 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeccano
Papers and Code
Understanding Multimodal Complementarity for Single-Frame Action Anticipation
Jan 29, 2026Human action anticipation is commonly treated as a video understanding problem, implicitly assuming that dense temporal information is required to reason about future actions. In this work, we challenge this assumption by investigating what can be achieved when action anticipation is constrained to a single visual observation. We ask a fundamental question: how much information about the future is already encoded in a single frame, and how can it be effectively exploited? Building on our prior work on Action Anticipation at a Glimpse (AAG), we conduct a systematic investigation of single-frame action anticipation enriched with complementary sources of information. We analyze the contribution of RGB appearance, depth-based geometric cues, and semantic representations of past actions, and investigate how different multimodal fusion strategies, keyframe selection policies and past-action history sources influence anticipation performance. Guided by these findings, we consolidate the most effective design choices into AAG+, a refined single-frame anticipation framework. Despite operating on a single frame, AAG+ consistently improves upon the original AAG and achieves performance comparable to, or exceeding, that of state-of-the-art video-based methods on challenging anticipation benchmarks including IKEA-ASM, Meccano and Assembly101. Our results offer new insights into the limits and potential of single-frame action anticipation, and clarify when dense temporal modeling is necessary and when a carefully selected glimpse is sufficient.
Learning to Recognize Correctly Completed Procedure Steps in Egocentric Assembly Videos through Spatio-Temporal Modeling
Oct 14, 2025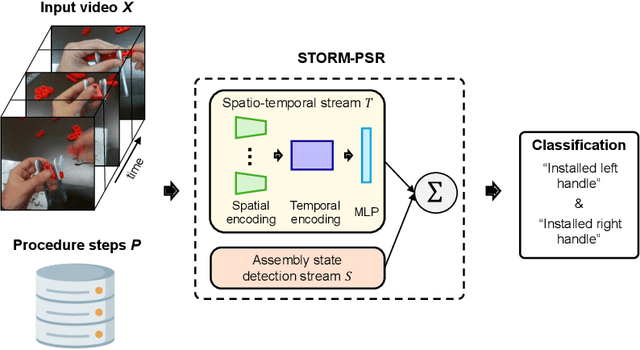
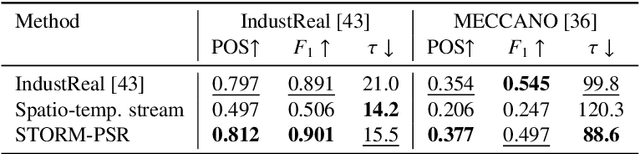
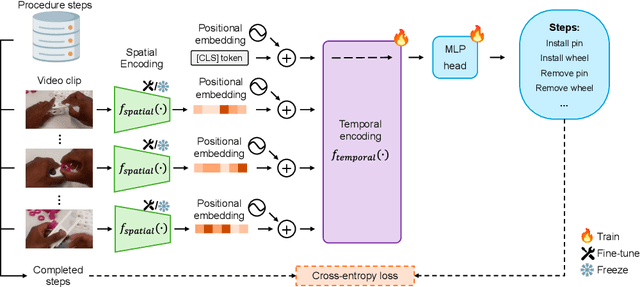
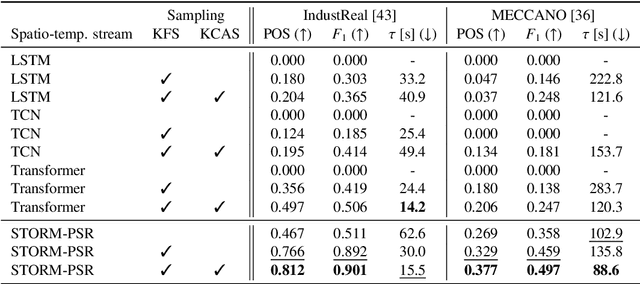
Procedure step recognition (PSR) aims to identify all correctly completed steps and their sequential order in videos of procedural tasks. The existing state-of-the-art models rely solely on detecting assembly object states in individual video frames. By neglecting temporal features, model robustness and accuracy are limited, especially when objects are partially occluded. To overcome these limitations, we propose Spatio-Temporal Occlusion-Resilient Modeling for Procedure Step Recognition (STORM-PSR), a dual-stream framework for PSR that leverages both spatial and temporal features. The assembly state detection stream operates effectively with unobstructed views of the object, while the spatio-temporal stream captures both spatial and temporal features to recognize step completions even under partial occlusion. This stream includes a spatial encoder, pre-trained using a novel weakly supervised approach to capture meaningful spatial representations, and a transformer-based temporal encoder that learns how these spatial features relate over time. STORM-PSR is evaluated on the MECCANO and IndustReal datasets, reducing the average delay between actual and predicted assembly step completions by 11.2% and 26.1%, respectively, compared to prior methods. We demonstrate that this reduction in delay is driven by the spatio-temporal stream, which does not rely on unobstructed views of the object to infer completed steps. The code for STORM-PSR, along with the newly annotated MECCANO labels, is made publicly available at https://timschoonbeek.github.io/stormpsr .
Optimizing Multitask Industrial Processes with Predictive Action Guidance
Jan 09, 2025



Monitoring complex assembly processes is critical for maintaining productivity and ensuring compliance with assembly standards. However, variability in human actions and subjective task preferences complicate accurate task anticipation and guidance. To address these challenges, we introduce the Multi-Modal Transformer Fusion and Recurrent Units (MMTFRU) Network for egocentric activity anticipation, utilizing multimodal fusion to improve prediction accuracy. Integrated with the Operator Action Monitoring Unit (OAMU), the system provides proactive operator guidance, preventing deviations in the assembly process. OAMU employs two strategies: (1) Top-5 MMTF-RU predictions, combined with a reference graph and an action dictionary, for next-step recommendations; and (2) Top-1 MMTF-RU predictions, integrated with a reference graph, for detecting sequence deviations and predicting anomaly scores via an entropy-informed confidence mechanism. We also introduce Time-Weighted Sequence Accuracy (TWSA) to evaluate operator efficiency and ensure timely task completion. Our approach is validated on the industrial Meccano dataset and the largescale EPIC-Kitchens-55 dataset, demonstrating its effectiveness in dynamic environments.
Active Object Detection with Knowledge Aggregation and Distillation from Large Models
May 21, 2024
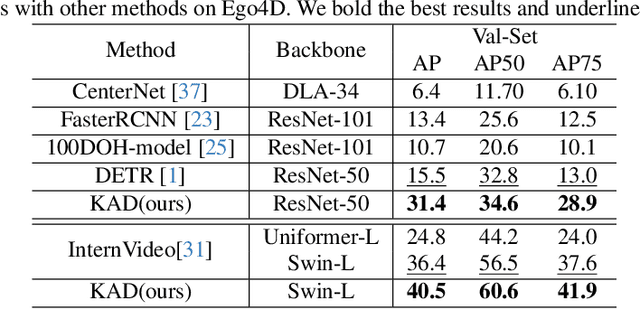
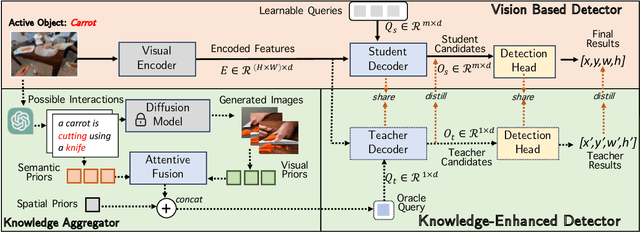

Accurately detecting active objects undergoing state changes is essential for comprehending human interactions and facilitating decision-making. The existing methods for active object detection (AOD) primarily rely on visual appearance of the objects within input, such as changes in size, shape and relationship with hands. However, these visual changes can be subtle, posing challenges, particularly in scenarios with multiple distracting no-change instances of the same category. We observe that the state changes are often the result of an interaction being performed upon the object, thus propose to use informed priors about object related plausible interactions (including semantics and visual appearance) to provide more reliable cues for AOD. Specifically, we propose a knowledge aggregation procedure to integrate the aforementioned informed priors into oracle queries within the teacher decoder, offering more object affordance commonsense to locate the active object. To streamline the inference process and reduce extra knowledge inputs, we propose a knowledge distillation approach that encourages the student decoder to mimic the detection capabilities of the teacher decoder using the oracle query by replicating its predictions and attention. Our proposed framework achieves state-of-the-art performance on four datasets, namely Ego4D, Epic-Kitchens, MECCANO, and 100DOH, which demonstrates the effectiveness of our approach in improving AOD.
Egocentric RGB+Depth Action Recognition in Industry-Like Settings
Sep 25, 2023
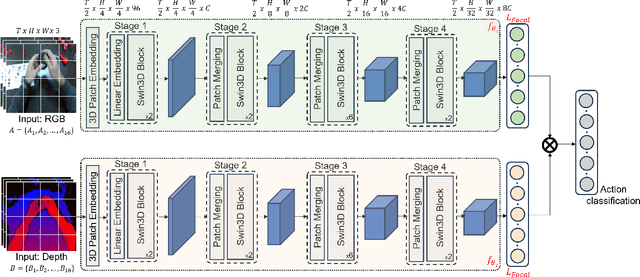
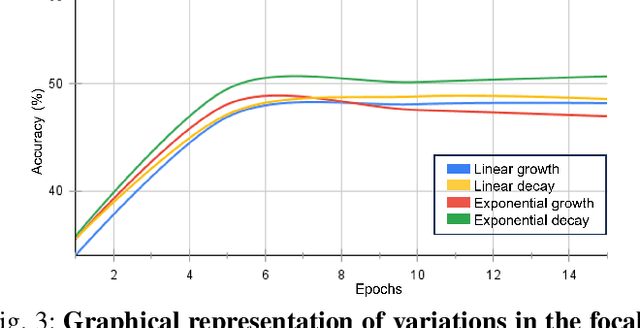
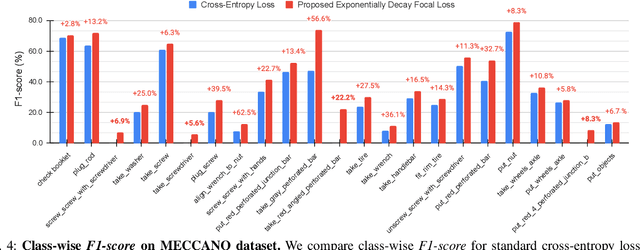
Action recognition from an egocentric viewpoint is a crucial perception task in robotics and enables a wide range of human-robot interactions. While most computer vision approaches prioritize the RGB camera, the Depth modality - which can further amplify the subtleties of actions from an egocentric perspective - remains underexplored. Our work focuses on recognizing actions from egocentric RGB and Depth modalities in an industry-like environment. To study this problem, we consider the recent MECCANO dataset, which provides a wide range of assembling actions. Our framework is based on the 3D Video SWIN Transformer to encode both RGB and Depth modalities effectively. To address the inherent skewness in real-world multimodal action occurrences, we propose a training strategy using an exponentially decaying variant of the focal loss modulating factor. Additionally, to leverage the information in both RGB and Depth modalities, we opt for late fusion to combine the predictions from each modality. We thoroughly evaluate our method on the action recognition task of the MECCANO dataset, and it significantly outperforms the prior work. Notably, our method also secured first place at the multimodal action recognition challenge at ICIAP 2023.
Ensemble Modeling for Multimodal Visual Action Recognition
Aug 10, 2023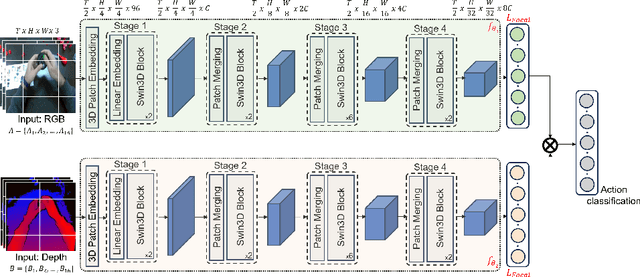
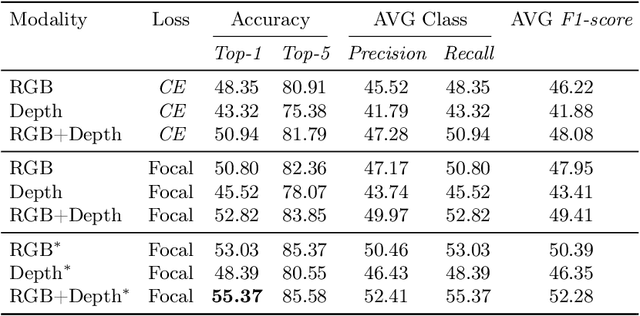
In this work, we propose an ensemble modeling approach for multimodal action recognition. We independently train individual modality models using a variant of focal loss tailored to handle the long-tailed distribution of the MECCANO [21] dataset. Based on the underlying principle of focal loss, which captures the relationship between tail (scarce) classes and their prediction difficulties, we propose an exponentially decaying variant of focal loss for our current task. It initially emphasizes learning from the hard misclassified examples and gradually adapts to the entire range of examples in the dataset. This annealing process encourages the model to strike a balance between focusing on the sparse set of hard samples, while still leveraging the information provided by the easier ones. Additionally, we opt for the late fusion strategy to combine the resultant probability distributions from RGB and Depth modalities for final action prediction. Experimental evaluations on the MECCANO dataset demonstrate the effectiveness of our approach.
MECCANO: A Multimodal Egocentric Dataset for Humans Behavior Understanding in the Industrial-like Domain
Sep 19, 2022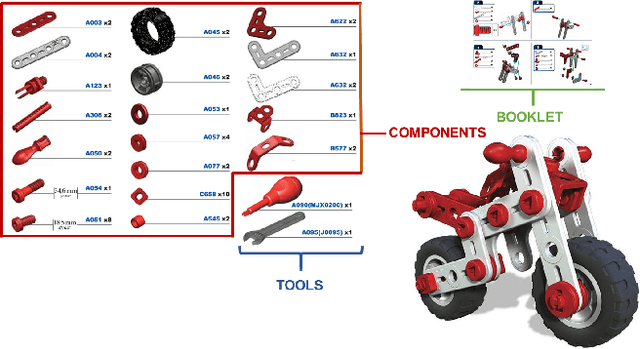
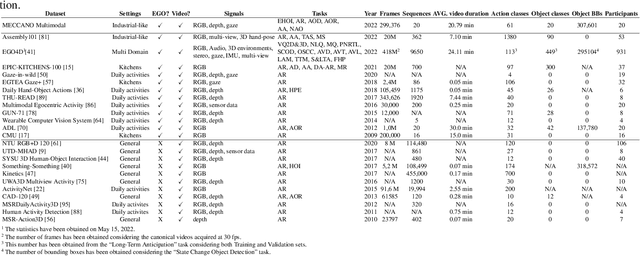


Wearable cameras allow to acquire images and videos from the user's perspective. These data can be processed to understand humans behavior. Despite human behavior analysis has been thoroughly investigated in third person vision, it is still understudied in egocentric settings and in particular in industrial scenarios. To encourage research in this field, we present MECCANO, a multimodal dataset of egocentric videos to study humans behavior understanding in industrial-like settings. The multimodality is characterized by the presence of gaze signals, depth maps and RGB videos acquired simultaneously with a custom headset. The dataset has been explicitly labeled for fundamental tasks in the context of human behavior understanding from a first person view, such as recognizing and anticipating human-object interactions. With the MECCANO dataset, we explored five different tasks including 1) Action Recognition, 2) Active Objects Detection and Recognition, 3) Egocentric Human-Objects Interaction Detection, 4) Action Anticipation and 5) Next-Active Objects Detection. We propose a benchmark aimed to study human behavior in the considered industrial-like scenario which demonstrates that the investigated tasks and the considered scenario are challenging for state-of-the-art algorithms. To support research in this field, we publicy release the dataset at https://iplab.dmi.unict.it/MECCANO/.
Sequential Voting with Relational Box Fields for Active Object Detection
Nov 21, 2021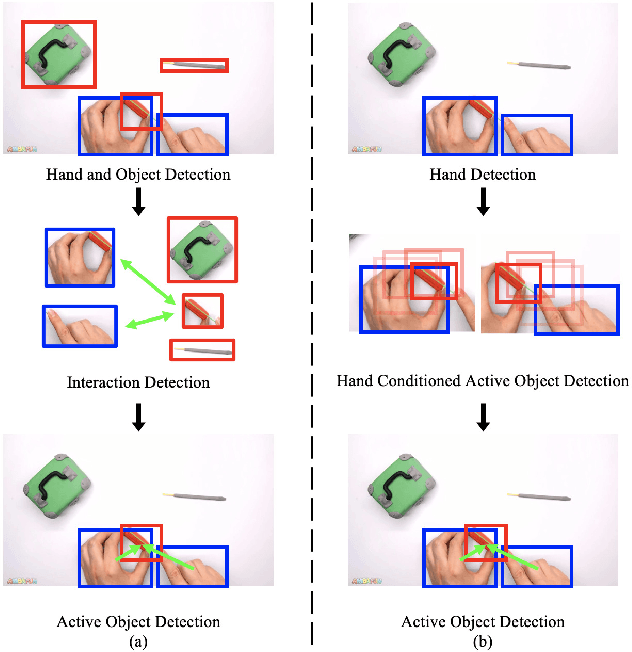

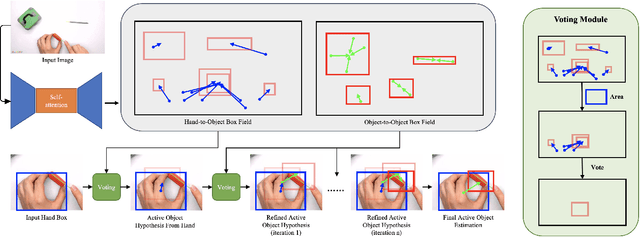

A key component of understanding hand-object interactions is the ability to identify the active object -- the object that is being manipulated by the human hand. In order to accurately localize the active object, any method must reason using information encoded by each image pixel, such as whether it belongs to the hand, the object, or the background. To leverage each pixel as evidence to determine the bounding box of the active object, we propose a pixel-wise voting function. Our pixel-wise voting function takes an initial bounding box as input and produces an improved bounding box of the active object as output. The voting function is designed so that each pixel inside of the input bounding box votes for an improved bounding box, and the box with the majority vote is selected as the output. We call the collection of bounding boxes generated inside of the voting function, the Relational Box Field, as it characterizes a field of bounding boxes defined in relationship to the current bounding box. While our voting function is able to improve the bounding box of the active object, one round of voting is typically not enough to accurately localize the active object. Therefore, we repeatedly apply the voting function to sequentially improve the location of the bounding box. However, since it is known that repeatedly applying a one-step predictor (i.e., auto-regressive processing with our voting function) can cause a data distribution shift, we mitigate this issue using reinforcement learning (RL). We adopt standard RL to learn the voting function parameters and show that it provides a meaningful improvement over a standard supervised learning approach. We perform experiments on two large-scale datasets: 100DOH and MECCANO, improving AP50 performance by 8% and 30%, respectively, over the state of the art.
The MECCANO Dataset: Understanding Human-Object Interactions from Egocentric Videos in an Industrial-like Domain
Oct 12, 2020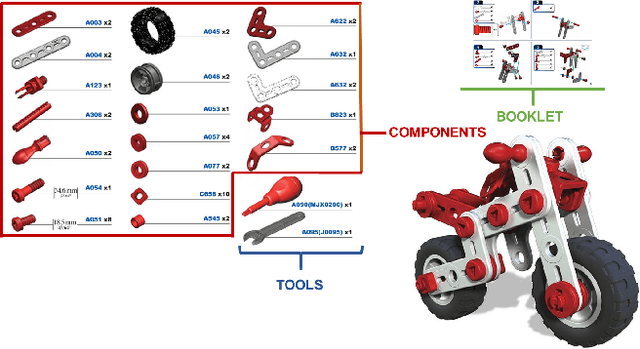
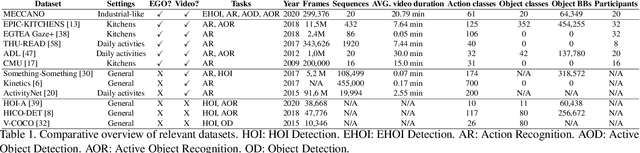

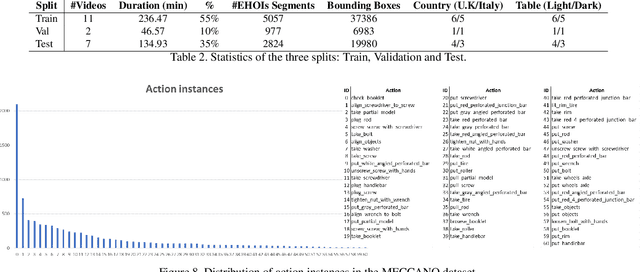
Wearable cameras allow to collect images and videos of humans interacting with the world. While human-object interactions have been thoroughly investigated in third person vision, the problem has been understudied in egocentric settings and in industrial scenarios. To fill this gap, we introduce MECCANO, the first dataset of egocentric videos to study human-object interactions in industrial-like settings. MECCANO has been acquired by 20 participants who were asked to build a motorbike model, for which they had to interact with tiny objects and tools. The dataset has been explicitly labeled for the task of recognizing human-object interactions from an egocentric perspective. Specifically, each interaction has been labeled both temporally (with action segments) and spatially (with active object bounding boxes). With the proposed dataset, we investigate four different tasks including 1) action recognition, 2) active object detection, 3) active object recognition and 4) egocentric human-object interaction detection, which is a revisited version of the standard human-object interaction detection task. Baseline results show that the MECCANO dataset is a challenging benchmark to study egocentric human-object interactions in industrial-like scenarios. We publicy release the dataset at https://iplab.dmi.unict.it/MECCANO.