 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Model Synthesis Architectures: A Case Study
May 10, 2026Medicine is rife with high-stakes uncertainty. Doctors routinely make clinical judgments and decisions that juggle many fundamental unknowns, like predictions about what might be causing a patients' symptoms or decisions about what treatment to try next. Despite increasing interest in developing AI systems that aid or even replace doctors in clinical settings, current systems struggle with calibrated reasoning under uncertainty, and are often deeply opaque about their reasoning. We propose a framework for AI systems that can make practically useful but formally transparent clinical predictions under uncertainty. Given a clinical situation, our framework (MedMSA) uses language models to retrieve relevant prior knowledge, but constructs a formal probabilistic model to support calibrated and verifiable inferences under uncertainty. We show how an initial proof-of-concept of this framework can be used for differential diagnosis, producing an uncertainty-weighted list of potential diagnoses that could explain a patients' symptoms, and discuss future applications and directions for applying this framework more generally for safe clinical collaborations.
Prefix Parsing is Just Parsing
Apr 23, 2026Prefix parsing asks whether an input prefix can be extended to a complete string generated by a given grammar. In the weighted setting, it also provides prefix probabilities, which are central to context-free language modeling, psycholinguistic analysis, and syntactically constrained generation from large language models. We introduce the prefix grammar transformation, an efficient reduction of prefix parsing to ordinary parsing. Given a grammar, our method constructs another grammar that generates exactly the prefixes of its original strings. Prefix parsing is then solved by applying any ordinary parsing algorithm on the transformed grammar without modification. The reduction is both elegant and practical: the transformed grammar is only a small factor larger than the input, and any optimized implementation can be used directly, eliminating the need for bespoke prefix-parsing algorithms. We also present a strategy-based on algorithmic differentiation-for computing the next-token weight vector, i.e., the prefix weights of all one-token extensions, enabling efficient prediction of the next token. Together, these contributions yield a simple, general, and efficient framework for prefix parsing.
Ensembling Language Models with Sequential Monte Carlo
Mar 05, 2026Practitioners have access to an abundance of language models and prompting strategies for solving many language modeling tasks; yet prior work shows that modeling performance is highly sensitive to both choices. Classical machine learning ensembling techniques offer a principled approach: aggregate predictions from multiple sources to achieve better performance than any single one. However, applying ensembling to language models during decoding is challenging: naively aggregating next-token probabilities yields samples from a locally normalized, biased approximation of the generally intractable ensemble distribution over strings. In this work, we introduce a unified framework for composing $K$ language models into $f$-ensemble distributions for a wide range of functions $f\colon\mathbb{R}_{\geq 0}^{K}\to\mathbb{R}_{\geq 0}$. To sample from these distributions, we propose a byte-level sequential Monte Carlo (SMC) algorithm that operates in a shared character space, enabling ensembles of models with mismatching vocabularies and consistent sampling in the limit. We evaluate a family of $f$-ensembles across prompt and model combinations for various structured text generation tasks, highlighting the benefits of alternative aggregation strategies over traditional probability averaging, and showing that better posterior approximations can yield better ensemble performance.
Language Models over Canonical Byte-Pair Encodings
Jun 09, 2025Modern language models represent probability distributions over character strings as distributions over (shorter) token strings derived via a deterministic tokenizer, such as byte-pair encoding. While this approach is highly effective at scaling up language models to large corpora, its current incarnations have a concerning property: the model assigns nonzero probability mass to an exponential number of $\it{noncanonical}$ token encodings of each character string -- these are token strings that decode to valid character strings but are impossible under the deterministic tokenizer (i.e., they will never be seen in any training corpus, no matter how large). This misallocation is both erroneous, as noncanonical strings never appear in training data, and wasteful, diverting probability mass away from plausible outputs. These are avoidable mistakes! In this work, we propose methods to enforce canonicality in token-level language models, ensuring that only canonical token strings are assigned positive probability. We present two approaches: (1) canonicality by conditioning, leveraging test-time inference strategies without additional training, and (2) canonicality by construction, a model parameterization that guarantees canonical outputs but requires training. We demonstrate that fixing canonicality mistakes improves the likelihood of held-out data for several models and corpora.
Information Locality as an Inductive Bias for Neural Language Models
Jun 05, 2025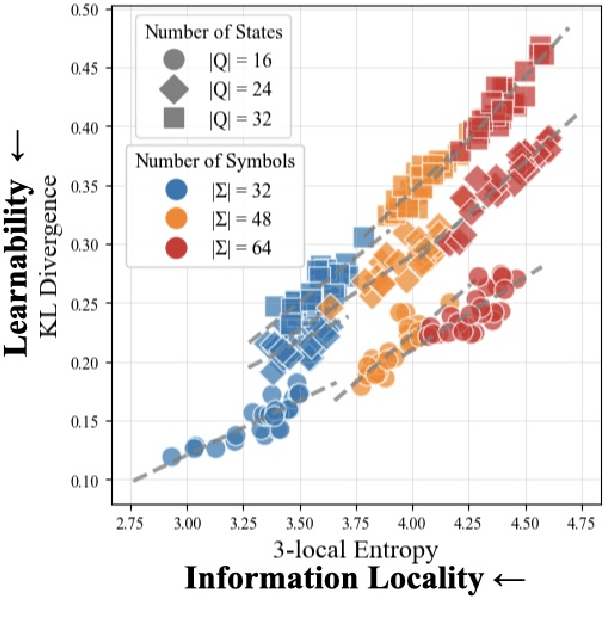
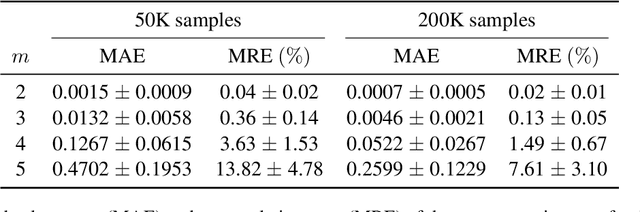
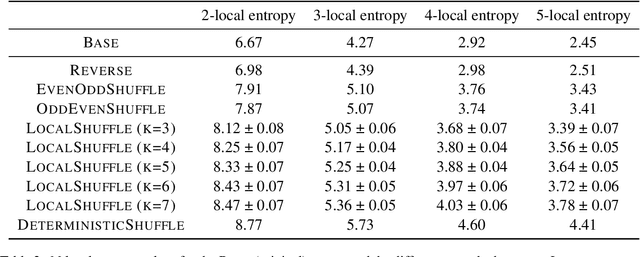
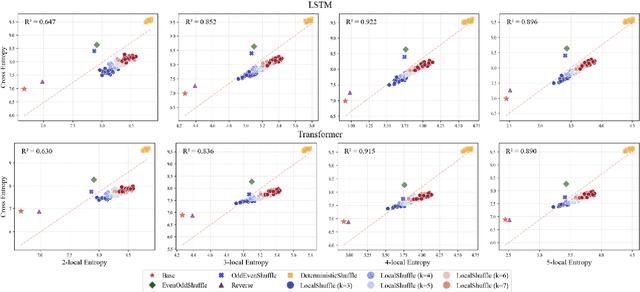
Inductive biases are inherent in every machine learning system, shaping how models generalize from finite data. In the case of neural language models (LMs), debates persist as to whether these biases align with or diverge from human processing constraints. To address this issue, we propose a quantitative framework that allows for controlled investigations into the nature of these biases. Within our framework, we introduce $m$-local entropy$\unicode{x2013}$an information-theoretic measure derived from average lossy-context surprisal$\unicode{x2013}$that captures the local uncertainty of a language by quantifying how effectively the $m-1$ preceding symbols disambiguate the next symbol. In experiments on both perturbed natural language corpora and languages defined by probabilistic finite-state automata (PFSAs), we show that languages with higher $m$-local entropy are more difficult for Transformer and LSTM LMs to learn. These results suggest that neural LMs, much like humans, are highly sensitive to the local statistical structure of a language.
Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo
Apr 18, 2025



A wide range of LM applications require generating text that conforms to syntactic or semantic constraints. Imposing such constraints can be naturally framed as probabilistic conditioning, but exact generation from the resulting distribution -- which can differ substantially from the LM's base distribution -- is generally intractable. In this work, we develop an architecture for controlled LM generation based on sequential Monte Carlo (SMC). Our SMC framework allows us to flexibly incorporate domain- and problem-specific constraints at inference time, and efficiently reallocate computational resources in light of new information during the course of generation. By comparing to a number of alternatives and ablations on four challenging domains -- Python code generation for data science, text-to-SQL, goal inference, and molecule synthesis -- we demonstrate that, with little overhead, our approach allows small open-source language models to outperform models over 8x larger, as well as closed-source, fine-tuned ones. In support of the probabilistic perspective, we show that these performance improvements are driven by better approximation to the posterior distribution. Our system builds on the framework of Lew et al. (2023) and integrates with its language model probabilistic programming language, giving users a simple, programmable way to apply SMC to a broad variety of controlled generation problems.
Unsupervised Classification of English Words Based on Phonological Information: Discovery of Germanic and Latinate Clusters
Apr 16, 2025Cross-linguistically, native words and loanwords follow different phonological rules. In English, for example, words of Germanic and Latinate origin exhibit different stress patterns, and a certain syntactic structure is exclusive to Germanic verbs. When seeing them as a cognitive model, however, such etymology-based generalizations face challenges in terms of learnability, since the historical origins of words are presumably inaccessible information for general language learners. In this study, we present computational evidence indicating that the Germanic-Latinate distinction in the English lexicon is learnable from the phonotactic information of individual words. Specifically, we performed an unsupervised clustering on corpus-extracted words, and the resulting word clusters largely aligned with the etymological distinction. The model-discovered clusters also recovered various linguistic generalizations documented in the previous literature regarding the corresponding etymological classes. Moreover, our findings also uncovered previously unrecognized features of the quasi-etymological clusters, offering novel hypotheses for future experimental studies.
Fast Controlled Generation from Language Models with Adaptive Weighted Rejection Sampling
Apr 07, 2025The dominant approach to generating from language models subject to some constraint is locally constrained decoding (LCD), incrementally sampling tokens at each time step such that the constraint is never violated. Typically, this is achieved through token masking: looping over the vocabulary and excluding non-conforming tokens. There are two important problems with this approach. (i) Evaluating the constraint on every token can be prohibitively expensive -- LM vocabularies often exceed $100,000$ tokens. (ii) LCD can distort the global distribution over strings, sampling tokens based only on local information, even if they lead down dead-end paths. This work introduces a new algorithm that addresses both these problems. First, to avoid evaluating a constraint on the full vocabulary at each step of generation, we propose an adaptive rejection sampling algorithm that typically requires orders of magnitude fewer constraint evaluations. Second, we show how this algorithm can be extended to produce low-variance, unbiased estimates of importance weights at a very small additional cost -- estimates that can be soundly used within previously proposed sequential Monte Carlo algorithms to correct for the myopic behavior of local constraint enforcement. Through extensive empirical evaluation in text-to-SQL, molecular synthesis, goal inference, pattern matching, and JSON domains, we show that our approach is superior to state-of-the-art baselines, supporting a broader class of constraints and improving both runtime and performance. Additional theoretical and empirical analyses show that our method's runtime efficiency is driven by its dynamic use of computation, scaling with the divergence between the unconstrained and constrained LM, and as a consequence, runtime improvements are greater for better models.
From Language Models over Tokens to Language Models over Characters
Dec 04, 2024Modern language models are internally -- and mathematically -- distributions over token strings rather than \emph{character} strings, posing numerous challenges for programmers building user applications on top of them. For example, if a prompt is specified as a character string, it must be tokenized before passing it to the token-level language model. Thus, the tokenizer and consequent analyses are very sensitive to the specification of the prompt (e.g., if the prompt ends with a space or not). This paper presents algorithms for converting token-level language models to character-level ones. We present both exact and approximate algorithms. In the empirical portion of the paper, we benchmark the practical runtime and approximation quality. We find that -- even with a small computation budget -- our method is able to accurately approximate the character-level distribution (less than 0.00021 excess bits / character) at reasonably fast speeds (46.3 characters / second) on the Llama 3.1 8B language model.
Reframing linguistic bootstrapping as joint inference using visually-grounded grammar induction models
Jun 17, 2024



Semantic and syntactic bootstrapping posit that children use their prior knowledge of one linguistic domain, say syntactic relations, to help later acquire another, such as the meanings of new words. Empirical results supporting both theories may tempt us to believe that these are different learning strategies, where one may precede the other. Here, we argue that they are instead both contingent on a more general learning strategy for language acquisition: joint learning. Using a series of neural visually-grounded grammar induction models, we demonstrate that both syntactic and semantic bootstrapping effects are strongest when syntax and semantics are learnt simultaneously. Joint learning results in better grammar induction, realistic lexical category learning, and better interpretations of novel sentence and verb meanings. Joint learning makes language acquisition easier for learners by mutually constraining the hypotheses spaces for both syntax and semantics. Studying the dynamics of joint inference over many input sources and modalities represents an important new direction for language modeling and learning research in both cognitive sciences and AI, as it may help us explain how language can be acquired in more constrained learning settings.