 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedPIT: Towards Privacy-preserving and Few-shot Federated Instruction Tuning
Mar 10, 2024



Instruction tuning has proven essential for enhancing the performance of large language models (LLMs) in generating human-aligned responses. However, collecting diverse, high-quality instruction data for tuning poses challenges, particularly in privacy-sensitive domains. Federated instruction tuning (FedIT) has emerged as a solution, leveraging federated learning from multiple data owners while preserving privacy. Yet, it faces challenges due to limited instruction data and vulnerabilities to training data extraction attacks. To address these issues, we propose a novel federated algorithm, FedPIT, which utilizes LLMs' in-context learning capability to self-generate task-specific synthetic data for training autonomously. Our method employs parameter-isolated training to maintain global parameters trained on synthetic data and local parameters trained on augmented local data, effectively thwarting data extraction attacks. Extensive experiments on real-world medical data demonstrate the effectiveness of FedPIT in improving federated few-shot performance while preserving privacy and robustness against data heterogeneity.
RENOVI: A Benchmark Towards Remediating Norm Violations in Socio-Cultural Conversations
Feb 17, 2024



Norm violations occur when individuals fail to conform to culturally accepted behaviors, which may lead to potential conflicts. Remediating norm violations requires social awareness and cultural sensitivity of the nuances at play. To equip interactive AI systems with a remediation ability, we offer ReNoVi - a large-scale corpus of 9,258 multi-turn dialogues annotated with social norms, as well as define a sequence of tasks to help understand and remediate norm violations step by step. ReNoVi consists of two parts: 512 human-authored dialogues (real data), and 8,746 synthetic conversations generated by ChatGPT through prompt learning. While collecting sufficient human-authored data is costly, synthetic conversations provide suitable amounts of data to help mitigate the scarcity of training data, as well as the chance to assess the alignment between LLMs and humans in the awareness of social norms. We thus harness the power of ChatGPT to generate synthetic training data for our task. To ensure the quality of both human-authored and synthetic data, we follow a quality control protocol during data collection. Our experimental results demonstrate the importance of remediating norm violations in socio-cultural conversations, as well as the improvement in performance obtained from synthetic data.
Let's Negotiate! A Survey of Negotiation Dialogue Systems
Feb 02, 2024
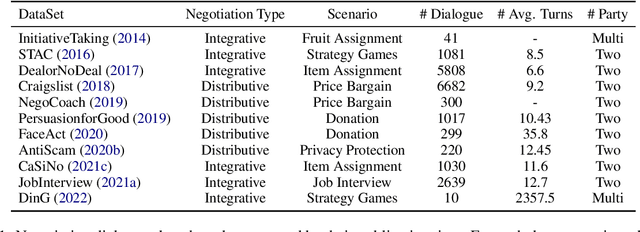


Negotiation is a crucial ability in human communication. Recently, there has been a resurgent research interest in negotiation dialogue systems, whose goal is to create intelligent agents that can assist people in resolving conflicts or reaching agreements. Although there have been many explorations into negotiation dialogue systems, a systematic review of this task has not been performed to date. We aim to fill this gap by investigating recent studies in the field of negotiation dialogue systems, and covering benchmarks, evaluations and methodologies within the literature. We also discuss potential future directions, including multi-modal, multi-party and cross-cultural negotiation scenarios. Our goal is to provide the community with a systematic overview of negotiation dialogue systems and to inspire future research.
SADAS: A Dialogue Assistant System Towards Remediating Norm Violations in Bilingual Socio-Cultural Conversations
Jan 29, 2024In today's globalized world, bridging the cultural divide is more critical than ever for forging meaningful connections. The Socially-Aware Dialogue Assistant System (SADAS) is our answer to this global challenge, and it's designed to ensure that conversations between individuals from diverse cultural backgrounds unfold with respect and understanding. Our system's novel architecture includes: (1) identifying the categories of norms present in the dialogue, (2) detecting potential norm violations, (3) evaluating the severity of these violations, (4) implementing targeted remedies to rectify the breaches, and (5) articulates the rationale behind these corrective actions. We employ a series of State-Of-The-Art (SOTA) techniques to build different modules, and conduct numerous experiments to select the most suitable backbone model for each of the modules. We also design a human preference experiment to validate the overall performance of the system. We will open-source our system (including source code, tools and applications), hoping to advance future research. A demo video of our system can be found at:~\url{https://youtu.be/JqetWkfsejk}. We have released our code and software at:~\url{https://github.com/AnonymousEACLDemo/SADAS}.
Assistive Large Language Model Agents for Socially-Aware Negotiation Dialogues
Jan 29, 2024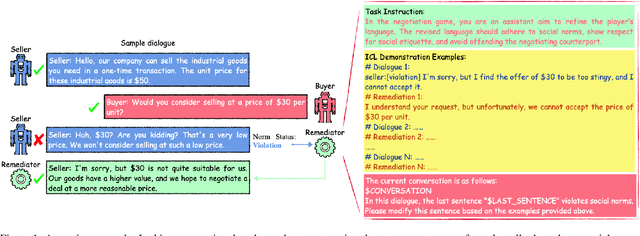
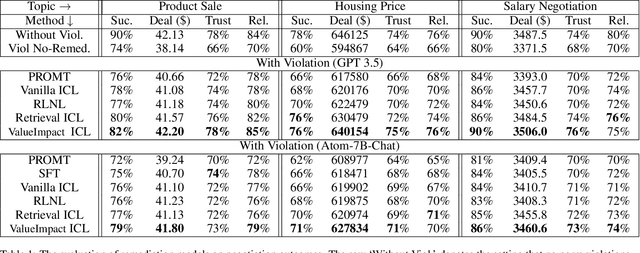
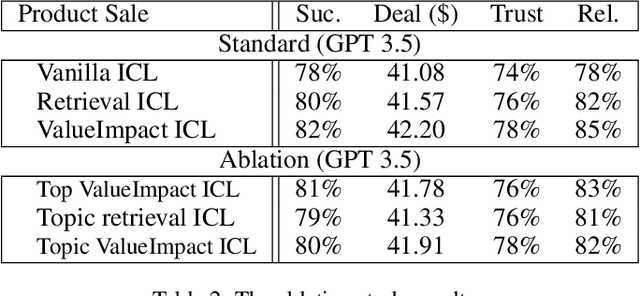

In this work, we aim to develop LLM agents to mitigate social norm violations in negotiations in a multi-agent setting. We simulate real-world negotiations by letting two large Language Models (LLMs) play the roles of two negotiators in each conversation. A third LLM acts as a remediation agent to rewrite utterances violating norms for improving negotiation outcomes. As it is a novel task, no manually constructed data is available. To address this limitation, we introduce a value impact based In-Context Learning (ICL) method to identify high-quality ICL examples for the LLM-based remediation agents, where the value impact function measures the quality of negotiation outcomes. We show the connection of this method to policy learning and provide rich empirical evidence to demonstrate its effectiveness in negotiations across three different topics: product sale, housing price, and salary negotiation. The source code and the generated dataset will be publicly available upon acceptance.
Importance-Aware Data Augmentation for Document-Level Neural Machine Translation
Jan 27, 2024


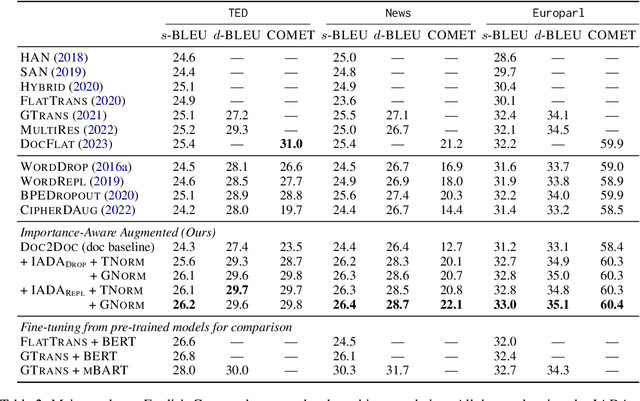
Document-level neural machine translation (DocNMT) aims to generate translations that are both coherent and cohesive, in contrast to its sentence-level counterpart. However, due to its longer input length and limited availability of training data, DocNMT often faces the challenge of data sparsity. To overcome this issue, we propose a novel Importance-Aware Data Augmentation (IADA) algorithm for DocNMT that augments the training data based on token importance information estimated by the norm of hidden states and training gradients. We conduct comprehensive experiments on three widely-used DocNMT benchmarks. Our empirical results show that our proposed IADA outperforms strong DocNMT baselines as well as several data augmentation approaches, with statistical significance on both sentence-level and document-level BLEU.
Adapting Large Language Models for Document-Level Machine Translation
Jan 12, 2024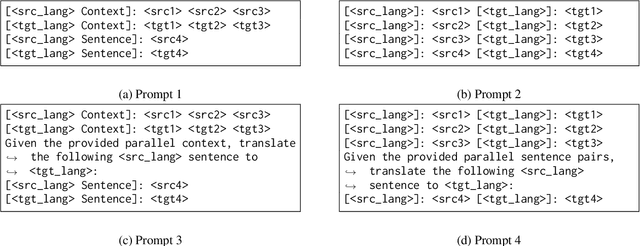
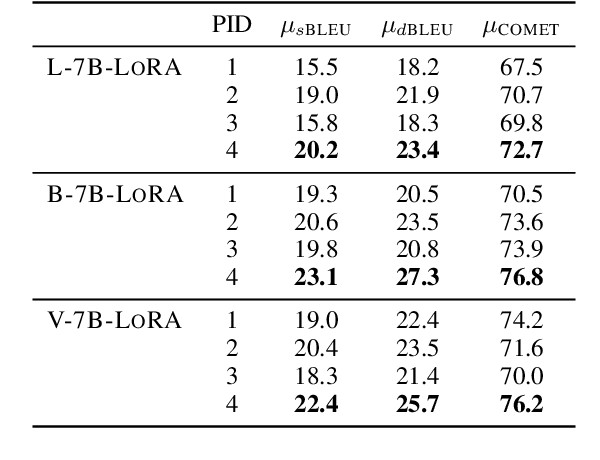
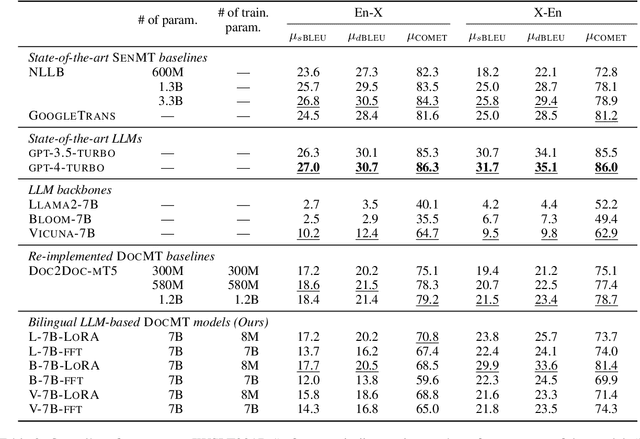
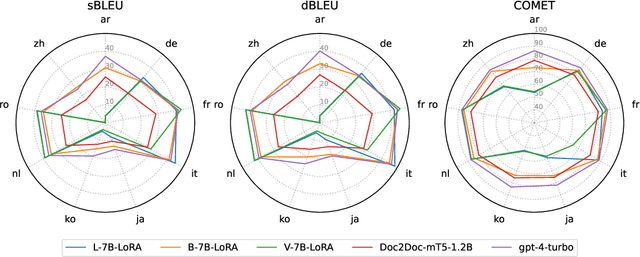
Large language models (LLMs) have made significant strides in various natural language processing (NLP) tasks. Recent research shows that the moderately-sized LLMs often outperform their larger counterparts after task-specific fine-tuning. In this work, we delve into the process of adapting LLMs to specialize in document-level machine translation (DocMT) for a specific language pair. Firstly, we explore how prompt strategies affect downstream translation performance. Then, we conduct extensive experiments with two fine-tuning methods, three LLM backbones, and 18 translation tasks across nine language pairs. Our findings indicate that in some cases, these specialized models even surpass GPT-4 in translation performance, while they still significantly suffer from the off-target translation issue in others, even if they are exclusively fine-tuned on bilingual parallel documents. Furthermore, we provide an in-depth analysis of these LLMs tailored for DocMT, exploring aspects such as translation errors, the scaling law of parallel documents, out-of-domain generalization, and the impact of zero-shot crosslingual transfer. The findings of this research not only shed light on the strengths and limitations of LLM-based DocMT models but also provide a foundation for future research in DocMT.
TMID: A Comprehensive Real-world Dataset for Trademark Infringement Detection in E-Commerce
Dec 08, 2023Annually, e-commerce platforms incur substantial financial losses due to trademark infringements, making it crucial to identify and mitigate potential legal risks tied to merchant information registered to the platforms. However, the absence of high-quality datasets hampers research in this area. To address this gap, our study introduces TMID, a novel dataset to detect trademark infringement in merchant registrations. This is a real-world dataset sourced directly from Alipay, one of the world's largest e-commerce and digital payment platforms. As infringement detection is a legal reasoning task requiring an understanding of the contexts and legal rules, we offer a thorough collection of legal rules and merchant and trademark-related contextual information with annotations from legal experts. We ensure the data quality by performing an extensive statistical analysis. Furthermore, we conduct an empirical study on this dataset to highlight its value and the key challenges. Through this study, we aim to contribute valuable resources to advance research into legal compliance related to trademark infringement within the e-commerce sphere. The dataset is available at https://github.com/emnlpTMID/emnlpTMID.github.io .
Can ChatGPT Perform Reasoning Using the IRAC Method in Analyzing Legal Scenarios Like a Lawyer?
Nov 03, 2023



Large Language Models (LLMs), such as ChatGPT, have drawn a lot of attentions recently in the legal domain due to its emergent ability to tackle a variety of legal tasks. However, it is still unknown if LLMs are able to analyze a legal case and perform reasoning in the same manner as lawyers. Therefore, we constructed a novel corpus consisting of scenarios pertain to Contract Acts Malaysia and Australian Social Act for Dependent Child. ChatGPT is applied to perform analysis on the corpus using the IRAC method, which is a framework widely used by legal professionals for organizing legal analysis. Each scenario in the corpus is annotated with a complete IRAC analysis in a semi-structured format so that both machines and legal professionals are able to interpret and understand the annotations. In addition, we conducted the first empirical assessment of ChatGPT for IRAC analysis in order to understand how well it aligns with the analysis of legal professionals. Our experimental results shed lights on possible future research directions to improve alignments between LLMs and legal experts in terms of legal reasoning.
FACTUAL: A Benchmark for Faithful and Consistent Textual Scene Graph Parsing
Jun 01, 2023



Textual scene graph parsing has become increasingly important in various vision-language applications, including image caption evaluation and image retrieval. However, existing scene graph parsers that convert image captions into scene graphs often suffer from two types of errors. First, the generated scene graphs fail to capture the true semantics of the captions or the corresponding images, resulting in a lack of faithfulness. Second, the generated scene graphs have high inconsistency, with the same semantics represented by different annotations. To address these challenges, we propose a novel dataset, which involves re-annotating the captions in Visual Genome (VG) using a new intermediate representation called FACTUAL-MR. FACTUAL-MR can be directly converted into faithful and consistent scene graph annotations. Our experimental results clearly demonstrate that the parser trained on our dataset outperforms existing approaches in terms of faithfulness and consistency. This improvement leads to a significant performance boost in both image caption evaluation and zero-shot image retrieval tasks. Furthermore, we introduce a novel metric for measuring scene graph similarity, which, when combined with the improved scene graph parser, achieves state-of-the-art (SOTA) results on multiple benchmark datasets for the aforementioned tasks. The code and dataset are available at https://github.com/zhuang-li/FACTUAL .