 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScanDP: Generalizable 3D Scanning with Diffusion Policy
Mar 11, 2026Learning-based 3D Scanning plays a crucial role in enabling efficient and accurate scanning of target objects. However, recent reinforcement learning-based methods often require large-scale training data and still struggle to generalize to unseen object categories.In this work, we propose a data-efficient 3D scanning framework that uses Diffusion Policy to imitate human-like scanning strategies. To enhance robustness and generalization, we adopt the Occupancy Grid Mapping instead of direct point cloud processing, offering improved noise resilience and handling of diverse object geometries. We also introduce a hybrid approach combining a sphere-based space representation with a path optimization procedure that ensures path safety and scanning efficiency. This approach addresses limitations in conventional imitation learning, such as redundant or unpredictable behavior. We evaluate our method on diverse unseen objects in both shape and scale. Ours achieves higher coverage and shorter paths than baselines, while remaining robust to sensor noise. We further confirm practical feasibility and stable operation in real-world execution.
CAPT: Category-level Articulation Estimation from a Single Point Cloud Using Transformer
Feb 27, 2024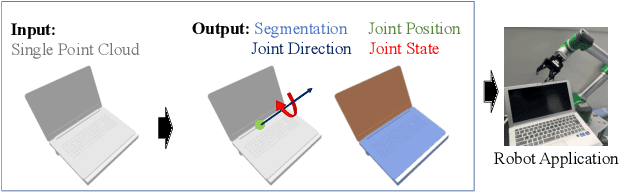
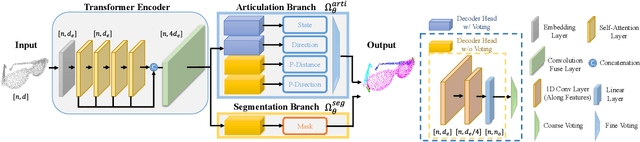
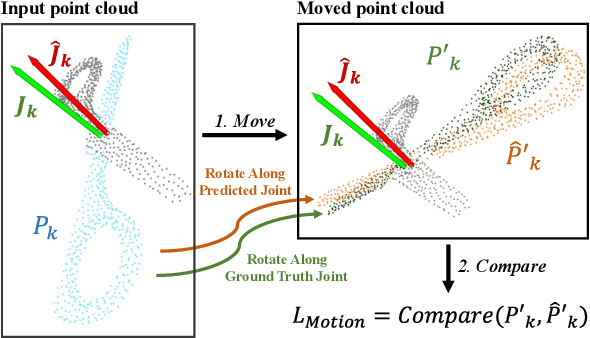
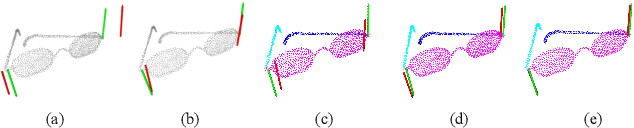
The ability to estimate joint parameters is essential for various applications in robotics and computer vision. In this paper, we propose CAPT: category-level articulation estimation from a point cloud using Transformer. CAPT uses an end-to-end transformer-based architecture for joint parameter and state estimation of articulated objects from a single point cloud. The proposed CAPT methods accurately estimate joint parameters and states for various articulated objects with high precision and robustness. The paper also introduces a motion loss approach, which improves articulation estimation performance by emphasizing the dynamic features of articulated objects. Additionally, the paper presents a double voting strategy to provide the framework with coarse-to-fine parameter estimation. Experimental results on several category datasets demonstrate that our methods outperform existing alternatives for articulation estimation. Our research provides a promising solution for applying Transformer-based architectures in articulated object analysis.
Learning 6DoF Grasping Using Reward-Consistent Demonstration
Mar 23, 2021
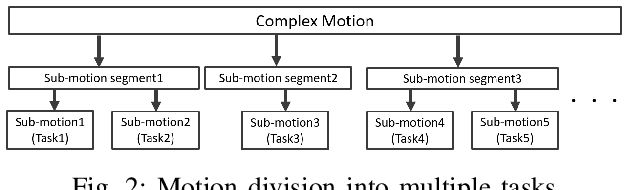
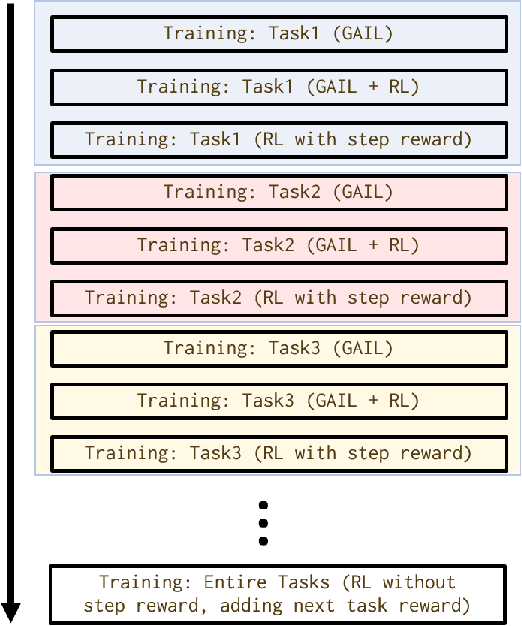

As the number of the robot's degrees of freedom increases, the implementation of robot motion becomes more complex and difficult. In this study, we focus on learning 6DOF-grasping motion and consider dividing the grasping motion into multiple tasks. We propose to combine imitation and reinforcement learning in order to facilitate a more efficient learning of the desired motion. In order to collect demonstration data as teacher data for the imitation learning, we created a virtual reality (VR) interface that allows humans to operate the robot intuitively. Moreover, by dividing the motion into simpler tasks, we simplify the design of reward functions for reinforcement learning and show in our experiments a reduction in the steps required to learn the grasping motion.
Describing upper body motions based on the Labanotation for learning-from-observation robots
Sep 18, 2016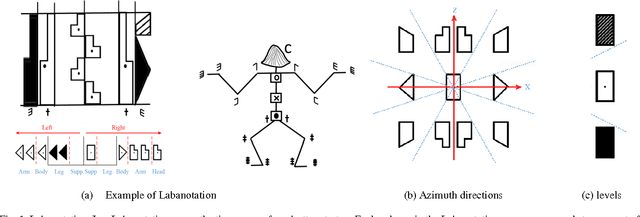
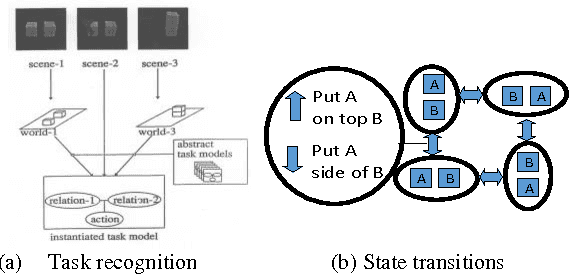
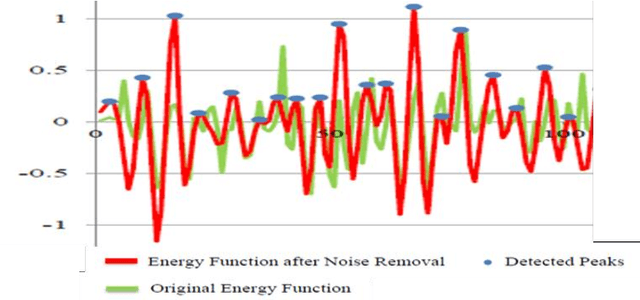
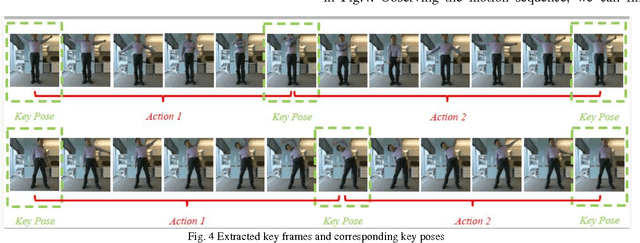
We have been developing a paradigm, which we refer to as Learning-from-observation, for a robot to automatically acquire what-to-do through observation of human performance. Since a simple mimicking method to repeat exact joint angles does not work due to the kinematic and dynamic difference between a human and a robot, the method introduces an intermediate symbolic representation, task models, to conceptually represent what-to-do through observation. Then, these task models are mapped appropriate robot motions depending on each robot hardware. This paper presents task models, designed based on the Labanotation, for upper body movements of humanoid robots. Given a human motion sequence, we first analyze the motions of the upper body, and extract certain fixed poses at certain key frames. These key poses are translated into states represented by Labanotation symbols. Then, task models, identified from the state transitions, are mapped to robot movements on a particular robot hardware. Since the task models based on Labanotation are independent from different robot hardware, we can share the same observation module; we only need task mapping modules depending on different robot hardware. The system was implemented and demonstrated that three different robots can automatically mimic human upper body motions with satisfactory level of resemblance.