 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwitter discussions and emotions about COVID-19 pandemic: a machine learning approach
Jun 19, 2020



The objective of the study is to examine coronavirus disease (COVID-19) related discussions, concerns, and sentiments that emerged from tweets posted by Twitter users. We analyze 4 million Twitter messages related to the COVID-19 pandemic using a list of 25 hashtags such as "coronavirus," "COVID-19," "quarantine" from March 1 to April 21 in 2020. We use a machine learning approach, Latent Dirichlet Allocation (LDA), to identify popular unigram, bigrams, salient topics and themes, and sentiments in the collected Tweets. Popular unigrams include "virus," "lockdown," and "quarantine." Popular bigrams include "COVID-19," "stay home," "corona virus," "social distancing," and "new cases." We identify 13 discussion topics and categorize them into five different themes, such as "public health measures to slow the spread of COVID-19," "social stigma associated with COVID-19," "coronavirus news cases and deaths," "COVID-19 in the United States," and "coronavirus cases in the rest of the world". Across all identified topics, the dominant sentiments for the spread of coronavirus are anticipation that measures that can be taken, followed by a mixed feeling of trust, anger, and fear for different topics. The public reveals a significant feeling of fear when they discuss the coronavirus new cases and deaths than other topics. The study shows that Twitter data and machine learning approaches can be leveraged for infodemiology study by studying the evolving public discussions and sentiments during the COVID-19. Real-time monitoring and assessment of the Twitter discussion and concerns can be promising for public health emergency responses and planning. Already emerged pandemic fear, stigma, and mental health concerns may continue to influence public trust when there occurs a second wave of COVID-19 or a new surge of the imminent pandemic.
Machine learning on Big Data from Twitter to understand public reactions to COVID-19
May 22, 2020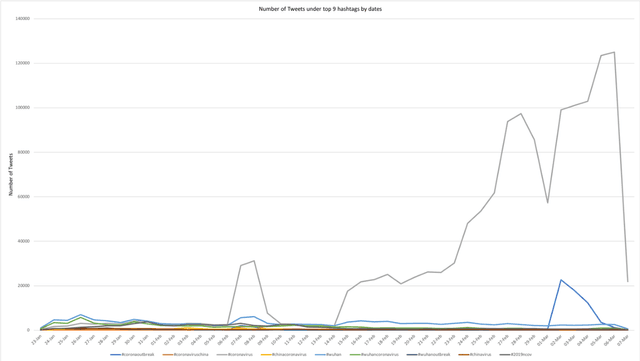



The study aims to understand Twitter users' discussions and reactions about the COVID-19. We use machine learning techniques to analyze about 1.8 million Tweets messages related to coronavirus collected from January 20th to March 7th, 2020. A total of salient 11 topics are identified and then categorized into 10 themes, such as "cases outside China (worldwide)," "COVID-19 outbreak in South Korea," "early signs of the outbreak in New York," "Diamond Princess cruise," "economic impact," "Preventive/Protective measures," "authorities," and "supply chain". Results do not reveal treatment and/or symptoms related messages as a prevalent topic on Twitter. We also run sentiment analysis and the results show that trust for the authorities remained a prevalent emotion, but mixed feelings of trust for authorities, fear for the outbreak, and anticipation for the potential preventive measures will be taken are identified. Implications and limitations of the study are also discussed.
Multivariate Regression with Grossly Corrupted Observations: A Robust Approach and its Applications
Jan 11, 2017
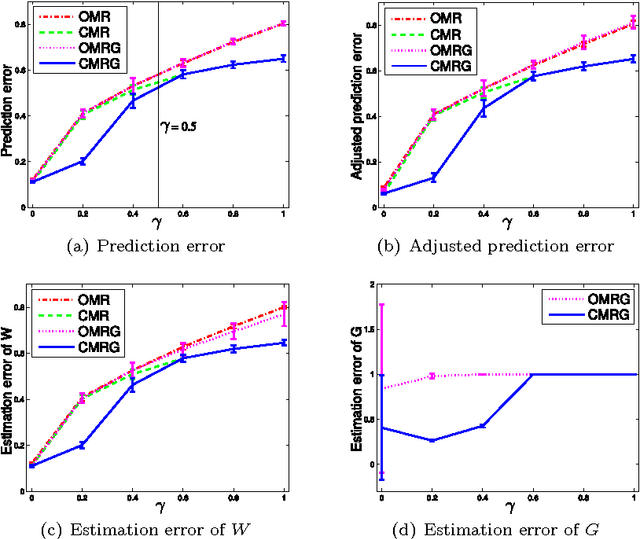

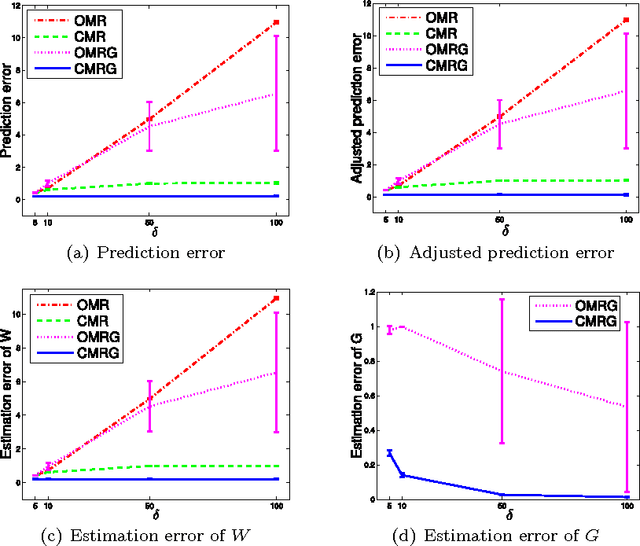
This paper studies the problem of multivariate linear regression where a portion of the observations is grossly corrupted or is missing, and the magnitudes and locations of such occurrences are unknown in priori. To deal with this problem, we propose a new approach by explicitly consider the error source as well as its sparseness nature. An interesting property of our approach lies in its ability of allowing individual regression output elements or tasks to possess their unique noise levels. Moreover, despite working with a non-smooth optimization problem, our approach still guarantees to converge to its optimal solution. Experiments on synthetic data demonstrate the competitiveness of our approach compared with existing multivariate regression models. In addition, empirically our approach has been validated with very promising results on two exemplar real-world applications: The first concerns the prediction of \textit{Big-Five} personality based on user behaviors at social network sites (SNSs), while the second is 3D human hand pose estimation from depth images. The implementation of our approach and comparison methods as well as the involved datasets are made publicly available in support of the open-source and reproducible research initiatives.
Recognizing Temporal Linguistic Expression Pattern of Individual with Suicide Risk on Social Media
Nov 30, 2015
Suicide is a global public health problem. Early detection of individual suicide risk plays a key role in suicide prevention. In this paper, we propose to look into individual suicide risk through time series analysis of personal linguistic expression on social media (Weibo). We examined temporal patterns of the linguistic expression of individuals on Chinese social media (Weibo). Then, we used such temporal patterns as predictor variables to build classification models for estimating levels of individual suicide risk. Characteristics of time sequence curves to linguistic features including parentheses, auxiliary verbs, personal pronouns and body words are reported to affect performance of suicide most, and the predicting model has a accuracy higher than 0.60, shown by the results. This paper confirms the efficiency of the social media data in detecting individual suicide risk. Results of this study may be insightful for improving the performance of suicide prevention programs.
Identifying Emotion from Natural Walking
Sep 10, 2015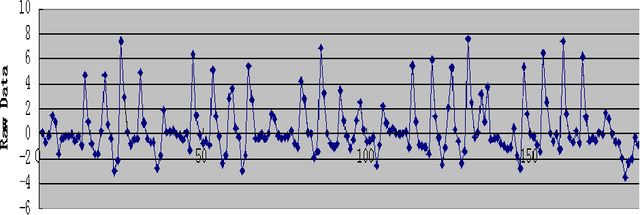
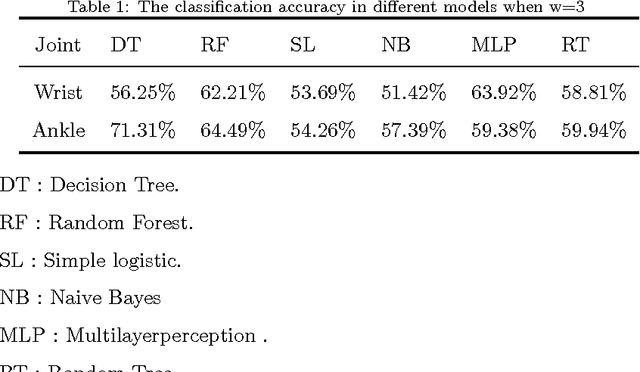
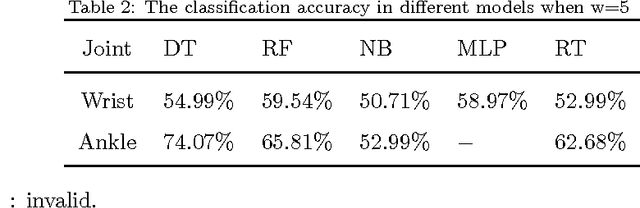
Emotion identification from gait aims to automatically determine persons affective state, it has attracted a great deal of interests and offered immense potential value in action tendency, health care, psychological detection and human-computer(robot) interaction.In this paper, we propose a new method of identifying emotion from natural walking, and analyze the relevance between the traits of walking and affective states. After obtaining the pure acceleration data of wrist and ankle, we set a moving average filter window with different sizes w, then extract 114 features including time-domain, frequency-domain, power and distribution features from each data slice, and run principal component analysis (PCA) to reduce dimension. In experiments, we train SVM, Decision Tree, multilayerperception, Random Tree and Random Forest classification models, and compare the classification accuracy on data of wrist and ankle with respect to different w. The performance of emotion identification on acceleration data of ankle is better than wrist.Comparing different classification models' results, SVM has best accuracy of identifying anger and happy could achieve 90:31% and 89:76% respectively, and identification ratio of anger-happy is 87:10%.The anger-neutral-happy classification reaches 85%-78%-78%.The results show that it is capable of identifying personal emotional states through the gait of walking.
Recognition of Emotions using Kinects
Aug 04, 2015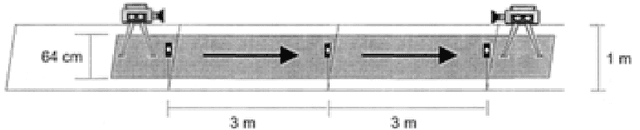

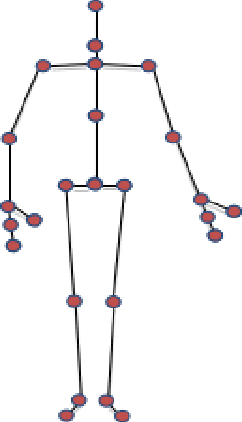

Psychological studies indicate that emotional states are expressed in the way people walk and the human gait is investigated in terms of its ability to reveal a person's emotional state. And Microsoft Kinect is a rapidly developing, inexpensive, portable and no-marker motion capture system. This paper gives a new referable method to do emotion recognition, by using Microsoft Kinect to do gait pattern analysis, which has not been reported. $59$ subjects are recruited in this study and their gait patterns are record by two Kinect cameras. Significant joints selecting, Coordinate system transforming, Slider window gauss filter, Differential operation, and Data segmentation are used in data preprocessing. Feature extracting is based on Fourier transformation. By using the NaiveBayes, RandomForests, libSVM and SMO classification, the recognition rate of natural and unnatural emotions can reach above 70%.It is concluded that using the Kinect system can be a new method in recognition of emotions.
Using Linguistic Features to Estimate Suicide Probability of Chinese Microblog Users
Nov 04, 2014

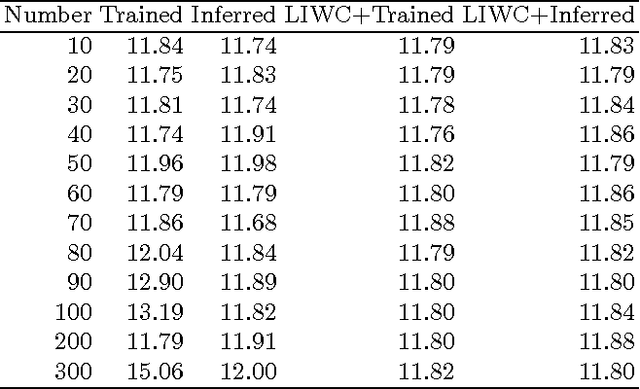
If people with high risk of suicide can be identified through social media like microblog, it is possible to implement an active intervention system to save their lives. Based on this motivation, the current study administered the Suicide Probability Scale(SPS) to 1041 weibo users at Sina Weibo, which is a leading microblog service provider in China. Two NLP (Natural Language Processing) methods, the Chinese edition of Linguistic Inquiry and Word Count (LIWC) lexicon and Latent Dirichlet Allocation (LDA), are used to extract linguistic features from the Sina Weibo data. We trained predicting models by machine learning algorithm based on these two types of features, to estimate suicide probability based on linguistic features. The experiment results indicate that LDA can find topics that relate to suicide probability, and improve the performance of prediction. Our study adds value in prediction of suicidal probability of social network users with their behaviors.
Detecting Suicidal Ideation in Chinese Microblogs with Psychological Lexicons
Nov 04, 2014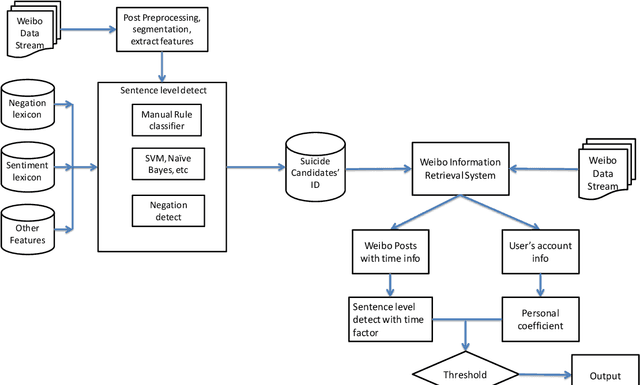
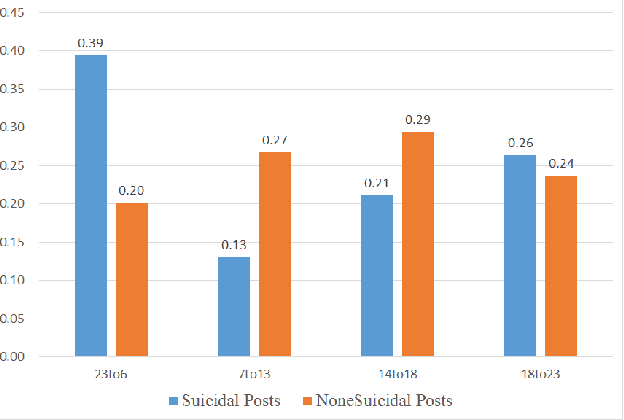
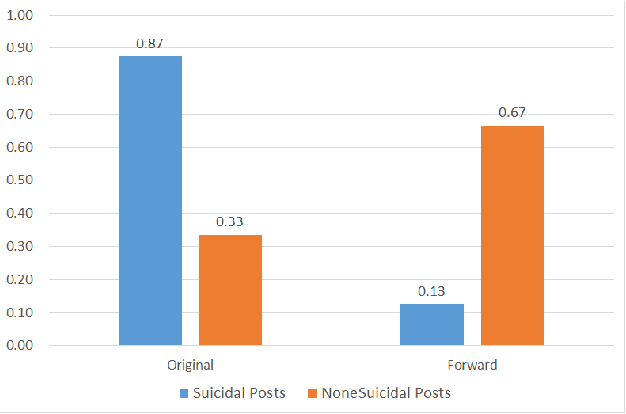
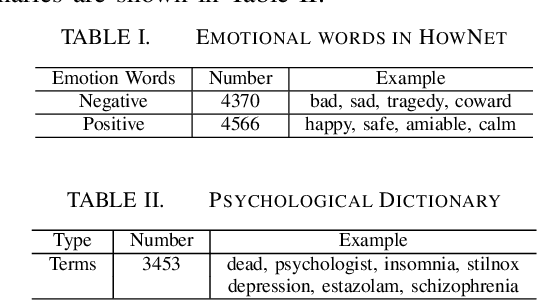
Suicide is among the leading causes of death in China. However, technical approaches toward preventing suicide are challenging and remaining under development. Recently, several actual suicidal cases were preceded by users who posted microblogs with suicidal ideation to Sina Weibo, a Chinese social media network akin to Twitter. It would therefore be desirable to detect suicidal ideations from microblogs in real-time, and immediately alert appropriate support groups, which may lead to successful prevention. In this paper, we propose a real-time suicidal ideation detection system deployed over Weibo, using machine learning and known psychological techniques. Currently, we have identified 53 known suicidal cases who posted suicide notes on Weibo prior to their deaths.We explore linguistic features of these known cases using a psychological lexicon dictionary, and train an effective suicidal Weibo post detection model. 6714 tagged posts and several classifiers are used to verify the model. By combining both machine learning and psychological knowledge, SVM classifier has the best performance of different classifiers, yielding an F-measure of 68:3%, a Precision of 78:9%, and a Recall of 60:3%.
Sensing Subjective Well-being from Social Media
Aug 28, 2014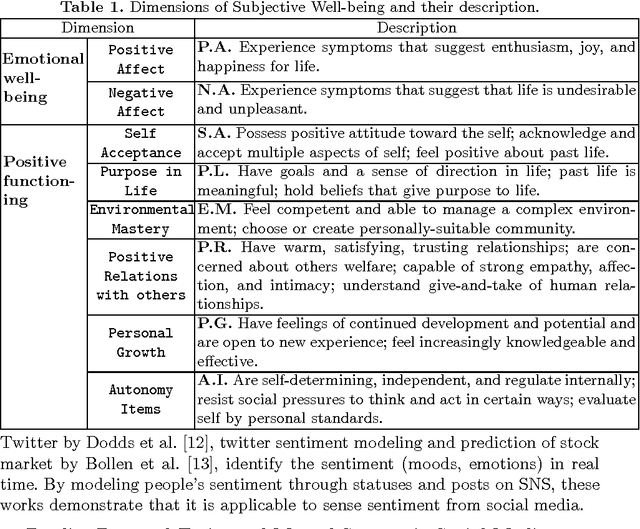
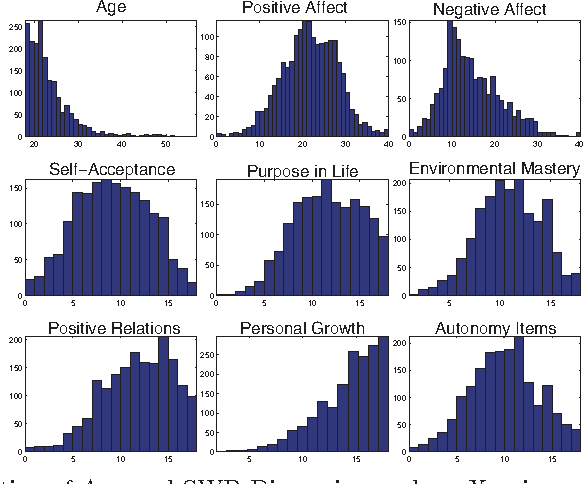

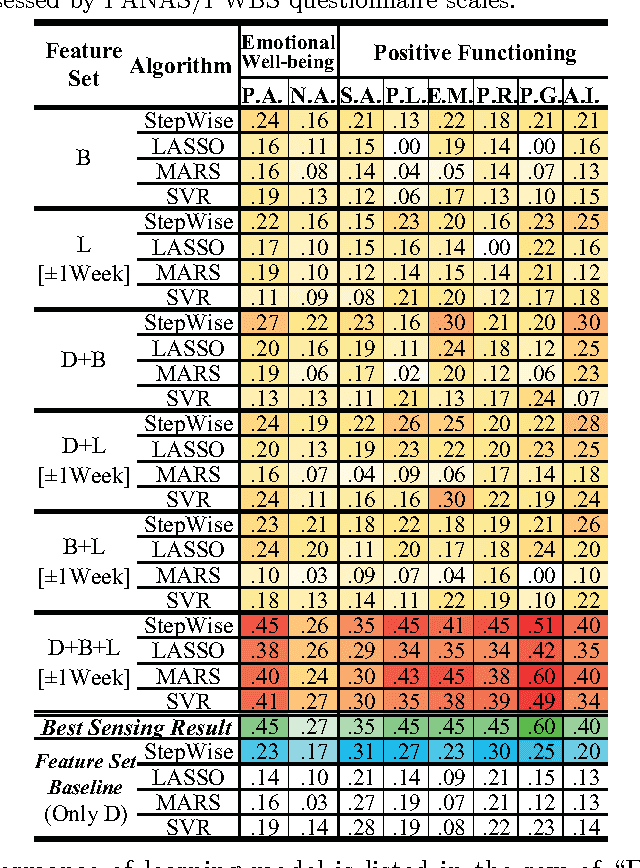
Subjective Well-being(SWB), which refers to how people experience the quality of their lives, is of great use to public policy-makers as well as economic, sociological research, etc. Traditionally, the measurement of SWB relies on time-consuming and costly self-report questionnaires. Nowadays, people are motivated to share their experiences and feelings on social media, so we propose to sense SWB from the vast user generated data on social media. By utilizing 1785 users' social media data with SWB labels, we train machine learning models that are able to "sense" individual SWB from users' social media. Our model, which attains the state-by-art prediction accuracy, can then be used to identify SWB of large population of social media users in time with very low cost.