 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Mem2Ego: Empowering Vision-Language Models with Global-to-Ego Memory for Long-Horizon Embodied Navigation
Feb 20, 2025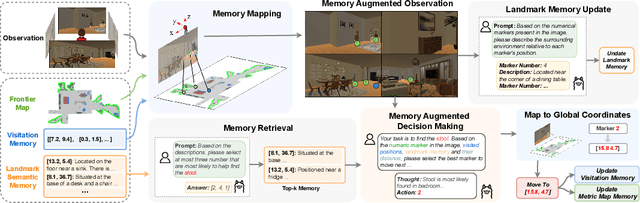
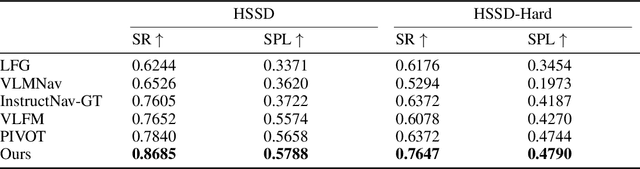
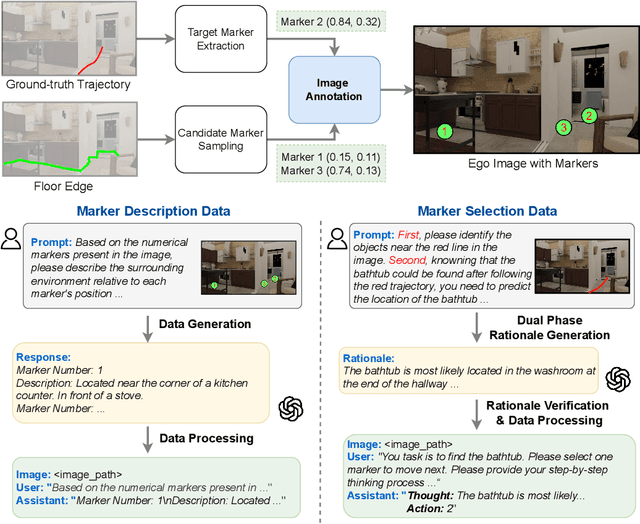

Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have made them powerful tools in embodied navigation, enabling agents to leverage commonsense and spatial reasoning for efficient exploration in unfamiliar environments. Existing LLM-based approaches convert global memory, such as semantic or topological maps, into language descriptions to guide navigation. While this improves efficiency and reduces redundant exploration, the loss of geometric information in language-based representations hinders spatial reasoning, especially in intricate environments. To address this, VLM-based approaches directly process ego-centric visual inputs to select optimal directions for exploration. However, relying solely on a first-person perspective makes navigation a partially observed decision-making problem, leading to suboptimal decisions in complex environments. In this paper, we present a novel vision-language model (VLM)-based navigation framework that addresses these challenges by adaptively retrieving task-relevant cues from a global memory module and integrating them with the agent's egocentric observations. By dynamically aligning global contextual information with local perception, our approach enhances spatial reasoning and decision-making in long-horizon tasks. Experimental results demonstrate that the proposed method surpasses previous state-of-the-art approaches in object navigation tasks, providing a more effective and scalable solution for embodied navigation.
FarSee-Net: Real-Time Semantic Segmentation by Efficient Multi-scale Context Aggregation and Feature Space Super-resolution
Mar 09, 2020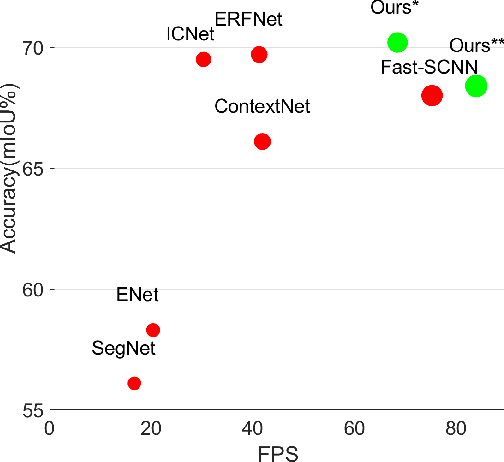



Real-time semantic segmentation is desirable in many robotic applications with limited computation resources. One challenge of semantic segmentation is to deal with the object scale variations and leverage the context. How to perform multi-scale context aggregation within limited computation budget is important. In this paper, firstly, we introduce a novel and efficient module called Cascaded Factorized Atrous Spatial Pyramid Pooling (CF-ASPP). It is a lightweight cascaded structure for Convolutional Neural Networks (CNNs) to efficiently leverage context information. On the other hand, for runtime efficiency, state-of-the-art methods will quickly decrease the spatial size of the inputs or feature maps in the early network stages. The final high-resolution result is usually obtained by non-parametric up-sampling operation (e.g. bilinear interpolation). Differently, we rethink this pipeline and treat it as a super-resolution process. We use optimized super-resolution operation in the up-sampling step and improve the accuracy, especially in sub-sampled input image scenario for real-time applications. By fusing the above two improvements, our methods provide better latency-accuracy trade-off than the other state-of-the-art methods. In particular, we achieve 68.4% mIoU at 84 fps on the Cityscapes test set with a single Nivida Titan X (Maxwell) GPU card. The proposed module can be plugged into any feature extraction CNN and benefits from the CNN structure development.
Multi-modality Latent Interaction Network for Visual Question Answering
Aug 10, 2019


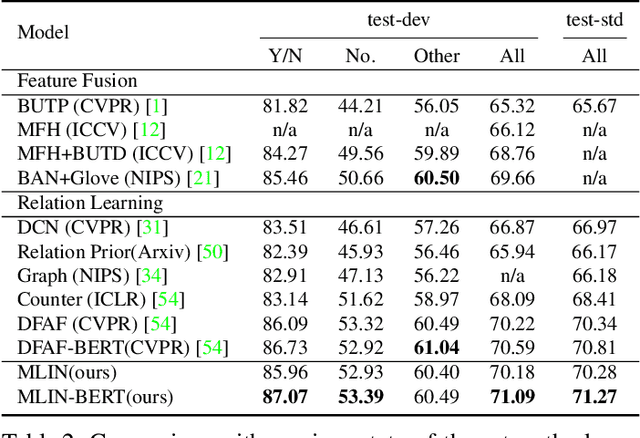
Exploiting relationships between visual regions and question words have achieved great success in learning multi-modality features for Visual Question Answering (VQA). However, we argue that existing methods mostly model relations between individual visual regions and words, which are not enough to correctly answer the question. From humans' perspective, answering a visual question requires understanding the summarizations of visual and language information. In this paper, we proposed the Multi-modality Latent Interaction module (MLI) to tackle this problem. The proposed module learns the cross-modality relationships between latent visual and language summarizations, which summarize visual regions and question into a small number of latent representations to avoid modeling uninformative individual region-word relations. The cross-modality information between the latent summarizations are propagated to fuse valuable information from both modalities and are used to update the visual and word features. Such MLI modules can be stacked for several stages to model complex and latent relations between the two modalities and achieves highly competitive performance on public VQA benchmarks, VQA v2.0 and TDIUC . In addition, we show that the performance of our methods could be significantly improved by combining with pre-trained language model BERT.
MetaGrasp: Data Efficient Grasping by Affordance Interpreter Network
Feb 23, 2019
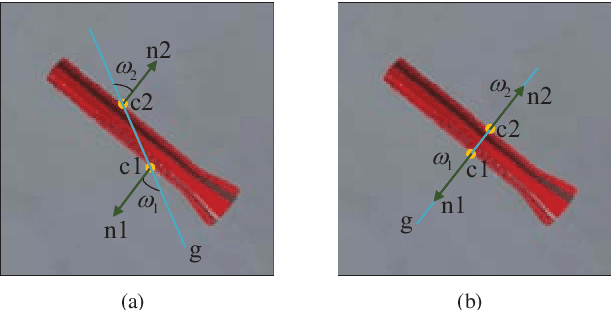
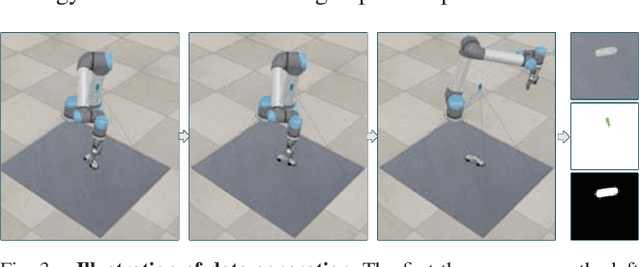
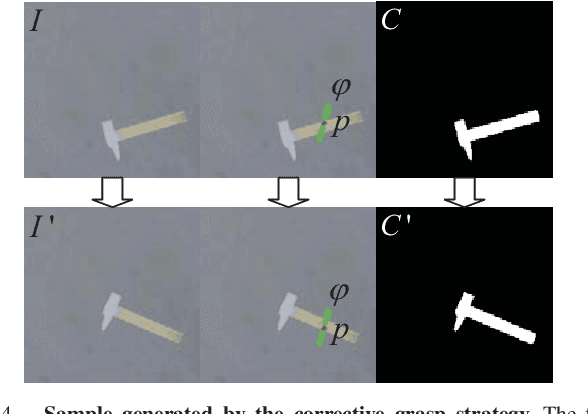
Data-driven approach for grasping shows significant advance recently. But these approaches usually require much training data. To increase the efficiency of grasping data collection, this paper presents a novel grasp training system including the whole pipeline from data collection to model inference. The system can collect effective grasp sample with a corrective strategy assisted by antipodal grasp rule, and we design an affordance interpreter network to predict pixelwise grasp affordance map. We define graspability, ungraspability and background as grasp affordances. The key advantage of our system is that the pixel-level affordance interpreter network trained with only a small number of grasp samples under antipodal rule can achieve significant performance on totally unseen objects and backgrounds. The training sample is only collected in simulation. Extensive qualitative and quantitative experiments demonstrate the accuracy and robustness of our proposed approach. In the real-world grasp experiments, we achieve a grasp success rate of 93% on a set of household items and 91% on a set of adversarial items with only about 6,300 simulated samples. We also achieve 87% accuracy in clutter scenario. Although the model is trained using only RGB image, when changing the background textures, it also performs well and can achieve even 94% accuracy on the set of adversarial objects, which outperforms current state-of-the-art methods.
Super-Identity Convolutional Neural Network for Face Hallucination
Nov 06, 2018
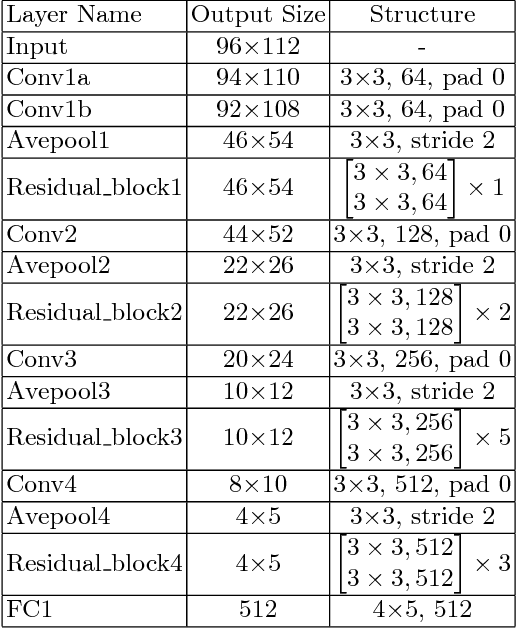

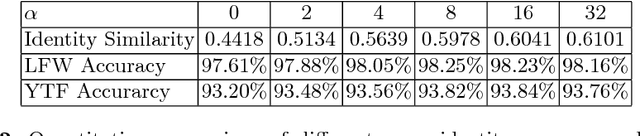
Face hallucination is a generative task to super-resolve the facial image with low resolution while human perception of face heavily relies on identity information. However, previous face hallucination approaches largely ignore facial identity recovery. This paper proposes Super-Identity Convolutional Neural Network (SICNN) to recover identity information for generating faces closed to the real identity. Specifically, we define a super-identity loss to measure the identity difference between a hallucinated face and its corresponding high-resolution face within the hypersphere identity metric space. However, directly using this loss will lead to a Dynamic Domain Divergence problem, which is caused by the large margin between the high-resolution domain and the hallucination domain. To overcome this challenge, we present a domain-integrated training approach by constructing a robust identity metric for faces from these two domains. Extensive experimental evaluations demonstrate that the proposed SICNN achieves superior visual quality over the state-of-the-art methods on a challenging task to super-resolve 12$\times$14 faces with an 8$\times$ upscaling factor. In addition, SICNN significantly improves the recognizability of ultra-low-resolution faces.
From Facial Expression Recognition to Interpersonal Relation Prediction
Nov 06, 2017



Interpersonal relation defines the association, e.g., warm, friendliness, and dominance, between two or more people. Motivated by psychological studies, we investigate if such fine-grained and high-level relation traits can be characterized and quantified from face images in the wild. We address this challenging problem by first studying a deep network architecture for robust recognition of facial expressions. Unlike existing models that typically learn from facial expression labels alone, we devise an effective multitask network that is capable of learning from rich auxiliary attributes such as gender, age, and head pose, beyond just facial expression data. While conventional supervised training requires datasets with complete labels (e.g., all samples must be labeled with gender, age, and expression), we show that this requirement can be relaxed via a novel attribute propagation method. The approach further allows us to leverage the inherent correspondences between heterogeneous attribute sources despite the disparate distributions of different datasets. With the network we demonstrate state-of-the-art results on existing facial expression recognition benchmarks. To predict inter-personal relation, we use the expression recognition network as branches for a Siamese model. Extensive experiments show that our model is capable of mining mutual context of faces for accurate fine-grained interpersonal prediction.
Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
Apr 11, 2016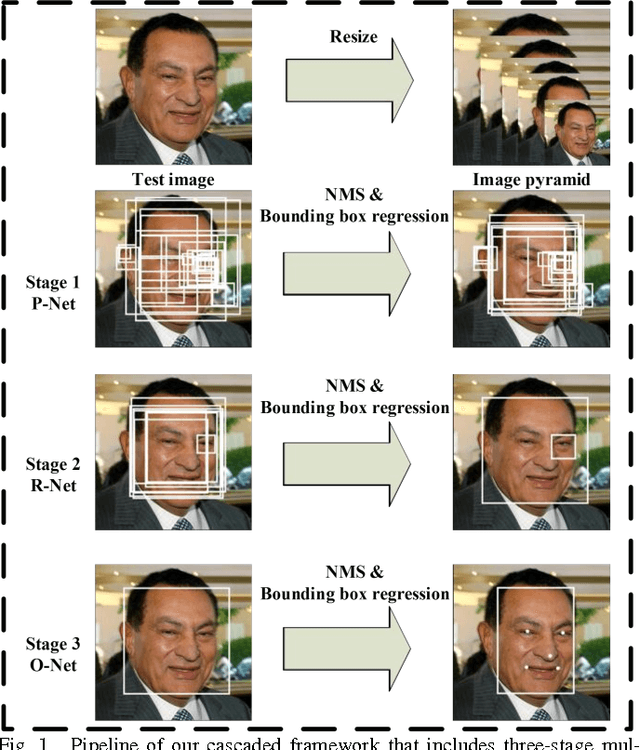
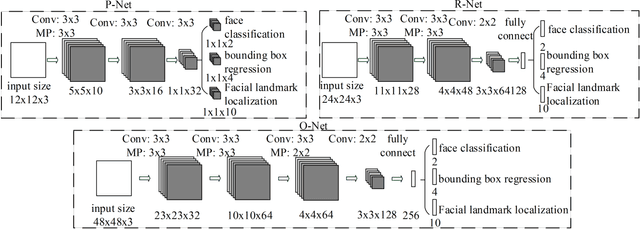


Face detection and alignment in unconstrained environment are challenging due to various poses, illuminations and occlusions. Recent studies show that deep learning approaches can achieve impressive performance on these two tasks. In this paper, we propose a deep cascaded multi-task framework which exploits the inherent correlation between them to boost up their performance. In particular, our framework adopts a cascaded structure with three stages of carefully designed deep convolutional networks that predict face and landmark location in a coarse-to-fine manner. In addition, in the learning process, we propose a new online hard sample mining strategy that can improve the performance automatically without manual sample selection. Our method achieves superior accuracy over the state-of-the-art techniques on the challenging FDDB and WIDER FACE benchmark for face detection, and AFLW benchmark for face alignment, while keeps real time performance.
Learning Social Relation Traits from Face Images
Sep 14, 2015



Social relation defines the association, e.g, warm, friendliness, and dominance, between two or more people. Motivated by psychological studies, we investigate if such fine-grained and high-level relation traits can be characterised and quantified from face images in the wild. To address this challenging problem we propose a deep model that learns a rich face representation to capture gender, expression, head pose, and age-related attributes, and then performs pairwise-face reasoning for relation prediction. To learn from heterogeneous attribute sources, we formulate a new network architecture with a bridging layer to leverage the inherent correspondences among these datasets. It can also cope with missing target attribute labels. Extensive experiments show that our approach is effective for fine-grained social relation learning in images and videos.
Learning Deep Representation for Face Alignment with Auxiliary Attributes
Aug 11, 2015
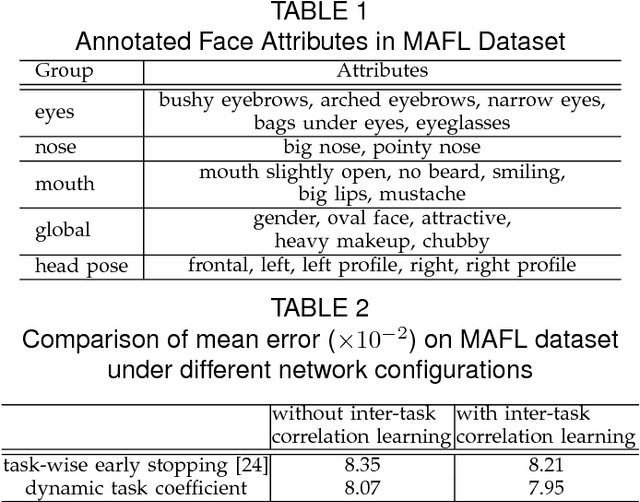
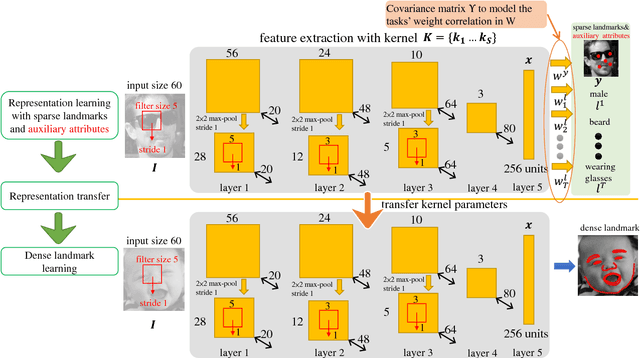

In this study, we show that landmark detection or face alignment task is not a single and independent problem. Instead, its robustness can be greatly improved with auxiliary information. Specifically, we jointly optimize landmark detection together with the recognition of heterogeneous but subtly correlated facial attributes, such as gender, expression, and appearance attributes. This is non-trivial since different attribute inference tasks have different learning difficulties and convergence rates. To address this problem, we formulate a novel tasks-constrained deep model, which not only learns the inter-task correlation but also employs dynamic task coefficients to facilitate the optimization convergence when learning multiple complex tasks. Extensive evaluations show that the proposed task-constrained learning (i) outperforms existing face alignment methods, especially in dealing with faces with severe occlusion and pose variation, and (ii) reduces model complexity drastically compared to the state-of-the-art methods based on cascaded deep model.