 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAT-SED: A Masked Audio Transformer with Masked-Reconstruction Based Pre-training for Sound Event Detection
Aug 19, 2024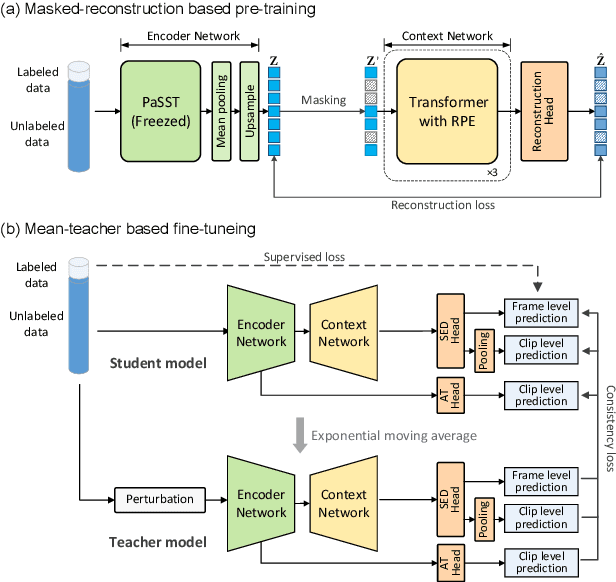

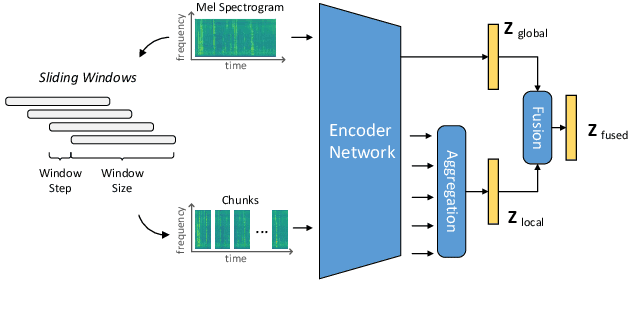

Sound event detection (SED) methods that leverage a large pre-trained Transformer encoder network have shown promising performance in recent DCASE challenges. However, they still rely on an RNN-based context network to model temporal dependencies, largely due to the scarcity of labeled data. In this work, we propose a pure Transformer-based SED model with masked-reconstruction based pre-training, termed MAT-SED. Specifically, a Transformer with relative positional encoding is first designed as the context network, pre-trained by the masked-reconstruction task on all available target data in a self-supervised way. Both the encoder and the context network are jointly fine-tuned in a semi-supervised manner. Furthermore, a global-local feature fusion strategy is proposed to enhance the localization capability. Evaluation of MAT-SED on DCASE2023 task4 surpasses state-of-the-art performance, achieving 0.587/0.896 PSDS1/PSDS2 respectively.
MAT-SED: AMasked Audio Transformer with Masked-Reconstruction Based Pre-training for Sound Event Detection
Aug 16, 2024Sound event detection (SED) methods that leverage a large pre-trained Transformer encoder network have shown promising performance in recent DCASE challenges. However, they still rely on an RNN-based context network to model temporal dependencies, largely due to the scarcity of labeled data. In this work, we propose a pure Transformer-based SED model with masked-reconstruction based pre-training, termed MAT-SED. Specifically, a Transformer with relative positional encoding is first designed as the context network, pre-trained by the masked-reconstruction task on all available target data in a self-supervised way. Both the encoder and the context network are jointly fine-tuned in a semi-supervised manner. Furthermore, a global-local feature fusion strategy is proposed to enhance the localization capability. Evaluation of MAT-SED on DCASE2023 task4 surpasses state-of-the-art performance, achieving 0.587/0.896 PSDS1/PSDS2 respectively.
Make Your Home Safe: Time-aware Unsupervised User Behavior Anomaly Detection in Smart Homes via Loss-guided Mask
Jun 18, 2024



Smart homes, powered by the Internet of Things, offer great convenience but also pose security concerns due to abnormal behaviors, such as improper operations of users and potential attacks from malicious attackers. Several behavior modeling methods have been proposed to identify abnormal behaviors and mitigate potential risks. However, their performance often falls short because they do not effectively learn less frequent behaviors, consider temporal context, or account for the impact of noise in human behaviors. In this paper, we propose SmartGuard, an autoencoder-based unsupervised user behavior anomaly detection framework. First, we design a Loss-guided Dynamic Mask Strategy (LDMS) to encourage the model to learn less frequent behaviors, which are often overlooked during learning. Second, we propose a Three-level Time-aware Position Embedding (TTPE) to incorporate temporal information into positional embedding to detect temporal context anomaly. Third, we propose a Noise-aware Weighted Reconstruction Loss (NWRL) that assigns different weights for routine behaviors and noise behaviors to mitigate the interference of noise behaviors during inference. Comprehensive experiments on three datasets with ten types of anomaly behaviors demonstrates that SmartGuard consistently outperforms state-of-the-art baselines and also offers highly interpretable results.
Unified Modeling Enhanced Multimodal Learning for Precision Neuro-Oncology
Jun 11, 2024



Multimodal learning, integrating histology images and genomics, promises to enhance precision oncology with comprehensive views at microscopic and molecular levels. However, existing methods may not sufficiently model the shared or complementary information for more effective integration. In this study, we introduce a Unified Modeling Enhanced Multimodal Learning (UMEML) framework that employs a hierarchical attention structure to effectively leverage shared and complementary features of both modalities of histology and genomics. Specifically, to mitigate unimodal bias from modality imbalance, we utilize a query-based cross-attention mechanism for prototype clustering in the pathology encoder. Our prototype assignment and modularity strategy are designed to align shared features and minimizes modality gaps. An additional registration mechanism with learnable tokens is introduced to enhance cross-modal feature integration and robustness in multimodal unified modeling. Our experiments demonstrate that our method surpasses previous state-of-the-art approaches in glioma diagnosis and prognosis tasks, underscoring its superiority in precision neuro-Oncology.
P-MSDiff: Parallel Multi-Scale Diffusion for Remote Sensing Image Segmentation
May 30, 2024



Diffusion models and multi-scale features are essential components in semantic segmentation tasks that deal with remote-sensing images. They contribute to improved segmentation boundaries and offer significant contextual information. U-net-like architectures are frequently employed in diffusion models for segmentation tasks. These architectural designs include dense skip connections that may pose challenges for interpreting intermediate features. Consequently, they might not efficiently convey semantic information throughout various layers of the encoder-decoder architecture. To address these challenges, we propose a new model for semantic segmentation known as the diffusion model with parallel multi-scale branches. This model consists of Parallel Multiscale Diffusion modules (P-MSDiff) and a Cross-Bridge Linear Attention mechanism (CBLA). P-MSDiff enhances the understanding of semantic information across multiple levels of granularity and detects repetitive distribution data through the integration of recursive denoising branches. It further facilitates the amalgamation of data by connecting relevant branches to the primary framework to enable concurrent denoising. Furthermore, within the interconnected transformer architecture, the LA module has been substituted with the CBLA module. This module integrates a semidefinite matrix linked to the query into the dot product computation of keys and values. This integration enables the adaptation of queries within the LA framework. This adjustment enhances the structure for multi-head attention computation, leading to enhanced network performance and CBLA is a plug-and-play module. Our model demonstrates superior performance based on the J1 metric on both the UAVid and Vaihingen Building datasets, showing improvements of 1.60% and 1.40% over strong baseline models, respectively.
Evaluating the Application of ChatGPT in Outpatient Triage Guidance: A Comparative Study
Apr 27, 2024



The integration of Artificial Intelligence (AI) in healthcare presents a transformative potential for enhancing operational efficiency and health outcomes. Large Language Models (LLMs), such as ChatGPT, have shown their capabilities in supporting medical decision-making. Embedding LLMs in medical systems is becoming a promising trend in healthcare development. The potential of ChatGPT to address the triage problem in emergency departments has been examined, while few studies have explored its application in outpatient departments. With a focus on streamlining workflows and enhancing efficiency for outpatient triage, this study specifically aims to evaluate the consistency of responses provided by ChatGPT in outpatient guidance, including both within-version response analysis and between-version comparisons. For within-version, the results indicate that the internal response consistency for ChatGPT-4.0 is significantly higher than ChatGPT-3.5 (p=0.03) and both have a moderate consistency (71.2% for 4.0 and 59.6% for 3.5) in their top recommendation. However, the between-version consistency is relatively low (mean consistency score=1.43/3, median=1), indicating few recommendations match between the two versions. Also, only 50% top recommendations match perfectly in the comparisons. Interestingly, ChatGPT-3.5 responses are more likely to be complete than those from ChatGPT-4.0 (p=0.02), suggesting possible differences in information processing and response generation between the two versions. The findings offer insights into AI-assisted outpatient operations, while also facilitating the exploration of potentials and limitations of LLMs in healthcare utilization. Future research may focus on carefully optimizing LLMs and AI integration in healthcare systems based on ergonomic and human factors principles, precisely aligning with the specific needs of effective outpatient triage.
FPL+: Filtered Pseudo Label-based Unsupervised Cross-Modality Adaptation for 3D Medical Image Segmentation
Apr 07, 2024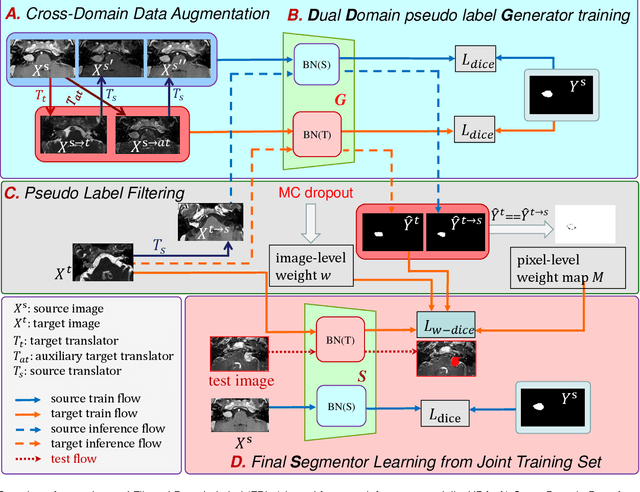
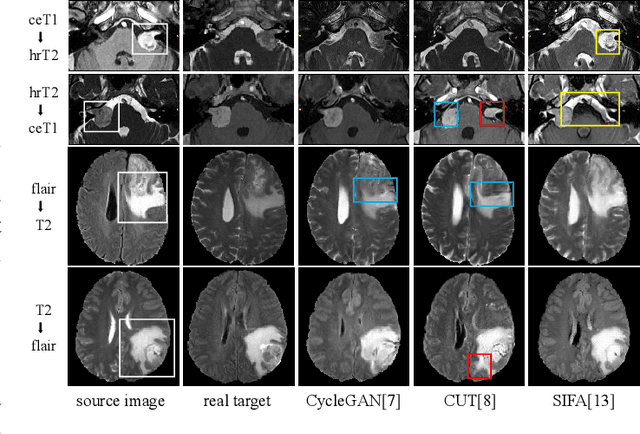
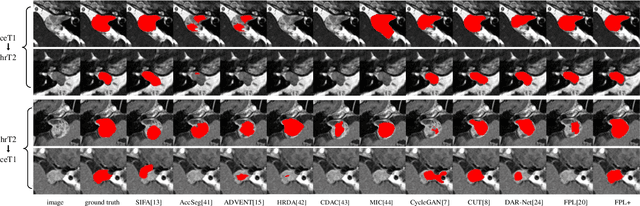

Adapting a medical image segmentation model to a new domain is important for improving its cross-domain transferability, and due to the expensive annotation process, Unsupervised Domain Adaptation (UDA) is appealing where only unlabeled images are needed for the adaptation. Existing UDA methods are mainly based on image or feature alignment with adversarial training for regularization, and they are limited by insufficient supervision in the target domain. In this paper, we propose an enhanced Filtered Pseudo Label (FPL+)-based UDA method for 3D medical image segmentation. It first uses cross-domain data augmentation to translate labeled images in the source domain to a dual-domain training set consisting of a pseudo source-domain set and a pseudo target-domain set. To leverage the dual-domain augmented images to train a pseudo label generator, domain-specific batch normalization layers are used to deal with the domain shift while learning the domain-invariant structure features, generating high-quality pseudo labels for target-domain images. We then combine labeled source-domain images and target-domain images with pseudo labels to train a final segmentor, where image-level weighting based on uncertainty estimation and pixel-level weighting based on dual-domain consensus are proposed to mitigate the adverse effect of noisy pseudo labels. Experiments on three public multi-modal datasets for Vestibular Schwannoma, brain tumor and whole heart segmentation show that our method surpassed ten state-of-the-art UDA methods, and it even achieved better results than fully supervised learning in the target domain in some cases.
OpenMEDLab: An Open-source Platform for Multi-modality Foundation Models in Medicine
Mar 04, 2024



The emerging trend of advancing generalist artificial intelligence, such as GPTv4 and Gemini, has reshaped the landscape of research (academia and industry) in machine learning and many other research areas. However, domain-specific applications of such foundation models (e.g., in medicine) remain untouched or often at their very early stages. It will require an individual set of transfer learning and model adaptation techniques by further expanding and injecting these models with domain knowledge and data. The development of such technologies could be largely accelerated if the bundle of data, algorithms, and pre-trained foundation models were gathered together and open-sourced in an organized manner. In this work, we present OpenMEDLab, an open-source platform for multi-modality foundation models. It encapsulates not only solutions of pioneering attempts in prompting and fine-tuning large language and vision models for frontline clinical and bioinformatic applications but also building domain-specific foundation models with large-scale multi-modal medical data. Importantly, it opens access to a group of pre-trained foundation models for various medical image modalities, clinical text, protein engineering, etc. Inspiring and competitive results are also demonstrated for each collected approach and model in a variety of benchmarks for downstream tasks. We welcome researchers in the field of medical artificial intelligence to continuously contribute cutting-edge methods and models to OpenMEDLab, which can be accessed via https://github.com/openmedlab.
Increasing SAM Zero-Shot Performance on Multimodal Medical Images Using GPT-4 Generated Descriptive Prompts Without Human Annotation
Feb 24, 2024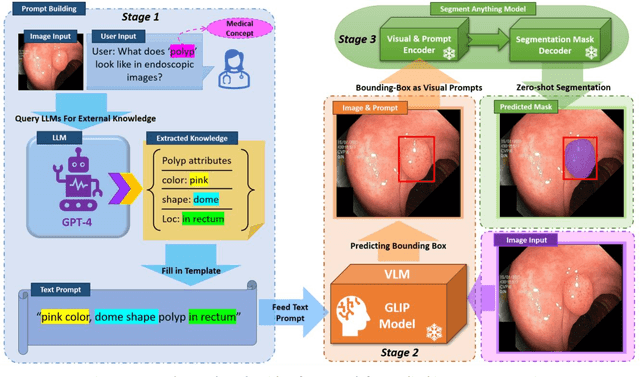
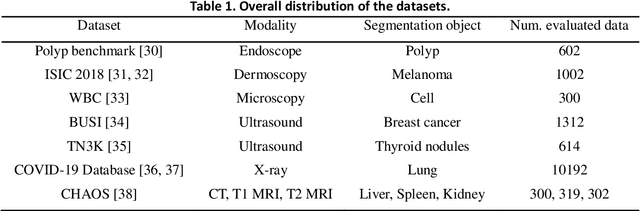
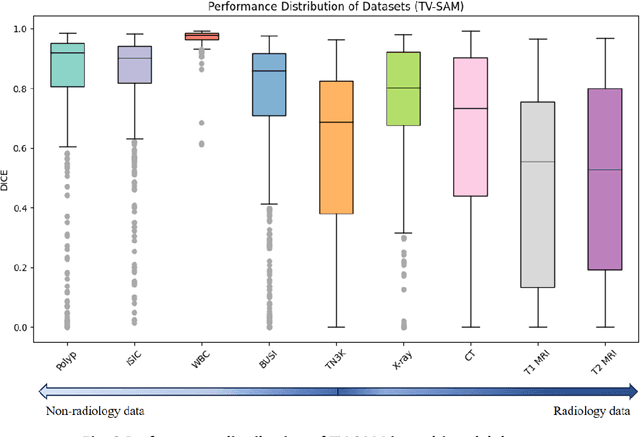
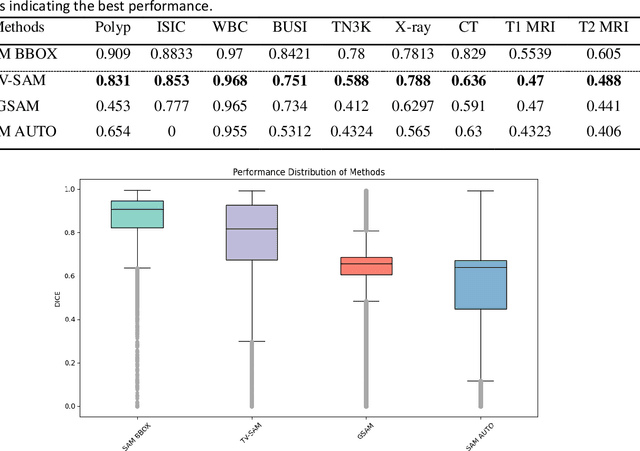
This study develops and evaluates a novel multimodal medical image zero-shot segmentation algorithm named Text-Visual-Prompt SAM (TV-SAM) without any manual annotations. TV-SAM incorporates and integrates large language model GPT-4, Vision Language Model GLIP, and Segment Anything Model (SAM), to autonomously generate descriptive text prompts and visual bounding box prompts from medical images, thereby enhancing SAM for zero-shot segmentation. Comprehensive evaluations are implemented on seven public datasets encompassing eight imaging modalities to demonstrate that TV-SAM can effectively segment unseen targets across various modalities without additional training, significantly outperforming SAM AUTO and GSAM, closely matching the performance of SAM BBOX with gold standard bounding box prompts, and surpassing the state-of-the-art on specific datasets like ISIC and WBC. The study indicates that TV-SAM serves as an effective multimodal medical image zero-shot segmentation algorithm, highlighting the significant contribution of GPT-4 to zero-shot segmentation. By integrating foundational models such as GPT-4, GLIP, and SAM, it could enhance the capability to address complex problems in specialized domains. The code is available at: https://github.com/JZK00/TV-SAM.
Memory-Efficient Prompt Tuning for Incremental Histopathology Classification
Jan 22, 2024Recent studies have made remarkable progress in histopathology classification. Based on current successes, contemporary works proposed to further upgrade the model towards a more generalizable and robust direction through incrementally learning from the sequentially delivered domains. Unlike previous parameter isolation based approaches that usually demand massive computation resources during model updating, we present a memory-efficient prompt tuning framework to cultivate model generalization potential in economical memory cost. For each incoming domain, we reuse the existing parameters of the initial classification model and attach lightweight trainable prompts into it for customized tuning. Considering the domain heterogeneity, we perform decoupled prompt tuning, where we adopt a domain-specific prompt for each domain to independently investigate its distinctive characteristics, and one domain-invariant prompt shared across all domains to continually explore the common content embedding throughout time. All domain-specific prompts will be appended to the prompt bank and isolated from further changes to prevent forgetting the distinctive features of early-seen domains. While the domain-invariant prompt will be passed on and iteratively evolve by style-augmented prompt refining to improve model generalization capability over time. In specific, we construct a graph with existing prompts and build a style-augmented graph attention network to guide the domain-invariant prompt exploring the overlapped latent embedding among all delivered domains for more domain generic representations. We have extensively evaluated our framework with two histopathology tasks, i.e., breast cancer metastasis classification and epithelium-stroma tissue classification, where our approach yielded superior performance and memory efficiency over the competing methods.