 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaColorizer: Realistic Image Colorization using Parallel Generative Networks
Paper and Code
Aug 17, 2022


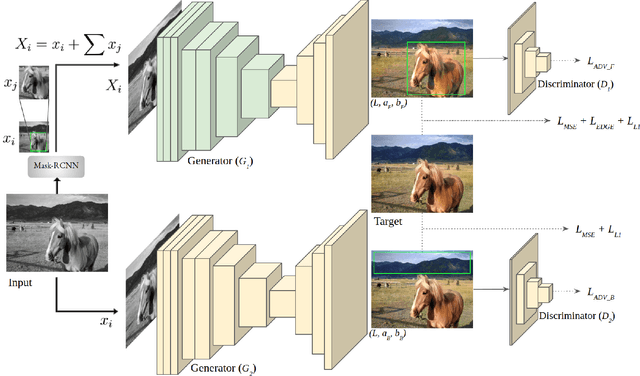
Grayscale image colorization is a fascinating application of AI for information restoration. The inherently ill-posed nature of the problem makes it even more challenging since the outputs could be multi-modal. The learning-based methods currently in use produce acceptable results for straightforward cases but usually fail to restore the contextual information in the absence of clear figure-ground separation. Also, the images suffer from color bleeding and desaturated backgrounds since a single model trained on full image features is insufficient for learning the diverse data modes. To address these issues, we present a parallel GAN-based colorization framework. In our approach, each separately tailored GAN pipeline colorizes the foreground (using object-level features) or the background (using full-image features). The foreground pipeline employs a Residual-UNet with self-attention as its generator trained using the full-image features and the corresponding object-level features from the COCO dataset. The background pipeline relies on full-image features and additional training examples from the Places dataset. We design a DenseFuse-based fusion network to obtain the final colorized image by feature-based fusion of the parallelly generated outputs. We show the shortcomings of the non-perceptual evaluation metrics commonly used to assess multi-modal problems like image colorization and perform extensive performance evaluation of our framework using multiple perceptual metrics. Our approach outperforms most of the existing learning-based methods and produces results comparable to the state-of-the-art. Further, we performed a runtime analysis and obtained an average inference time of 24ms per image.