minimal performance loss.