 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabeling the Phrase Set of the Conversation Agent, Rinna
Oct 13, 2020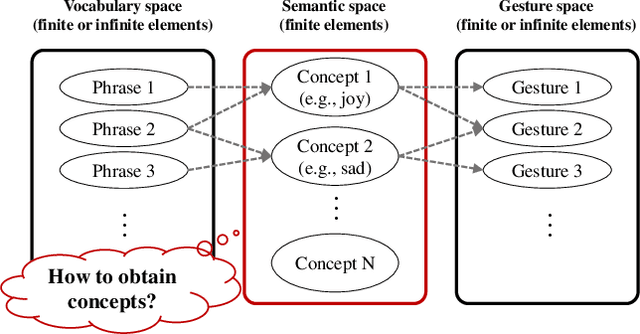

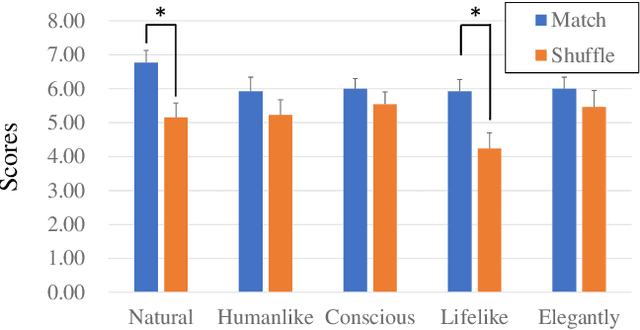

Mapping spoken text to gestures is an important research area for robots with conversation capability. However, mapping a gesture to every spoken text a priori is impossible, especially when a response is automatically generated by a conversation agent. Knowledge of human gesture characteristics can be used to map text to some semantic space where texts with similar meanings are clustered together; then, a mapped gesture is defined for each semantic cluster (i.e., concept). Here, we discuss the practical issues of obtaining concepts for the conversation agent Rinna, which has a personalized vocabulary such as short terms. We compared the concepts obtained automatically with a natural language processing approach and manually with a sociological approach, and we identified three limitations of the former: at the semantic level with emoji and symbols; at the semantic level with slang, new words, and buzzwords; and at the pragmatic level. We consider these problems to be due to the personalized vocabulary of Rinna. To solve these issues, we propose combining manual and autogenerated approaches to map texts to a semantic space. A follow-up experiment showed that a robot gesture selected based on concepts left a better impression than a randomly selected gesture, which suggests the feasibility of applying semantic space to text-to-gesture mapping. The present work contributes insights into developing a methodology for generating gestures of a conversation agent with a personalized vocabulary.
Describing upper body motions based on the Labanotation for learning-from-observation robots
Sep 18, 2016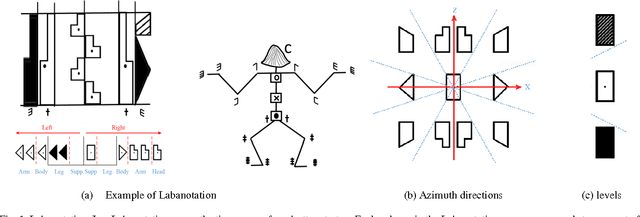
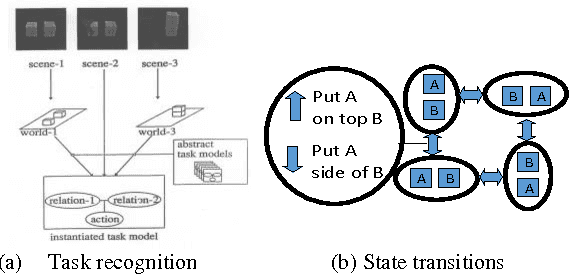
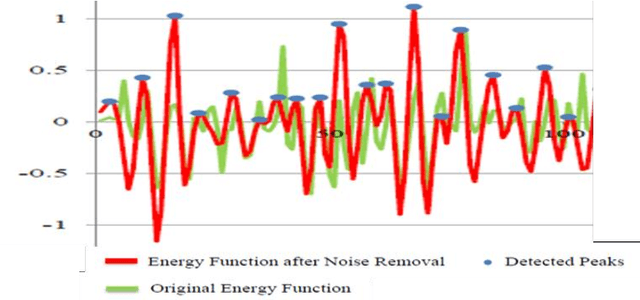
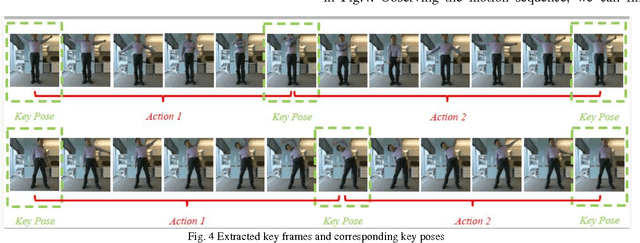
We have been developing a paradigm, which we refer to as Learning-from-observation, for a robot to automatically acquire what-to-do through observation of human performance. Since a simple mimicking method to repeat exact joint angles does not work due to the kinematic and dynamic difference between a human and a robot, the method introduces an intermediate symbolic representation, task models, to conceptually represent what-to-do through observation. Then, these task models are mapped appropriate robot motions depending on each robot hardware. This paper presents task models, designed based on the Labanotation, for upper body movements of humanoid robots. Given a human motion sequence, we first analyze the motions of the upper body, and extract certain fixed poses at certain key frames. These key poses are translated into states represented by Labanotation symbols. Then, task models, identified from the state transitions, are mapped to robot movements on a particular robot hardware. Since the task models based on Labanotation are independent from different robot hardware, we can share the same observation module; we only need task mapping modules depending on different robot hardware. The system was implemented and demonstrated that three different robots can automatically mimic human upper body motions with satisfactory level of resemblance.