 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Reaction Time to Comprehend Scenes with Foveated Scene Understanding Maps
May 19, 2025Although models exist that predict human response times (RTs) in tasks such as target search and visual discrimination, the development of image-computable predictors for scene understanding time remains an open challenge. Recent advances in vision-language models (VLMs), which can generate scene descriptions for arbitrary images, combined with the availability of quantitative metrics for comparing linguistic descriptions, offer a new opportunity to model human scene understanding. We hypothesize that the primary bottleneck in human scene understanding and the driving source of variability in response times across scenes is the interaction between the foveated nature of the human visual system and the spatial distribution of task-relevant visual information within an image. Based on this assumption, we propose a novel image-computable model that integrates foveated vision with VLMs to produce a spatially resolved map of scene understanding as a function of fixation location (Foveated Scene Understanding Map, or F-SUM), along with an aggregate F-SUM score. This metric correlates with average (N=17) human RTs (r=0.47) and number of saccades (r=0.51) required to comprehend a scene (across 277 scenes). The F-SUM score also correlates with average (N=16) human description accuracy (r=-0.56) in time-limited presentations. These correlations significantly exceed those of standard image-based metrics such as clutter, visual complexity, and scene ambiguity based on language entropy. Together, our work introduces a new image-computable metric for predicting human response times in scene understanding and demonstrates the importance of foveated visual processing in shaping comprehension difficulty.
Comparing Visual Reasoning in Humans and AI
Apr 29, 2021
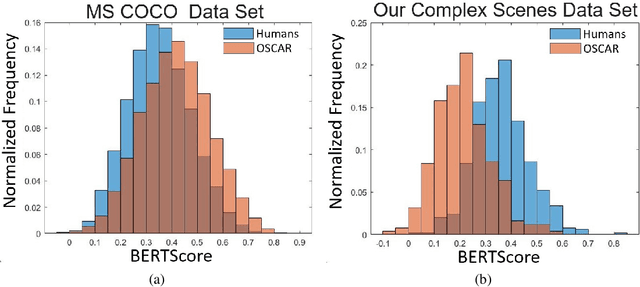

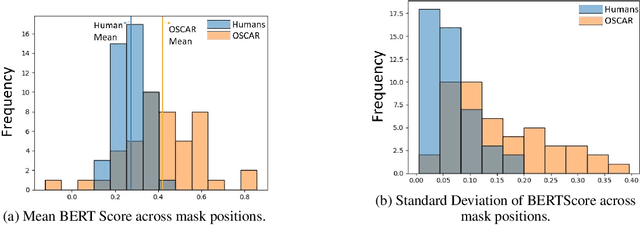
Recent advances in natural language processing and computer vision have led to AI models that interpret simple scenes at human levels. Yet, we do not have a complete understanding of how humans and AI models differ in their interpretation of more complex scenes. We created a dataset of complex scenes that contained human behaviors and social interactions. AI and humans had to describe the scenes with a sentence. We used a quantitative metric of similarity between scene descriptions of the AI/human and ground truth of five other human descriptions of each scene. Results show that the machine/human agreement scene descriptions are much lower than human/human agreement for our complex scenes. Using an experimental manipulation that occludes different spatial regions of the scenes, we assessed how machines and humans vary in utilizing regions of images to understand the scenes. Together, our results are a first step toward understanding how machines fall short of human visual reasoning with complex scenes depicting human behaviors.