 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Dataset for Enhancing Industrial Task Monitoring and Engagement Prediction
Jan 10, 2025



Detecting and interpreting operator actions, engagement, and object interactions in dynamic industrial workflows remains a significant challenge in human-robot collaboration research, especially within complex, real-world environments. Traditional unimodal methods often fall short of capturing the intricacies of these unstructured industrial settings. To address this gap, we present a novel Multimodal Industrial Activity Monitoring (MIAM) dataset that captures realistic assembly and disassembly tasks, facilitating the evaluation of key meta-tasks such as action localization, object interaction, and engagement prediction. The dataset comprises multi-view RGB, depth, and Inertial Measurement Unit (IMU) data collected from 22 sessions, amounting to 290 minutes of untrimmed video, annotated in detail for task performance and operator behavior. Its distinctiveness lies in the integration of multiple data modalities and its emphasis on real-world, untrimmed industrial workflows-key for advancing research in human-robot collaboration and operator monitoring. Additionally, we propose a multimodal network that fuses RGB frames, IMU data, and skeleton sequences to predict engagement levels during industrial tasks. Our approach improves the accuracy of recognizing engagement states, providing a robust solution for monitoring operator performance in dynamic industrial environments. The dataset and code can be accessed from https://github.com/navalkishoremehta95/MIAM/.
Optimizing Multitask Industrial Processes with Predictive Action Guidance
Jan 09, 2025



Monitoring complex assembly processes is critical for maintaining productivity and ensuring compliance with assembly standards. However, variability in human actions and subjective task preferences complicate accurate task anticipation and guidance. To address these challenges, we introduce the Multi-Modal Transformer Fusion and Recurrent Units (MMTFRU) Network for egocentric activity anticipation, utilizing multimodal fusion to improve prediction accuracy. Integrated with the Operator Action Monitoring Unit (OAMU), the system provides proactive operator guidance, preventing deviations in the assembly process. OAMU employs two strategies: (1) Top-5 MMTF-RU predictions, combined with a reference graph and an action dictionary, for next-step recommendations; and (2) Top-1 MMTF-RU predictions, integrated with a reference graph, for detecting sequence deviations and predicting anomaly scores via an entropy-informed confidence mechanism. We also introduce Time-Weighted Sequence Accuracy (TWSA) to evaluate operator efficiency and ensure timely task completion. Our approach is validated on the industrial Meccano dataset and the largescale EPIC-Kitchens-55 dataset, demonstrating its effectiveness in dynamic environments.
Gaze-Vector Estimation in the Dark with Temporally Encoded Event-driven Neural Networks
Mar 05, 2024



In this paper, we address the intricate challenge of gaze vector prediction, a pivotal task with applications ranging from human-computer interaction to driver monitoring systems. Our innovative approach is designed for the demanding setting of extremely low-light conditions, leveraging a novel temporal event encoding scheme, and a dedicated neural network architecture. The temporal encoding method seamlessly integrates Dynamic Vision Sensor (DVS) events with grayscale guide frames, generating consecutively encoded images for input into our neural network. This unique solution not only captures diverse gaze responses from participants within the active age group but also introduces a curated dataset tailored for low-light conditions. The encoded temporal frames paired with our network showcase impressive spatial localization and reliable gaze direction in their predictions. Achieving a remarkable 100-pixel accuracy of 100%, our research underscores the potency of our neural network to work with temporally consecutive encoded images for precise gaze vector predictions in challenging low-light videos, contributing to the advancement of gaze prediction technologies.
ParaColorizer: Realistic Image Colorization using Parallel Generative Networks
Aug 17, 2022


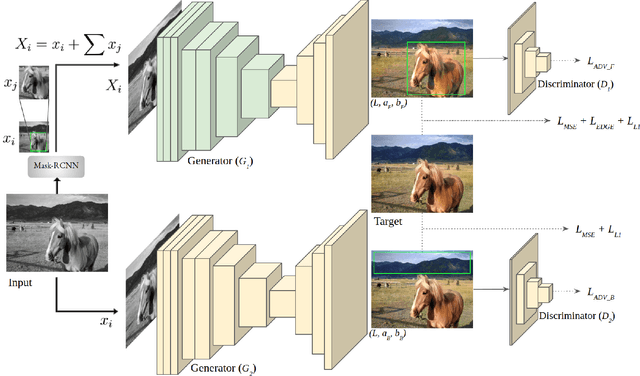
Grayscale image colorization is a fascinating application of AI for information restoration. The inherently ill-posed nature of the problem makes it even more challenging since the outputs could be multi-modal. The learning-based methods currently in use produce acceptable results for straightforward cases but usually fail to restore the contextual information in the absence of clear figure-ground separation. Also, the images suffer from color bleeding and desaturated backgrounds since a single model trained on full image features is insufficient for learning the diverse data modes. To address these issues, we present a parallel GAN-based colorization framework. In our approach, each separately tailored GAN pipeline colorizes the foreground (using object-level features) or the background (using full-image features). The foreground pipeline employs a Residual-UNet with self-attention as its generator trained using the full-image features and the corresponding object-level features from the COCO dataset. The background pipeline relies on full-image features and additional training examples from the Places dataset. We design a DenseFuse-based fusion network to obtain the final colorized image by feature-based fusion of the parallelly generated outputs. We show the shortcomings of the non-perceptual evaluation metrics commonly used to assess multi-modal problems like image colorization and perform extensive performance evaluation of our framework using multiple perceptual metrics. Our approach outperforms most of the existing learning-based methods and produces results comparable to the state-of-the-art. Further, we performed a runtime analysis and obtained an average inference time of 24ms per image.