 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAIS: Memory-Attention for Interactive Segmentation
May 12, 2025

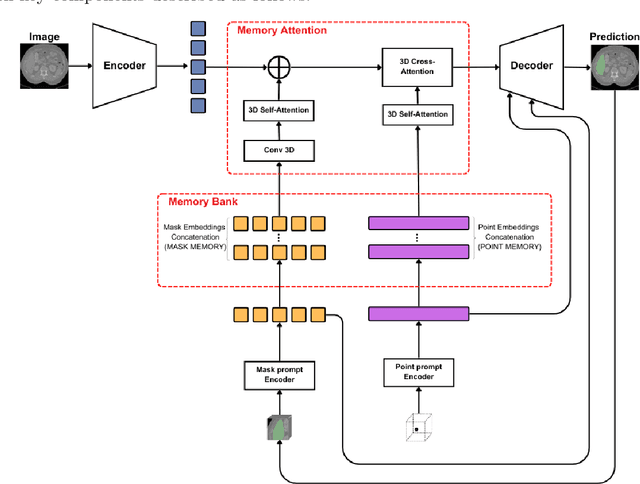

Interactive medical segmentation reduces annotation effort by refining predictions through user feedback. Vision Transformer (ViT)-based models, such as the Segment Anything Model (SAM), achieve state-of-the-art performance using user clicks and prior masks as prompts. However, existing methods treat interactions as independent events, leading to redundant corrections and limited refinement gains. We address this by introducing MAIS, a Memory-Attention mechanism for Interactive Segmentation that stores past user inputs and segmentation states, enabling temporal context integration. Our approach enhances ViT-based segmentation across diverse imaging modalities, achieving more efficient and accurate refinements.
Generative AI for Medical Imaging: extending the MONAI Framework
Jul 27, 2023Recent advances in generative AI have brought incredible breakthroughs in several areas, including medical imaging. These generative models have tremendous potential not only to help safely share medical data via synthetic datasets but also to perform an array of diverse applications, such as anomaly detection, image-to-image translation, denoising, and MRI reconstruction. However, due to the complexity of these models, their implementation and reproducibility can be difficult. This complexity can hinder progress, act as a use barrier, and dissuade the comparison of new methods with existing works. In this study, we present MONAI Generative Models, a freely available open-source platform that allows researchers and developers to easily train, evaluate, and deploy generative models and related applications. Our platform reproduces state-of-art studies in a standardised way involving different architectures (such as diffusion models, autoregressive transformers, and GANs), and provides pre-trained models for the community. We have implemented these models in a generalisable fashion, illustrating that their results can be extended to 2D or 3D scenarios, including medical images with different modalities (like CT, MRI, and X-Ray data) and from different anatomical areas. Finally, we adopt a modular and extensible approach, ensuring long-term maintainability and the extension of current applications for future features.
Using convolution neural networks to learn enhanced fiber orientation distribution models from commercially available diffusion magnetic resonance imaging
Aug 12, 2020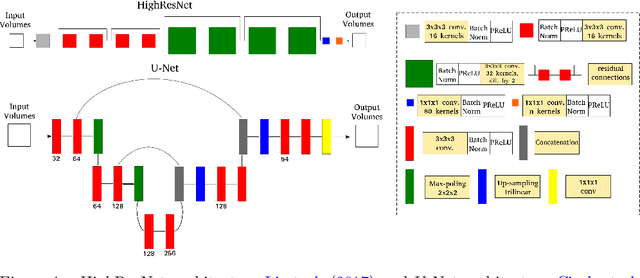
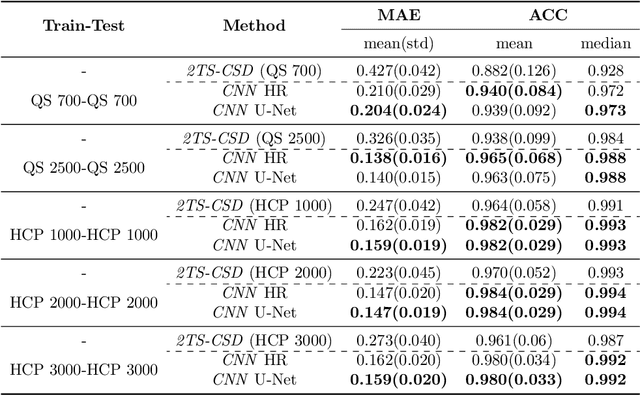
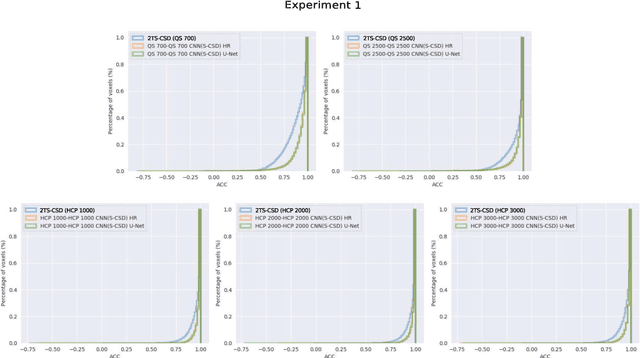
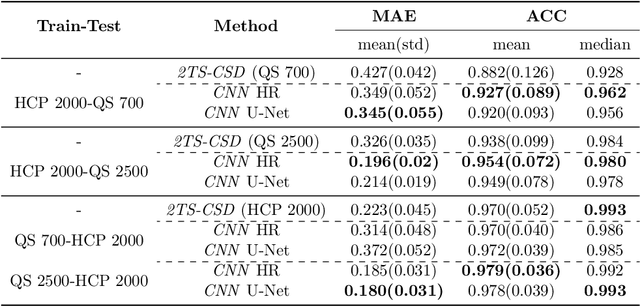
Accurate local fiber orientation distribution (FOD) modeling based on diffusion magnetic resonance imaging (dMRI) capable of resolving complex fiber configurations benefit from specific acquisition protocols that impose a high number of gradient directions (b-vecs), a high maximum b-value (b-vals) and multiple b-values (multi-shell). However, acquisition time is limited in a clinical setting and commercial scanners may not provide robust state-of-the-art dMRI sequences. Therefore, dMRI is often acquired as single-shell (SS) (single b-value). Here, we learn improved FODs for commercially acquired dMRI. We evaluate the use of 3D convolutional neural networks (CNNs) to regress multi-shell FOS representations from single-shell representations, using the spherical harmonics basis obtained from constrained spherical deconvolution (CSD) to model FODs. We use U-Net and HighResNet 3D CNN architectures and data from the publicly available Human Connectome Dataset and a dataset acquired at National Hospital For Neurology and Neurosurgery Queen Square. We evaluate how well the CNN models can resolve local fiber orientation 1) when training and testing on datasets with same dMRI acquisition protocol; 2) when testing on dataset with a different dMRI acquisition protocol than used training the CNN models; and 3) when testing on datasets with a fewer number dMRI gradient directions than used training the CNN models. Our approach may enable robust CSD model estimation on dMRI acquisition protocols which are single shell and with a few gradient directions, reducing acquisition times, and thus, facilitating translation to time-limited clinical environments.
Convolutional Neural Networks for Skull-stripping in Brain MR Imaging using Consensus-based Silver standard Masks
Apr 13, 2018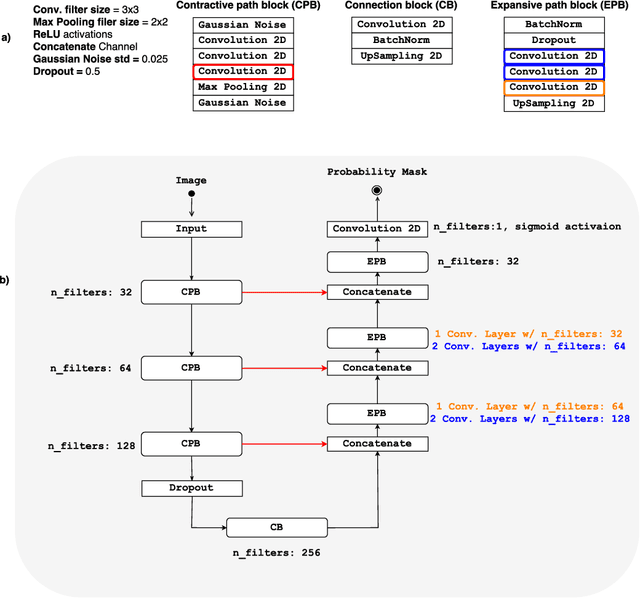
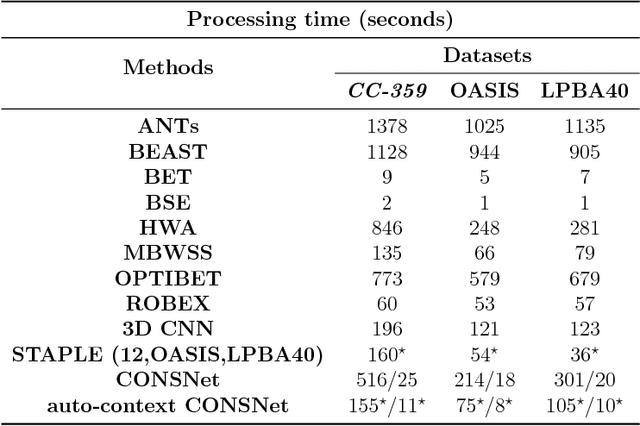
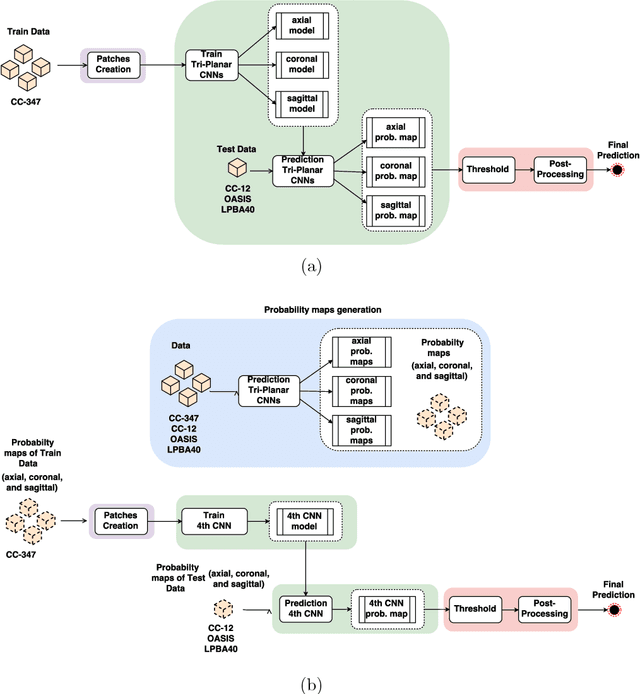
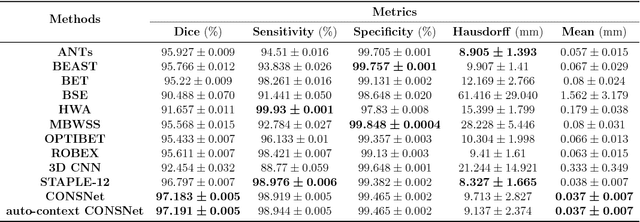
Convolutional neural networks (CNN) for medical imaging are constrained by the number of annotated data required in the training stage. Usually, manual annotation is considered to be the "gold standard". However, medical imaging datasets that include expert manual segmentation are scarce as this step is time-consuming, and therefore expensive. Moreover, single-rater manual annotation is most often used in data-driven approaches making the network optimal with respect to only that single expert. In this work, we propose a CNN for brain extraction in magnetic resonance (MR) imaging, that is fully trained with what we refer to as silver standard masks. Our method consists of 1) developing a dataset with "silver standard" masks as input, and implementing both 2) a tri-planar method using parallel 2D U-Net-based CNNs (referred to as CONSNet) and 3) an auto-context implementation of CONSNet. The term CONSNet refers to our integrated approach, i.e., training with silver standard masks and using a 2D U-Net-based architecture. Our results showed that we outperformed (i.e., larger Dice coefficients) the current state-of-the-art SS methods. Our use of silver standard masks reduced the cost of manual annotation, decreased inter-intra-rater variability, and avoided CNN segmentation super-specialization towards one specific manual annotation guideline that can occur when gold standard masks are used. Moreover, the usage of silver standard masks greatly enlarges the volume of input annotated data because we can relatively easily generate labels for unlabeled data. In addition, our method has the advantage that, once trained, it takes only a few seconds to process a typical brain image volume using modern hardware, such as a high-end graphics processing unit. In contrast, many of the other competitive methods have processing times in the order of minutes.