 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modality Latent Interaction Network for Visual Question Answering
Paper and Code
Aug 10, 2019


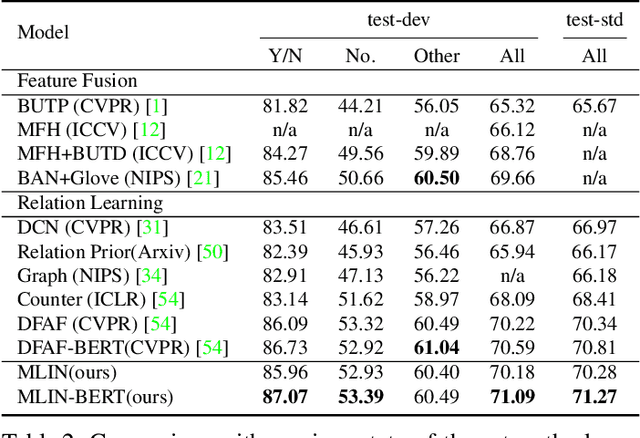
Exploiting relationships between visual regions and question words have achieved great success in learning multi-modality features for Visual Question Answering (VQA). However, we argue that existing methods mostly model relations between individual visual regions and words, which are not enough to correctly answer the question. From humans' perspective, answering a visual question requires understanding the summarizations of visual and language information. In this paper, we proposed the Multi-modality Latent Interaction module (MLI) to tackle this problem. The proposed module learns the cross-modality relationships between latent visual and language summarizations, which summarize visual regions and question into a small number of latent representations to avoid modeling uninformative individual region-word relations. The cross-modality information between the latent summarizations are propagated to fuse valuable information from both modalities and are used to update the visual and word features. Such MLI modules can be stacked for several stages to model complex and latent relations between the two modalities and achieves highly competitive performance on public VQA benchmarks, VQA v2.0 and TDIUC . In addition, we show that the performance of our methods could be significantly improved by combining with pre-trained language model BERT.