 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmplifying robotics capacities with a human touch: An immersive low-latency panoramic remote system
Jan 09, 2024AI and robotics technologies have witnessed remarkable advancements in the past decade, revolutionizing work patterns and opportunities in various domains. The application of these technologies has propelled society towards an era of symbiosis between humans and machines. To facilitate efficient communication between humans and intelligent robots, we propose the "Avatar" system, an immersive low-latency panoramic human-robot interaction platform. We have designed and tested a prototype of a rugged mobile platform integrated with edge computing units, panoramic video capture devices, power batteries, robot arms, and network communication equipment. Under favorable network conditions, we achieved a low-latency high-definition panoramic visual experience with a delay of 357ms. Operators can utilize VR headsets and controllers for real-time immersive control of robots and devices. The system enables remote control over vast physical distances, spanning campuses, provinces, countries, and even continents (New York to Shenzhen). Additionally, the system incorporates visual SLAM technology for map and trajectory recording, providing autonomous navigation capabilities. We believe that this intuitive system platform can enhance efficiency and situational experience in human-robot collaboration, and with further advancements in related technologies, it will become a versatile tool for efficient and symbiotic cooperation between AI and humans.
Robotic Perception-motion Synergy for Novel Rope Wrapping Tasks
Feb 22, 2023



This paper introduces a novel and general method to address the problem of using a general-purpose robot manipulator with a parallel gripper to wrap a deformable linear object (DLO), called a rope, around a rigid object, called a rod, autonomously. Our method does not require prior knowledge of the physical and geometrical properties of the objects but enables the robot to use real-time RGB-D perception to determine the wrapping state and feedback control to achieve high-quality results. As such, it provides the robot manipulator with the general capabilities to handle wrapping tasks of different rods or ropes. We tested our method on 6 combinations of 3 different ropes and 2 rods. The result shows that the wrapping quality improved and converged within 5 wraps for all test cases.
Describing upper body motions based on the Labanotation for learning-from-observation robots
Sep 18, 2016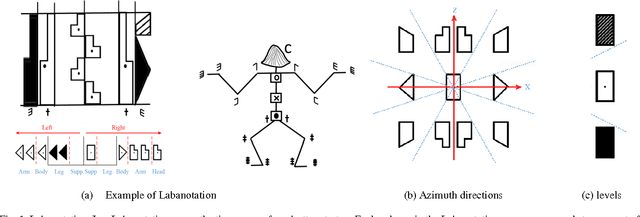
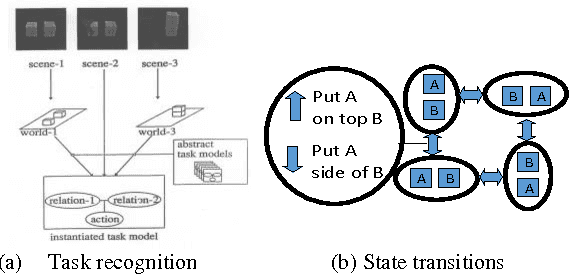
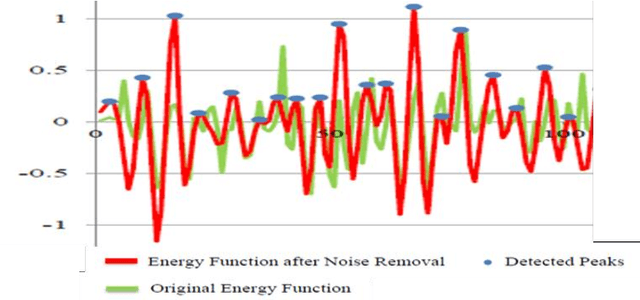
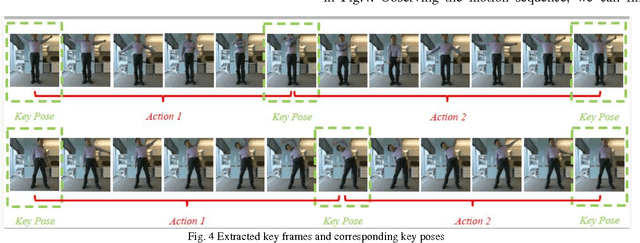
We have been developing a paradigm, which we refer to as Learning-from-observation, for a robot to automatically acquire what-to-do through observation of human performance. Since a simple mimicking method to repeat exact joint angles does not work due to the kinematic and dynamic difference between a human and a robot, the method introduces an intermediate symbolic representation, task models, to conceptually represent what-to-do through observation. Then, these task models are mapped appropriate robot motions depending on each robot hardware. This paper presents task models, designed based on the Labanotation, for upper body movements of humanoid robots. Given a human motion sequence, we first analyze the motions of the upper body, and extract certain fixed poses at certain key frames. These key poses are translated into states represented by Labanotation symbols. Then, task models, identified from the state transitions, are mapped to robot movements on a particular robot hardware. Since the task models based on Labanotation are independent from different robot hardware, we can share the same observation module; we only need task mapping modules depending on different robot hardware. The system was implemented and demonstrated that three different robots can automatically mimic human upper body motions with satisfactory level of resemblance.