 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoveation
Papers and Code
FOVI: A biologically-inspired foveated interface for deep vision models
Feb 03, 2026Human vision is foveated, with variable resolution peaking at the center of a large field of view; this reflects an efficient trade-off for active sensing, allowing eye-movements to bring different parts of the world into focus with other parts of the world in context. In contrast, most computer vision systems encode the visual world at a uniform resolution, raising challenges for processing full-field high-resolution images efficiently. We propose a foveated vision interface (FOVI) based on the human retina and primary visual cortex, that reformats a variable-resolution retina-like sensor array into a uniformly dense, V1-like sensor manifold. Receptive fields are defined as k-nearest-neighborhoods (kNNs) on the sensor manifold, enabling kNN-convolution via a novel kernel mapping technique. We demonstrate two use cases: (1) an end-to-end kNN-convolutional architecture, and (2) a foveated adaptation of the foundational DINOv3 ViT model, leveraging low-rank adaptation (LoRA). These models provide competitive performance at a fraction of the computational cost of non-foveated baselines, opening pathways for efficient and scalable active sensing for high-resolution egocentric vision. Code and pre-trained models are available at https://github.com/nblauch/fovi and https://huggingface.co/fovi-pytorch.
Hybrid Foveated Path Tracing with Peripheral Gaussians for Immersive Anatomy
Jan 29, 2026Volumetric medical imaging offers great potential for understanding complex pathologies. Yet, traditional 2D slices provide little support for interpreting spatial relationships, forcing users to mentally reconstruct anatomy into three dimensions. Direct volumetric path tracing and VR rendering can improve perception but are computationally expensive, while precomputed representations, like Gaussian Splatting, require planning ahead. Both approaches limit interactive use. We propose a hybrid rendering approach for high-quality, interactive, and immersive anatomical visualization. Our method combines streamed foveated path tracing with a lightweight Gaussian Splatting approximation of the periphery. The peripheral model generation is optimized with volume data and continuously refined using foveal renderings, enabling interactive updates. Depth-guided reprojection further improves robustness to latency and allows users to balance fidelity with refresh rate. We compare our method against direct path tracing and Gaussian Splatting. Our results highlight how their combination can preserve strengths in visual quality while re-generating the peripheral model in under a second, eliminating extensive preprocessing and approximations. This opens new options for interactive medical visualization.
Gaze Prediction in Virtual Reality Without Eye Tracking Using Visual and Head Motion Cues
Jan 26, 2026Gaze prediction plays a critical role in Virtual Reality (VR) applications by reducing sensor-induced latency and enabling computationally demanding techniques such as foveated rendering, which rely on anticipating user attention. However, direct eye tracking is often unavailable due to hardware limitations or privacy concerns. To address this, we present a novel gaze prediction framework that combines Head-Mounted Display (HMD) motion signals with visual saliency cues derived from video frames. Our method employs UniSal, a lightweight saliency encoder, to extract visual features, which are then fused with HMD motion data and processed through a time-series prediction module. We evaluate two lightweight architectures, TSMixer and LSTM, for forecasting future gaze directions. Experiments on the EHTask dataset, along with deployment on commercial VR hardware, show that our approach consistently outperforms baselines such as Center-of-HMD and Mean Gaze. These results demonstrate the effectiveness of predictive gaze modeling in reducing perceptual lag and enhancing natural interaction in VR environments where direct eye tracking is constrained.
Generating metamers of human scene understanding
Jan 16, 2026Human vision combines low-resolution "gist" information from the visual periphery with sparse but high-resolution information from fixated locations to construct a coherent understanding of a visual scene. In this paper, we introduce MetamerGen, a tool for generating scenes that are aligned with latent human scene representations. MetamerGen is a latent diffusion model that combines peripherally obtained scene gist information with information obtained from scene-viewing fixations to generate image metamers for what humans understand after viewing a scene. Generating images from both high and low resolution (i.e. "foveated") inputs constitutes a novel image-to-image synthesis problem, which we tackle by introducing a dual-stream representation of the foveated scenes consisting of DINOv2 tokens that fuse detailed features from fixated areas with peripherally degraded features capturing scene context. To evaluate the perceptual alignment of MetamerGen generated images to latent human scene representations, we conducted a same-different behavioral experiment where participants were asked for a "same" or "different" response between the generated and the original image. With that, we identify scene generations that are indeed metamers for the latent scene representations formed by the viewers. MetamerGen is a powerful tool for understanding scene understanding. Our proof-of-concept analyses uncovered specific features at multiple levels of visual processing that contributed to human judgments. While it can generate metamers even conditioned on random fixations, we find that high-level semantic alignment most strongly predicts metamerism when the generated scenes are conditioned on viewers' own fixated regions.
3D4D: An Interactive, Editable, 4D World Model via 3D Video Generation
Nov 11, 2025We introduce 3D4D, an interactive 4D visualization framework that integrates WebGL with Supersplat rendering. It transforms static images and text into coherent 4D scenes through four core modules and employs a foveated rendering strategy for efficient, real-time multi-modal interaction. This framework enables adaptive, user-driven exploration of complex 4D environments. The project page and code are available at https://yunhonghe1021.github.io/NOVA/.
Simulated Cortical Magnification Supports Self-Supervised Object Learning
Sep 19, 2025Recent self-supervised learning models simulate the development of semantic object representations by training on visual experience similar to that of toddlers. However, these models ignore the foveated nature of human vision with high/low resolution in the center/periphery of the visual field. Here, we investigate the role of this varying resolution in the development of object representations. We leverage two datasets of egocentric videos that capture the visual experience of humans during interactions with objects. We apply models of human foveation and cortical magnification to modify these inputs, such that the visual content becomes less distinct towards the periphery. The resulting sequences are used to train two bio-inspired self-supervised learning models that implement a time-based learning objective. Our results show that modeling aspects of foveated vision improves the quality of the learned object representations in this setting. Our analysis suggests that this improvement comes from making objects appear bigger and inducing a better trade-off between central and peripheral visual information. Overall, this work takes a step towards making models of humans' learning of visual representations more realistic and performant.
Impact of Gaze-Based Interaction and Augmentation on Human-Robot Collaboration in Critical Tasks
Aug 10, 2025We present a user study analyzing head-gaze-based robot control and foveated visual augmentation in a simulated search-and-rescue task. Results show that foveated augmentation significantly improves task performance, reduces cognitive load by 38%, and shortens task time by over 60%. Head-gaze patterns analysed over both the entire task duration and shorter time segments show that near and far attention capture is essential to better understand user intention in critical scenarios. Our findings highlight the potential of foveation as an augmentation technique and the need to further study gaze measures to leverage them during critical tasks.
Egocentric Event-Based Vision for Ping Pong Ball Trajectory Prediction
Jun 09, 2025
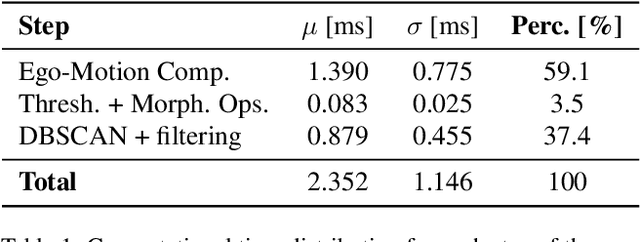


In this paper, we present a real-time egocentric trajectory prediction system for table tennis using event cameras. Unlike standard cameras, which suffer from high latency and motion blur at fast ball speeds, event cameras provide higher temporal resolution, allowing more frequent state updates, greater robustness to outliers, and accurate trajectory predictions using just a short time window after the opponent's impact. We collect a dataset of ping-pong game sequences, including 3D ground-truth trajectories of the ball, synchronized with sensor data from the Meta Project Aria glasses and event streams. Our system leverages foveated vision, using eye-gaze data from the glasses to process only events in the viewer's fovea. This biologically inspired approach improves ball detection performance and significantly reduces computational latency, as it efficiently allocates resources to the most perceptually relevant regions, achieving a reduction factor of 10.81 on the collected trajectories. Our detection pipeline has a worst-case total latency of 4.5 ms, including computation and perception - significantly lower than a frame-based 30 FPS system, which, in the worst case, takes 66 ms solely for perception. Finally, we fit a trajectory prediction model to the estimated states of the ball, enabling 3D trajectory forecasting in the future. To the best of our knowledge, this is the first approach to predict table tennis trajectories from an egocentric perspective using event cameras.
Reading in the Dark with Foveated Event Vision
Jun 07, 2025Current smart glasses equipped with RGB cameras struggle to perceive the environment in low-light and high-speed motion scenarios due to motion blur and the limited dynamic range of frame cameras. Additionally, capturing dense images with a frame camera requires large bandwidth and power consumption, consequently draining the battery faster. These challenges are especially relevant for developing algorithms that can read text from images. In this work, we propose a novel event-based Optical Character Recognition (OCR) approach for smart glasses. By using the eye gaze of the user, we foveate the event stream to significantly reduce bandwidth by around 98% while exploiting the benefits of event cameras in high-dynamic and fast scenes. Our proposed method performs deep binary reconstruction trained on synthetic data and leverages multimodal LLMs for OCR, outperforming traditional OCR solutions. Our results demonstrate the ability to read text in low light environments where RGB cameras struggle while using up to 2400 times less bandwidth than a wearable RGB camera.
Predicting Reaction Time to Comprehend Scenes with Foveated Scene Understanding Maps
May 19, 2025Although models exist that predict human response times (RTs) in tasks such as target search and visual discrimination, the development of image-computable predictors for scene understanding time remains an open challenge. Recent advances in vision-language models (VLMs), which can generate scene descriptions for arbitrary images, combined with the availability of quantitative metrics for comparing linguistic descriptions, offer a new opportunity to model human scene understanding. We hypothesize that the primary bottleneck in human scene understanding and the driving source of variability in response times across scenes is the interaction between the foveated nature of the human visual system and the spatial distribution of task-relevant visual information within an image. Based on this assumption, we propose a novel image-computable model that integrates foveated vision with VLMs to produce a spatially resolved map of scene understanding as a function of fixation location (Foveated Scene Understanding Map, or F-SUM), along with an aggregate F-SUM score. This metric correlates with average (N=17) human RTs (r=0.47) and number of saccades (r=0.51) required to comprehend a scene (across 277 scenes). The F-SUM score also correlates with average (N=16) human description accuracy (r=-0.56) in time-limited presentations. These correlations significantly exceed those of standard image-based metrics such as clutter, visual complexity, and scene ambiguity based on language entropy. Together, our work introduces a new image-computable metric for predicting human response times in scene understanding and demonstrates the importance of foveated visual processing in shaping comprehension difficulty.