 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaMP-Cap: Personalized Figure Caption Generation With Multimodal Figure Profiles
Jun 06, 2025Figure captions are crucial for helping readers understand and remember a figure's key message. Many models have been developed to generate these captions, helping authors compose better quality captions more easily. Yet, authors almost always need to revise generic AI-generated captions to match their writing style and the domain's style, highlighting the need for personalization. Despite language models' personalization (LaMP) advances, these technologies often focus on text-only settings and rarely address scenarios where both inputs and profiles are multimodal. This paper introduces LaMP-Cap, a dataset for personalized figure caption generation with multimodal figure profiles. For each target figure, LaMP-Cap provides not only the needed inputs, such as figure images, but also up to three other figures from the same document--each with its image, caption, and figure-mentioning paragraphs--as a profile to characterize the context. Experiments with four LLMs show that using profile information consistently helps generate captions closer to the original author-written ones. Ablation studies reveal that images in the profile are more helpful than figure-mentioning paragraphs, highlighting the advantage of using multimodal profiles over text-only ones.
Using Contextually Aligned Online Reviews to Measure LLMs' Performance Disparities Across Language Varieties
Feb 10, 2025A language can have different varieties. These varieties can affect the performance of natural language processing (NLP) models, including large language models (LLMs), which are often trained on data from widely spoken varieties. This paper introduces a novel and cost-effective approach to benchmark model performance across language varieties. We argue that international online review platforms, such as Booking.com, can serve as effective data sources for constructing datasets that capture comments in different language varieties from similar real-world scenarios, like reviews for the same hotel with the same rating using the same language (e.g., Mandarin Chinese) but different language varieties (e.g., Taiwan Mandarin, Mainland Mandarin). To prove this concept, we constructed a contextually aligned dataset comprising reviews in Taiwan Mandarin and Mainland Mandarin and tested six LLMs in a sentiment analysis task. Our results show that LLMs consistently underperform in Taiwan Mandarin.
Hashtag Re-Appropriation for Audience Control on Recommendation-Driven Social Media Xiaohongshu (rednote)
Jan 30, 2025



Algorithms have played a central role in personalized recommendations on social media. However, they also present significant obstacles for content creators trying to predict and manage their audience reach. This issue is particularly challenging for marginalized groups seeking to maintain safe spaces. Our study explores how women on Xiaohongshu (rednote), a recommendation-driven social platform, proactively re-appropriate hashtags (e.g., #Baby Supplemental Food) by using them in posts unrelated to their literal meaning. The hashtags were strategically chosen from topics that would be uninteresting to the male audience they wanted to block. Through a mixed-methods approach, we analyzed the practice of hashtag re-appropriation based on 5,800 collected posts and interviewed 24 active users from diverse backgrounds to uncover users' motivations and reactions towards the re-appropriation. This practice highlights how users can reclaim agency over content distribution on recommendation-driven platforms, offering insights into self-governance within algorithmic-centered power structures.
Understanding How Paper Writers Use AI-Generated Captions in Figure Caption Writing
Jan 10, 2025Figures and their captions play a key role in scientific publications. However, despite their importance, many captions in published papers are poorly crafted, largely due to a lack of attention by paper authors. While prior AI research has explored caption generation, it has mainly focused on reader-centered use cases, where users evaluate generated captions rather than actively integrating them into their writing. This paper addresses this gap by investigating how paper authors incorporate AI-generated captions into their writing process through a user study involving 18 participants. Each participant rewrote captions for two figures from their own recently published work, using captions generated by state-of-the-art AI models as a resource. By analyzing video recordings of the writing process through interaction analysis, we observed that participants often began by copying and refining AI-generated captions. Paper writers favored longer, detail-rich captions that integrated textual and visual elements but found current AI models less effective for complex figures. These findings highlight the nuanced and diverse nature of figure caption composition, revealing design opportunities for AI systems to better support the challenges of academic writing.
Multi-LLM Collaborative Caption Generation in Scientific Documents
Jan 05, 2025



Scientific figure captioning is a complex task that requires generating contextually appropriate descriptions of visual content. However, existing methods often fall short by utilizing incomplete information, treating the task solely as either an image-to-text or text summarization problem. This limitation hinders the generation of high-quality captions that fully capture the necessary details. Moreover, existing data sourced from arXiv papers contain low-quality captions, posing significant challenges for training large language models (LLMs). In this paper, we introduce a framework called Multi-LLM Collaborative Figure Caption Generation (MLBCAP) to address these challenges by leveraging specialized LLMs for distinct sub-tasks. Our approach unfolds in three key modules: (Quality Assessment) We utilize multimodal LLMs to assess the quality of training data, enabling the filtration of low-quality captions. (Diverse Caption Generation) We then employ a strategy of fine-tuning/prompting multiple LLMs on the captioning task to generate candidate captions. (Judgment) Lastly, we prompt a prominent LLM to select the highest quality caption from the candidates, followed by refining any remaining inaccuracies. Human evaluations demonstrate that informative captions produced by our approach rank better than human-written captions, highlighting its effectiveness. Our code is available at https://github.com/teamreboott/MLBCAP
CoCoLoFa: A Dataset of News Comments with Common Logical Fallacies Written by LLM-Assisted Crowds
Oct 04, 2024
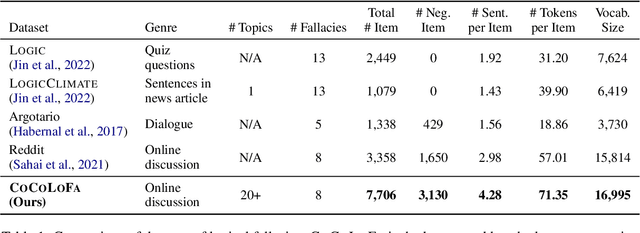
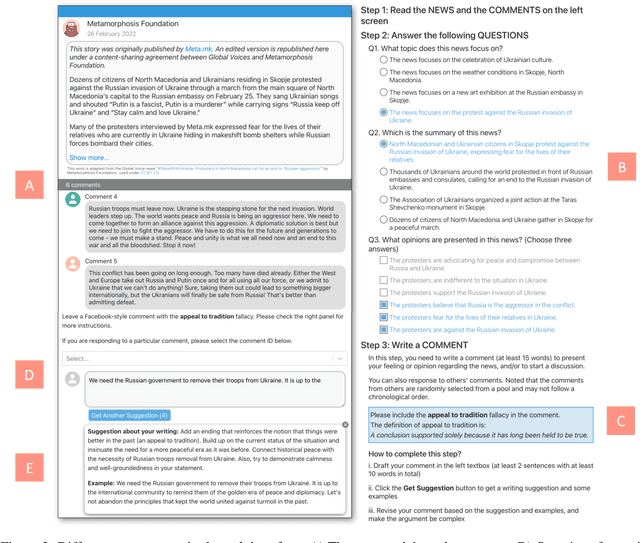
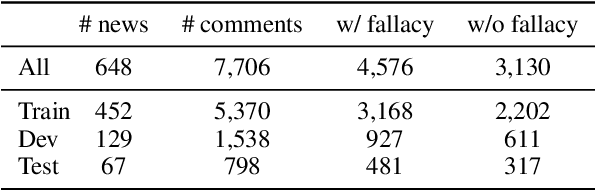
Detecting logical fallacies in texts can help users spot argument flaws, but automating this detection is not easy. Manually annotating fallacies in large-scale, real-world text data to create datasets for developing and validating detection models is costly. This paper introduces CoCoLoFa, the largest known logical fallacy dataset, containing 7,706 comments for 648 news articles, with each comment labeled for fallacy presence and type. We recruited 143 crowd workers to write comments embodying specific fallacy types (e.g., slippery slope) in response to news articles. Recognizing the complexity of this writing task, we built an LLM-powered assistant into the workers' interface to aid in drafting and refining their comments. Experts rated the writing quality and labeling validity of CoCoLoFa as high and reliable. BERT-based models fine-tuned using CoCoLoFa achieved the highest fallacy detection (F1=0.86) and classification (F1=0.87) performance on its test set, outperforming the state-of-the-art LLMs. Our work shows that combining crowdsourcing and LLMs enables us to more effectively construct datasets for complex linguistic phenomena that crowd workers find challenging to produce on their own.
What Color Scheme is More Effective in Assisting Readers to Locate Information in a Color-Coded Article?
Aug 12, 2024
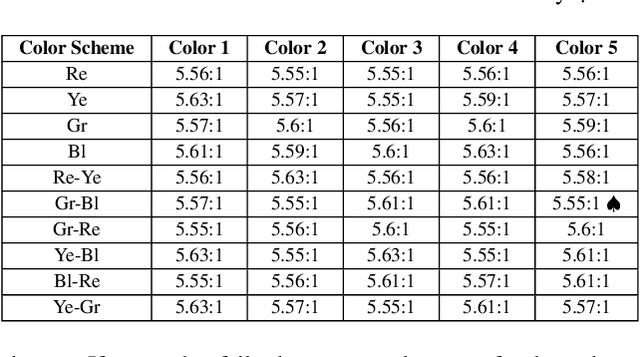
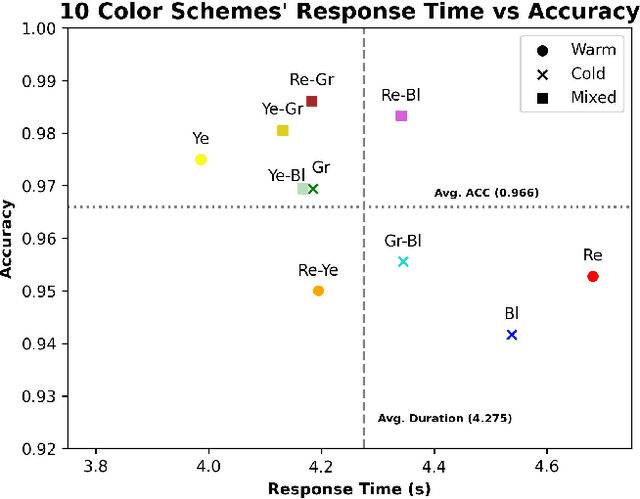
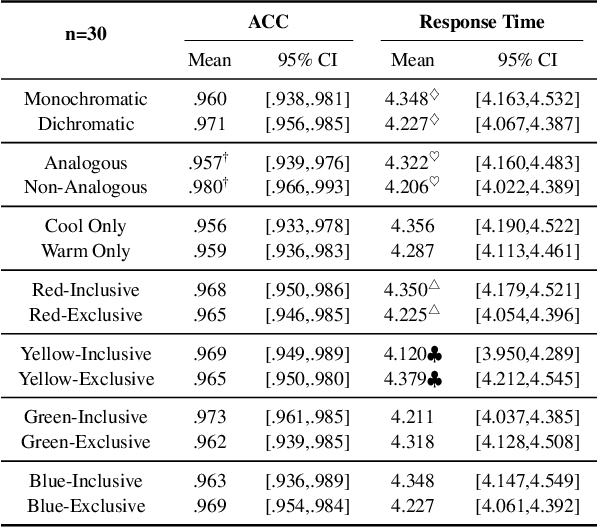
Color coding, a technique assigning specific colors to cluster information types, has proven advantages in aiding human cognitive activities, especially reading and comprehension. The rise of Large Language Models (LLMs) has streamlined document coding, enabling simple automatic text labeling with various schemes. This has the potential to make color-coding more accessible and benefit more users. However, the impact of color choice on information seeking is understudied. We conducted a user study assessing various color schemes' effectiveness in LLM-coded text documents, standardizing contrast ratios to approximately 5.55:1 across schemes. Participants performed timed information-seeking tasks in color-coded scholarly abstracts. Results showed non-analogous and yellow-inclusive color schemes improved performance, with the latter also being more preferred by participants. These findings can inform better color scheme choices for text annotation. As LLMs advance document coding, we advocate for more research focusing on the "color" aspect of color-coding techniques.
Generating Educational Materials with Different Levels of Readability using LLMs
Jun 18, 2024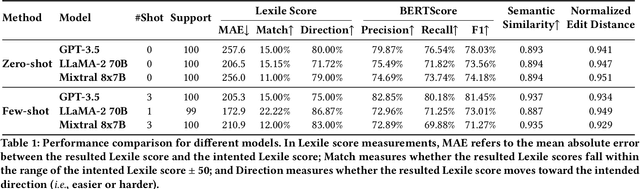
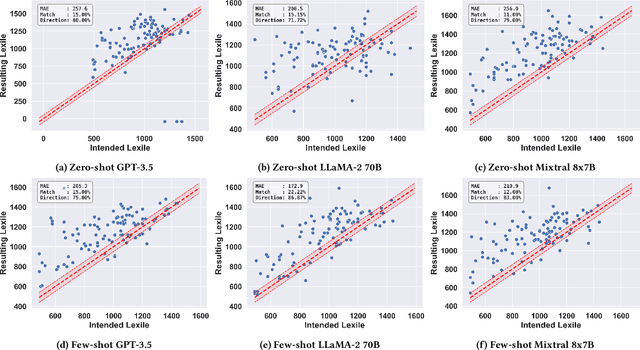
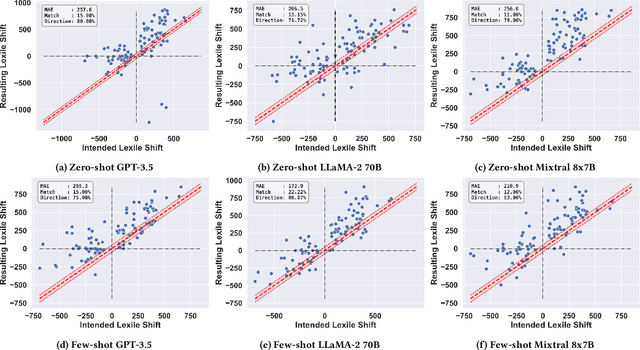
This study introduces the leveled-text generation task, aiming to rewrite educational materials to specific readability levels while preserving meaning. We assess the capability of GPT-3.5, LLaMA-2 70B, and Mixtral 8x7B, to generate content at various readability levels through zero-shot and few-shot prompting. Evaluating 100 processed educational materials reveals that few-shot prompting significantly improves performance in readability manipulation and information preservation. LLaMA-2 70B performs better in achieving the desired difficulty range, while GPT-3.5 maintains original meaning. However, manual inspection highlights concerns such as misinformation introduction and inconsistent edit distribution. These findings emphasize the need for further research to ensure the quality of generated educational content.
If in a Crowdsourced Data Annotation Pipeline, a GPT-4
Feb 26, 2024



Recent studies indicated GPT-4 outperforms online crowd workers in data labeling accuracy, notably workers from Amazon Mechanical Turk (MTurk). However, these studies were criticized for deviating from standard crowdsourcing practices and emphasizing individual workers' performances over the whole data-annotation process. This paper compared GPT-4 and an ethical and well-executed MTurk pipeline, with 415 workers labeling 3,177 sentence segments from 200 scholarly articles using the CODA-19 scheme. Two worker interfaces yielded 127,080 labels, which were then used to infer the final labels through eight label-aggregation algorithms. Our evaluation showed that despite best practices, MTurk pipeline's highest accuracy was 81.5%, whereas GPT-4 achieved 83.6%. Interestingly, when combining GPT-4's labels with crowd labels collected via an advanced worker interface for aggregation, 2 out of the 8 algorithms achieved an even higher accuracy (87.5%, 87.0%). Further analysis suggested that, when the crowd's and GPT-4's labeling strengths are complementary, aggregating them could increase labeling accuracy.
Good Data, Large Data, or No Data? Comparing Three Approaches in Developing Research Aspect Classifiers for Biomedical Papers
Jun 07, 2023The rapid growth of scientific publications, particularly during the COVID-19 pandemic, emphasizes the need for tools to help researchers efficiently comprehend the latest advancements. One essential part of understanding scientific literature is research aspect classification, which categorizes sentences in abstracts to Background, Purpose, Method, and Finding. In this study, we investigate the impact of different datasets on model performance for the crowd-annotated CODA-19 research aspect classification task. Specifically, we explore the potential benefits of using the large, automatically curated PubMed 200K RCT dataset and evaluate the effectiveness of large language models (LLMs), such as LLaMA, GPT-3, ChatGPT, and GPT-4. Our results indicate that using the PubMed 200K RCT dataset does not improve performance for the CODA-19 task. We also observe that while GPT-4 performs well, it does not outperform the SciBERT model fine-tuned on the CODA-19 dataset, emphasizing the importance of a dedicated and task-aligned datasets dataset for the target task. Our code is available at https://github.com/Crowd-AI-Lab/CODA-19-exp.