 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpertized Caption Auto-Enhancement for Video-Text Retrieval
Feb 05, 2025



The burgeoning field of video-text retrieval has witnessed significant advancements with the advent of deep learning. However, the challenge of matching text and video persists due to inadequate textual descriptions of videos. The substantial information gap between the two modalities hinders a comprehensive understanding of videos, resulting in ambiguous retrieval results. While rewriting methods based on large language models have been proposed to broaden text expressions, carefully crafted prompts are essential to ensure the reasonableness and completeness of the rewritten texts. This paper proposes an automatic caption enhancement method that enhances expression quality and mitigates empiricism in augmented captions through self-learning. Additionally, an expertized caption selection mechanism is designed and introduced to customize augmented captions for each video, facilitating video-text matching. Our method is entirely data-driven, which not only dispenses with heavy data collection and computation workload but also improves self-adaptability by circumventing lexicon dependence and introducing personalized matching. The superiority of our method is validated by state-of-the-art results on various benchmarks, specifically achieving Top-1 recall accuracy of 68.5% on MSR-VTT, 68.1% on MSVD, and 62.0% on DiDeMo.
DrasCLR: A Self-supervised Framework of Learning Disease-related and Anatomy-specific Representation for 3D Medical Images
Mar 15, 2023



Large-scale volumetric medical images with annotation are rare, costly, and time prohibitive to acquire. Self-supervised learning (SSL) offers a promising pre-training and feature extraction solution for many downstream tasks, as it only uses unlabeled data. Recently, SSL methods based on instance discrimination have gained popularity in the medical imaging domain. However, SSL pre-trained encoders may use many clues in the image to discriminate an instance that are not necessarily disease-related. Moreover, pathological patterns are often subtle and heterogeneous, requiring the ability of the desired method to represent anatomy-specific features that are sensitive to abnormal changes in different body parts. In this work, we present a novel SSL framework, named DrasCLR, for 3D medical imaging to overcome these challenges. We propose two domain-specific contrastive learning strategies: one aims to capture subtle disease patterns inside a local anatomical region, and the other aims to represent severe disease patterns that span larger regions. We formulate the encoder using conditional hyper-parameterized network, in which the parameters are dependant on the anatomical location, to extract anatomically sensitive features. Extensive experiments on large-scale computer tomography (CT) datasets of lung images show that our method improves the performance of many downstream prediction and segmentation tasks. The patient-level representation improves the performance of the patient survival prediction task. We show how our method can detect emphysema subtypes via dense prediction. We demonstrate that fine-tuning the pre-trained model can significantly reduce annotation efforts without sacrificing emphysema detection accuracy. Our ablation study highlights the importance of incorporating anatomical context into the SSL framework.
Hierarchical Amortized Training for Memory-efficient High Resolution 3D GAN
Aug 05, 2020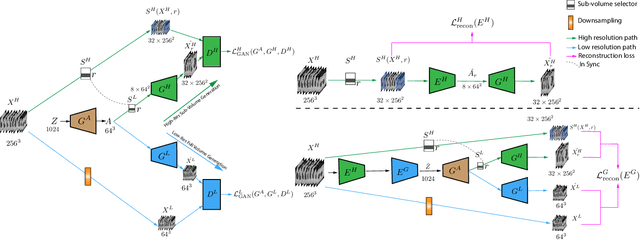
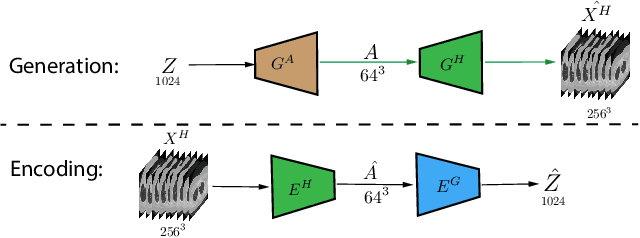
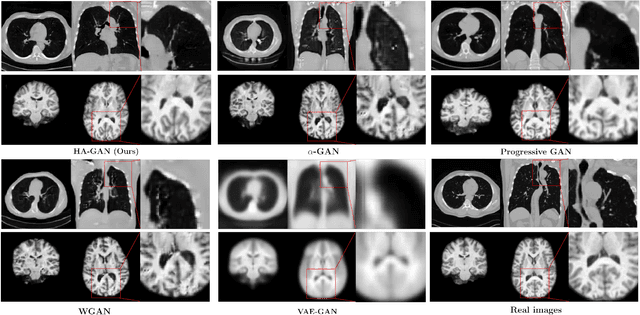
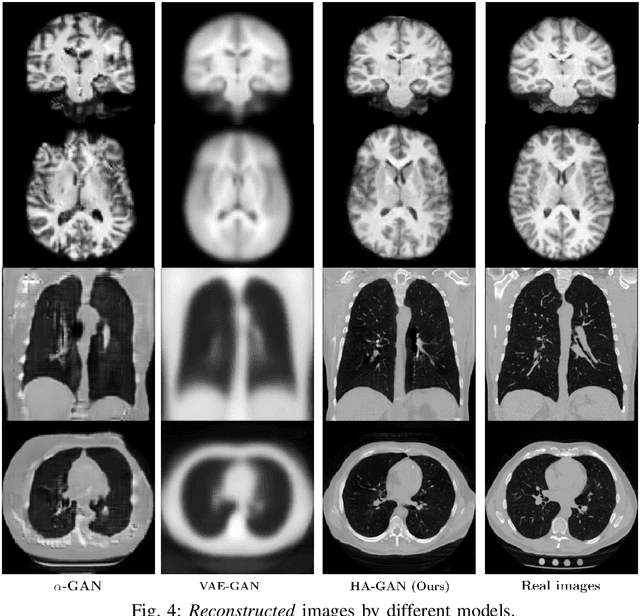
Generative Adversarial Networks (GAN) have many potential medical imaging applications, including data augmentation, domain adaptation, and model explanation. Due to the limited embedded memory of Graphical Processing Units (GPUs), most current 3D GAN models are trained on low-resolution medical images. In this work, we propose a novel end-to-end GAN architecture that can generate high-resolution 3D images. We achieve this goal by separating training and inference. During training, we adopt a hierarchical structure that simultaneously generates a low-resolution version of the image and a randomly selected sub-volume of the high-resolution image. The hierarchical design has two advantages: First, the memory demand for training on high-resolution images is amortized among subvolumes. Furthermore, anchoring the high-resolution subvolumes to a single low-resolution image ensures anatomical consistency between subvolumes. During inference, our model can directly generate full high-resolution images. We also incorporate an encoder with a similar hierarchical structure into the model to extract features from the images. Experiments on 3D thorax CT and brain MRI demonstrate that our approach outperforms state of the art in image generation, image reconstruction, and clinical-relevant variables prediction.
Twitter discussions and emotions about COVID-19 pandemic: a machine learning approach
Jun 19, 2020



The objective of the study is to examine coronavirus disease (COVID-19) related discussions, concerns, and sentiments that emerged from tweets posted by Twitter users. We analyze 4 million Twitter messages related to the COVID-19 pandemic using a list of 25 hashtags such as "coronavirus," "COVID-19," "quarantine" from March 1 to April 21 in 2020. We use a machine learning approach, Latent Dirichlet Allocation (LDA), to identify popular unigram, bigrams, salient topics and themes, and sentiments in the collected Tweets. Popular unigrams include "virus," "lockdown," and "quarantine." Popular bigrams include "COVID-19," "stay home," "corona virus," "social distancing," and "new cases." We identify 13 discussion topics and categorize them into five different themes, such as "public health measures to slow the spread of COVID-19," "social stigma associated with COVID-19," "coronavirus news cases and deaths," "COVID-19 in the United States," and "coronavirus cases in the rest of the world". Across all identified topics, the dominant sentiments for the spread of coronavirus are anticipation that measures that can be taken, followed by a mixed feeling of trust, anger, and fear for different topics. The public reveals a significant feeling of fear when they discuss the coronavirus new cases and deaths than other topics. The study shows that Twitter data and machine learning approaches can be leveraged for infodemiology study by studying the evolving public discussions and sentiments during the COVID-19. Real-time monitoring and assessment of the Twitter discussion and concerns can be promising for public health emergency responses and planning. Already emerged pandemic fear, stigma, and mental health concerns may continue to influence public trust when there occurs a second wave of COVID-19 or a new surge of the imminent pandemic.
Machine learning on Big Data from Twitter to understand public reactions to COVID-19
May 22, 2020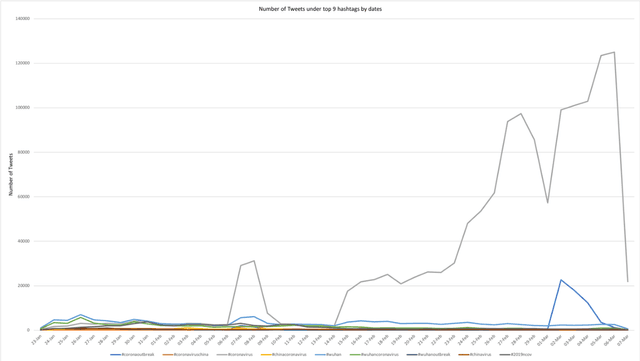



The study aims to understand Twitter users' discussions and reactions about the COVID-19. We use machine learning techniques to analyze about 1.8 million Tweets messages related to coronavirus collected from January 20th to March 7th, 2020. A total of salient 11 topics are identified and then categorized into 10 themes, such as "cases outside China (worldwide)," "COVID-19 outbreak in South Korea," "early signs of the outbreak in New York," "Diamond Princess cruise," "economic impact," "Preventive/Protective measures," "authorities," and "supply chain". Results do not reveal treatment and/or symptoms related messages as a prevalent topic on Twitter. We also run sentiment analysis and the results show that trust for the authorities remained a prevalent emotion, but mixed feelings of trust for authorities, fear for the outbreak, and anticipation for the potential preventive measures will be taken are identified. Implications and limitations of the study are also discussed.
Explanation by Progressive Exaggeration
Nov 05, 2019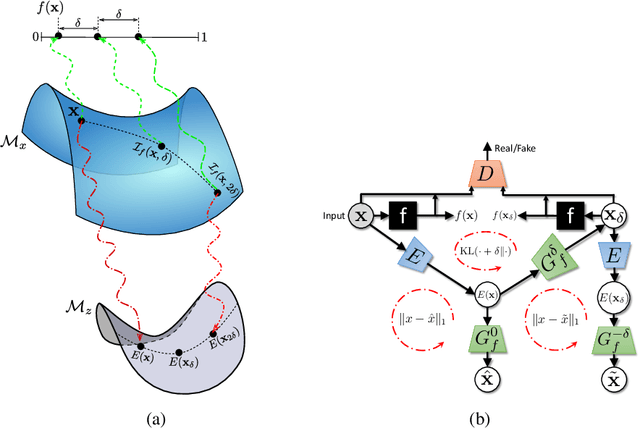

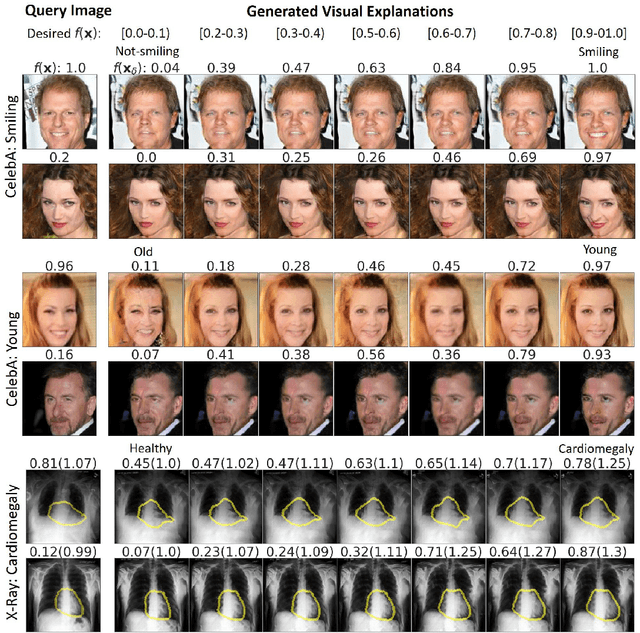

As machine learning methods see greater adoption and implementation in high stakes applications such as medical image diagnosis, the need for model interpretability and explanation has become more critical. Classical approaches that assess feature importance (e.g. saliency maps) do not explain how and why a particular region of an image is relevant to the prediction. We propose a method that explains the outcome of a classification black-box by gradually exaggerating the semantic effect of a given class. Given a query input to a classifier, our method produces a progressive set of plausible variations of that query, which gradually changes the posterior probability from its original class to its negation. These counter-factually generated samples preserve features unrelated to the classification decision, such that a user can employ our method as a "tuning knob" to traverse a data manifold while crossing the decision boundary. Our method is model agnostic and only requires the output value and gradient of the predictor with respect to its input.
Robust Ordinal VAE: Employing Noisy Pairwise Comparisons for Disentanglement
Oct 14, 2019

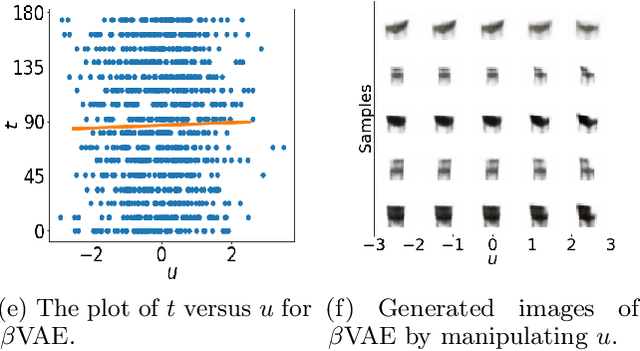

Recent work by Locatello et al. (2018) has shown that an inductive bias is required to disentangle factors of interest in Variational Autoencoder (VAE). Motivated by a real-world problem, we propose a setting where such bias is introduced by providing pairwise ordinal comparisons between instances, based on the desired factor to be disentangled. For example, a doctor compares pairs of patients based on the level of severity of their illnesses, and the desired factor is a quantitive level of the disease severity. In a real-world application, the pairwise comparisons are usually noisy. Our method, Robust Ordinal VAE (ROVAE), incorporates the noisy pairwise ordinal comparisons in the disentanglement task. We introduce non-negative random variables in ROVAE, such that it can automatically determine whether each pairwise ordinal comparison is trustworthy and ignore the noisy comparisons. Experimental results demonstrate that ROVAE outperforms existing methods and is more robust to noisy pairwise comparisons in both benchmark datasets and a real-world application.
Weakly Supervised Disentanglement by Pairwise Similarities
Jun 03, 2019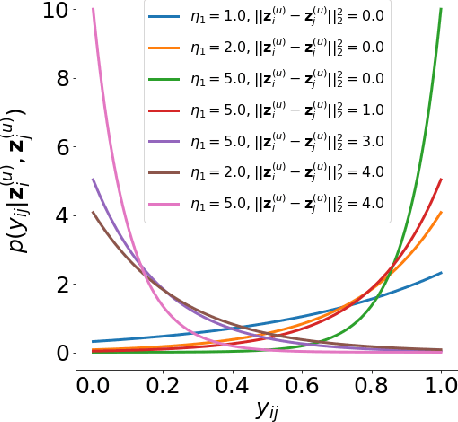
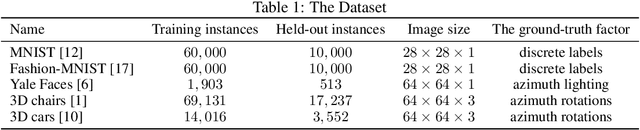
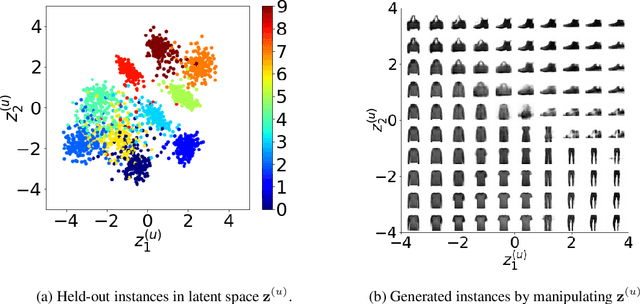
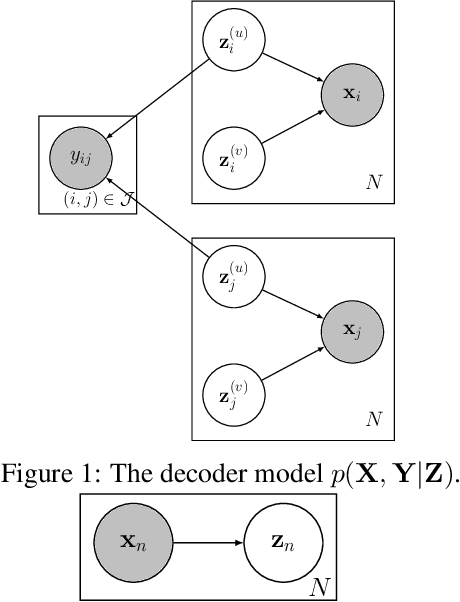
Recently, researches related to unsupervised disentanglement learning with deep generative models have gained substantial popularity. However, without introducing supervision, there is no guarantee that the factors of interest can be successfully recovered. In this paper, we propose a setting where the user introduces weak supervision by providing similarities between instances based on a factor to be disentangled. The similarity is provided as either a discrete (yes/no) or real-valued label describing whether a pair of instances are similar or not. We propose a new method for weakly supervised disentanglement of latent variables within the framework of Variational Autoencoder. Experimental results demonstrate that utilizing weak supervision improves the performance of the disentanglement method substantially.
Generative-Discriminative Complementary Learning
Apr 16, 2019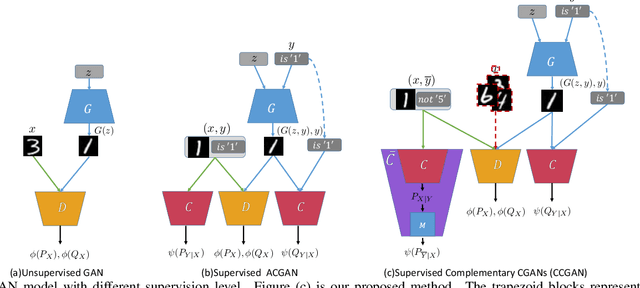
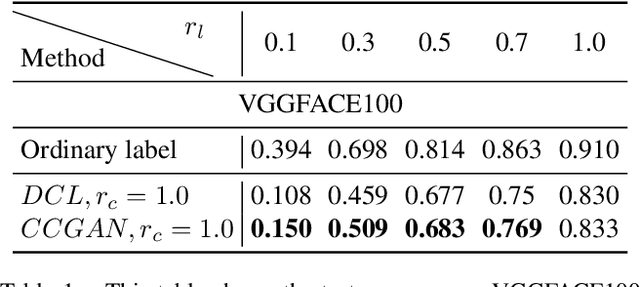
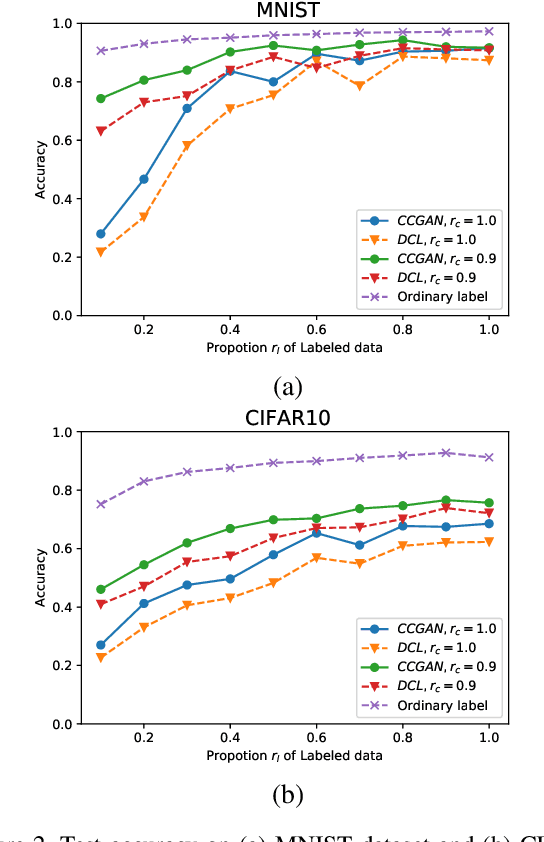

Majority of state-of-the-art deep learning methods for vision applications are discriminative approaches, which model the conditional distribution. The success of such approaches heavily depends on high-quality labeled instances, which are not easy to obtain, especially as the number of candidate classes increases. In this paper, we study the complementary learning problem. Unlike ordinary labels, complementary labels are easy to obtain because an annotator only needs to provide a yes/no answer to a randomly chosen candidate class for each instance. We propose a generative-discriminative complementary learning method that estimates the ordinary labels by modeling both the conditional (discriminative) and instance (generative) distributions. Our method, we call Complementary Conditional GAN (CCGAN), improves the accuracy of predicting ordinary labels and is able to generate high quality instances in spite of weak supervision. In addition to the extensive empirical studies, we also theoretically show that our model can retrieve the true conditional distribution from the complementarily-labeled data.