 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgestylegan
Papers and Code
Lung Nodule Image Synthesis Driven by Two-Stage Generative Adversarial Networks
Feb 02, 2026The limited sample size and insufficient diversity of lung nodule CT datasets severely restrict the performance and generalization ability of detection models. Existing methods generate images with insufficient diversity and controllability, suffering from issues such as monotonous texture features and distorted anatomical structures. Therefore, we propose a two-stage generative adversarial network (TSGAN) to enhance the diversity and spatial controllability of synthetic data by decoupling the morphological structure and texture features of lung nodules. In the first stage, StyleGAN is used to generate semantic segmentation mask images, encoding lung nodules and tissue backgrounds to control the anatomical structure of lung nodule images; The second stage uses the DL-Pix2Pix model to translate the mask map into CT images, employing local importance attention to capture local features, while utilizing dynamic weight multi-head window attention to enhance the modeling capability of lung nodule texture and background. Compared to the original dataset, the accuracy improved by 4.6% and mAP by 4% on the LUNA16 dataset. Experimental results demonstrate that TSGAN can enhance the quality of synthetic images and the performance of detection models.
SelfieAvatar: Real-time Head Avatar reenactment from a Selfie Video
Jan 26, 2026Head avatar reenactment focuses on creating animatable personal avatars from monocular videos, serving as a foundational element for applications like social signal understanding, gaming, human-machine interaction, and computer vision. Recent advances in 3D Morphable Model (3DMM)-based facial reconstruction methods have achieved remarkable high-fidelity face estimation. However, on the one hand, they struggle to capture the entire head, including non-facial regions and background details in real time, which is an essential aspect for producing realistic, high-fidelity head avatars. On the other hand, recent approaches leveraging generative adversarial networks (GANs) for head avatar generation from videos can achieve high-quality reenactments but encounter limitations in reproducing fine-grained head details, such as wrinkles and hair textures. In addition, existing methods generally rely on a large amount of training data, and rarely focus on using only a simple selfie video to achieve avatar reenactment. To address these challenges, this study introduces a method for detailed head avatar reenactment using a selfie video. The approach combines 3DMMs with a StyleGAN-based generator. A detailed reconstruction model is proposed, incorporating mixed loss functions for foreground reconstruction and avatar image generation during adversarial training to recover high-frequency details. Qualitative and quantitative evaluations on self-reenactment and cross-reenactment tasks demonstrate that the proposed method achieves superior head avatar reconstruction with rich and intricate textures compared to existing approaches.
IGAN: A New Inception-based Model for Stable and High-Fidelity Image Synthesis Using Generative Adversarial Networks
Jan 13, 2026Generative Adversarial Networks (GANs) face a significant challenge of striking an optimal balance between high-quality image generation and training stability. Recent techniques, such as DCGAN, BigGAN, and StyleGAN, improve visual fidelity; however, such techniques usually struggle with mode collapse and unstable gradients at high network depth. This paper proposes a novel GAN structural model that incorporates deeper inception-inspired convolution and dilated convolution. This novel model is termed the Inception Generative Adversarial Network (IGAN). The IGAN model generates high-quality synthetic images while maintaining training stability, by reducing mode collapse as well as preventing vanishing and exploding gradients. Our proposed IGAN model achieves the Frechet Inception Distance (FID) of 13.12 and 15.08 on the CUB-200 and ImageNet datasets, respectively, representing a 28-33% improvement in FID over the state-of-the-art GANs. Additionally, the IGAN model attains an Inception Score (IS) of 9.27 and 68.25, reflecting improved image diversity and generation quality. Finally, the two techniques of dropout and spectral normalization are utilized in both the generator and discriminator structures to further mitigate gradient explosion and overfitting. These findings confirm that the IGAN model potentially balances training stability with image generation quality, constituting a scalable and computationally efficient framework for high-fidelity image synthesis.
Controllable Probabilistic Forecasting with Stochastic Decomposition Layers
Dec 21, 2025AI weather prediction ensembles with latent noise injection and optimized with the continuous ranked probability score (CRPS) have produced both accurate and well-calibrated predictions with far less computational cost compared with diffusion-based methods. However, current CRPS ensemble approaches vary in their training strategies and noise injection mechanisms, with most injecting noise globally throughout the network via conditional normalization. This structure increases training expense and limits the physical interpretability of the stochastic perturbations. We introduce Stochastic Decomposition Layers (SDL) for converting deterministic machine learning weather models into probabilistic ensemble systems. Adapted from StyleGAN's hierarchical noise injection, SDL applies learned perturbations at three decoder scales through latent-driven modulation, per-pixel noise, and channel scaling. When applied to WXFormer via transfer learning, SDL requires less than 2\% of the computational cost needed to train the baseline model. Each ensemble member is generated from a compact latent tensor (5 MB), enabling perfect reproducibility and post-inference spread adjustment through latent rescaling. Evaluation on 2022 ERA5 reanalysis shows ensembles with spread-skill ratios approaching unity and rank histograms that progressively flatten toward uniformity through medium-range forecasts, achieving calibration competitive with operational IFS-ENS. Multi-scale experiments reveal hierarchical uncertainty: coarse layers modulate synoptic patterns while fine layers control mesoscale variability. The explicit latent parameterization provides interpretable uncertainty quantification for operational forecasting and climate applications.
CLIP-FTI: Fine-Grained Face Template Inversion via CLIP-Driven Attribute Conditioning
Dec 17, 2025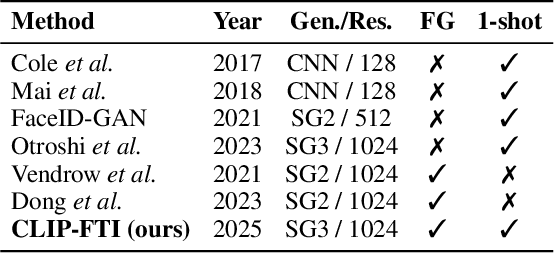
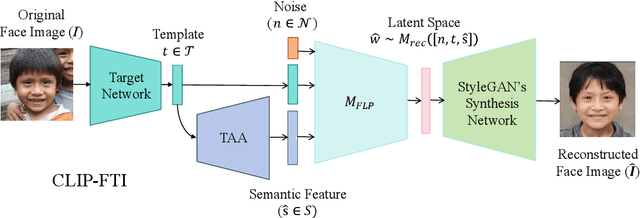
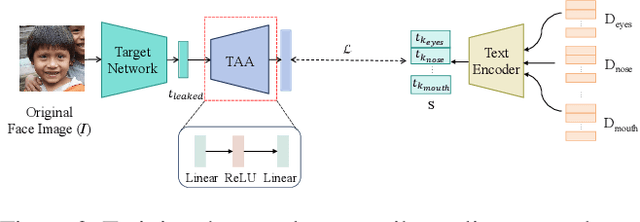
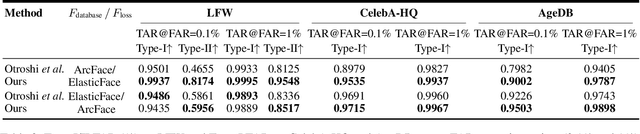
Face recognition systems store face templates for efficient matching. Once leaked, these templates pose a threat: inverting them can yield photorealistic surrogates that compromise privacy and enable impersonation. Although existing research has achieved relatively realistic face template inversion, the reconstructed facial images exhibit over-smoothed facial-part attributes (eyes, nose, mouth) and limited transferability. To address this problem, we present CLIP-FTI, a CLIP-driven fine-grained attribute conditioning framework for face template inversion. Our core idea is to use the CLIP model to obtain the semantic embeddings of facial features, in order to realize the reconstruction of specific facial feature attributes. Specifically, facial feature attribute embeddings extracted from CLIP are fused with the leaked template via a cross-modal feature interaction network and projected into the intermediate latent space of a pretrained StyleGAN. The StyleGAN generator then synthesizes face images with the same identity as the templates but with more fine-grained facial feature attributes. Experiments across multiple face recognition backbones and datasets show that our reconstructions (i) achieve higher identification accuracy and attribute similarity, (ii) recover sharper component-level attribute semantics, and (iii) improve cross-model attack transferability compared to prior reconstruction attacks. To the best of our knowledge, ours is the first method to use additional information besides the face template attack to realize face template inversion and obtains SOTA results.
A Multi-domain Image Translative Diffusion StyleGAN for Iris Presentation Attack Detection
Oct 16, 2025An iris biometric system can be compromised by presentation attacks (PAs) where artifacts such as artificial eyes, printed eye images, or cosmetic contact lenses are presented to the system. To counteract this, several presentation attack detection (PAD) methods have been developed. However, there is a scarcity of datasets for training and evaluating iris PAD techniques due to the implicit difficulties in constructing and imaging PAs. To address this, we introduce the Multi-domain Image Translative Diffusion StyleGAN (MID-StyleGAN), a new framework for generating synthetic ocular images that captures the PA and bonafide characteristics in multiple domains such as bonafide, printed eyes and cosmetic contact lens. MID-StyleGAN combines the strengths of diffusion models and generative adversarial networks (GANs) to produce realistic and diverse synthetic data. Our approach utilizes a multi-domain architecture that enables the translation between bonafide ocular images and different PA domains. The model employs an adaptive loss function tailored for ocular data to maintain domain consistency. Extensive experiments demonstrate that MID-StyleGAN outperforms existing methods in generating high-quality synthetic ocular images. The generated data was used to significantly enhance the performance of PAD systems, providing a scalable solution to the data scarcity problem in iris and ocular biometrics. For example, on the LivDet2020 dataset, the true detect rate at 1% false detect rate improved from 93.41% to 98.72%, showcasing the impact of the proposed method.
UCD: Unconditional Discriminator Promotes Nash Equilibrium in GANs
Oct 01, 2025Adversarial training turns out to be the key to one-step generation, especially for Generative Adversarial Network (GAN) and diffusion model distillation. Yet in practice, GAN training hardly converges properly and struggles in mode collapse. In this work, we quantitatively analyze the extent of Nash equilibrium in GAN training, and conclude that redundant shortcuts by inputting condition in $D$ disables meaningful knowledge extraction. We thereby propose to employ an unconditional discriminator (UCD), in which $D$ is enforced to extract more comprehensive and robust features with no condition injection. In this way, $D$ is able to leverage better knowledge to supervise $G$, which promotes Nash equilibrium in GAN literature. Theoretical guarantee on compatibility with vanilla GAN theory indicates that UCD can be implemented in a plug-in manner. Extensive experiments confirm the significant performance improvements with high efficiency. For instance, we achieved \textbf{1.47 FID} on the ImageNet-64 dataset, surpassing StyleGAN-XL and several state-of-the-art one-step diffusion models. The code will be made publicly available.
DragGANSpace: Latent Space Exploration and Control for GANs
Sep 26, 2025



This work integrates StyleGAN, DragGAN and Principal Component Analysis (PCA) to enhance the latent space efficiency and controllability of GAN-generated images. Style-GAN provides a structured latent space, DragGAN enables intuitive image manipulation, and PCA reduces dimensionality and facilitates cross-model alignment for more streamlined and interpretable exploration of latent spaces. We apply our techniques to the Animal Faces High Quality (AFHQ) dataset, and find that our approach of integrating PCA-based dimensionality reduction with the Drag-GAN framework for image manipulation retains performance while improving optimization efficiency. Notably, introducing PCA into the latent W+ layers of DragGAN can consistently reduce the total optimization time while maintaining good visual quality and even boosting the Structural Similarity Index Measure (SSIM) of the optimized image, particularly in shallower latent spaces (W+ layers = 3). We also demonstrate capability for aligning images generated by two StyleGAN models trained on similar but distinct data domains (AFHQ-Dog and AFHQ-Cat), and show that we can control the latent space of these aligned images to manipulate the images in an intuitive and interpretable manner. Our findings highlight the possibility for efficient and interpretable latent space control for a wide range of image synthesis and editing applications.
RaceGAN: A Framework for Preserving Individuality while Converting Racial Information for Image-to-Image Translation
Sep 18, 2025Generative adversarial networks (GANs) have demonstrated significant progress in unpaired image-to-image translation in recent years for several applications. CycleGAN was the first to lead the way, although it was restricted to a pair of domains. StarGAN overcame this constraint by tackling image-to-image translation across various domains, although it was not able to map in-depth low-level style changes for these domains. Style mapping via reference-guided image synthesis has been made possible by the innovations of StarGANv2 and StyleGAN. However, these models do not maintain individuality and need an extra reference image in addition to the input. Our study aims to translate racial traits by means of multi-domain image-to-image translation. We present RaceGAN, a novel framework capable of mapping style codes over several domains during racial attribute translation while maintaining individuality and high level semantics without relying on a reference image. RaceGAN outperforms other models in translating racial features (i.e., Asian, White, and Black) when tested on Chicago Face Dataset. We also give quantitative findings utilizing InceptionReNetv2-based classification to demonstrate the effectiveness of our racial translation. Moreover, we investigate how well the model partitions the latent space into distinct clusters of faces for each ethnic group.
Identity-Preserving Aging and De-Aging of Faces in the StyleGAN Latent Space
Aug 12, 2025Face aging or de-aging with generative AI has gained significant attention for its applications in such fields like forensics, security, and media. However, most state of the art methods rely on conditional Generative Adversarial Networks (GANs), Diffusion-based models, or Visual Language Models (VLMs) to age or de-age faces based on predefined age categories and conditioning via loss functions, fine-tuning, or text prompts. The reliance on such conditioning leads to complex training requirements, increased data needs, and challenges in generating consistent results. Additionally, identity preservation is rarely taken into accountor evaluated on a single face recognition system without any control or guarantees on whether identity would be preserved in a generated aged/de-aged face. In this paper, we propose to synthesize aged and de-aged faces via editing latent space of StyleGAN2 using a simple support vector modeling of aging/de-aging direction and several feature selection approaches. By using two state-of-the-art face recognition systems, we empirically find the identity preserving subspace within the StyleGAN2 latent space, so that an apparent age of a given face can changed while preserving the identity. We then propose a simple yet practical formula for estimating the limits on aging/de-aging parameters that ensures identity preservation for a given input face. Using our method and estimated parameters we have generated a public dataset of synthetic faces at different ages that can be used for benchmarking cross-age face recognition, age assurance systems, or systems for detection of synthetic images. Our code and dataset are available at the project page https://www.idiap.ch/paper/agesynth/