 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleDiT: A Unified Framework for Diverse Child and Partner Faces Synthesis with Style Latent Diffusion Transformer
Dec 14, 2024Kinship face synthesis is a challenging problem due to the scarcity and low quality of the available kinship data. Existing methods often struggle to generate descendants with both high diversity and fidelity while precisely controlling facial attributes such as age and gender. To address these issues, we propose the Style Latent Diffusion Transformer (StyleDiT), a novel framework that integrates the strengths of StyleGAN with the diffusion model to generate high-quality and diverse kinship faces. In this framework, the rich facial priors of StyleGAN enable fine-grained attribute control, while our conditional diffusion model is used to sample a StyleGAN latent aligned with the kinship relationship of conditioning images by utilizing the advantage of modeling complex kinship relationship distribution. StyleGAN then handles latent decoding for final face generation. Additionally, we introduce the Relational Trait Guidance (RTG) mechanism, enabling independent control of influencing conditions, such as each parent's facial image. RTG also enables a fine-grained adjustment between the diversity and fidelity in synthesized faces. Furthermore, we extend the application to an unexplored domain: predicting a partner's facial images using a child's image and one parent's image within the same framework. Extensive experiments demonstrate that our StyleDiT outperforms existing methods by striking an excellent balance between generating diverse and high-fidelity kinship faces.
ReActXGB: A Hybrid Binary Convolutional Neural Network Architecture for Improved Performance and Computational Efficiency
May 11, 2024
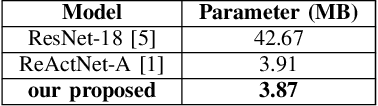
Binary convolutional neural networks (BCNNs) provide a potential solution to reduce the memory requirements and computational costs associated with deep neural networks (DNNs). However, achieving a trade-off between performance and computational resources remains a significant challenge. Furthermore, the fully connected layer of BCNNs has evolved into a significant computational bottleneck. This is mainly due to the conventional practice of excluding the input layer and fully connected layer from binarization to prevent a substantial loss in accuracy. In this paper, we propose a hybrid model named ReActXGB, where we replace the fully convolutional layer of ReActNet-A with XGBoost. This modification targets to narrow the performance gap between BCNNs and real-valued networks while maintaining lower computational costs. Experimental results on the FashionMNIST benchmark demonstrate that ReActXGB outperforms ReActNet-A by 1.47% in top-1 accuracy, along with a reduction of 7.14% in floating-point operations (FLOPs) and 1.02% in model size.