 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign of conversational humanoid robot based on hardware independent gesture generation
May 21, 2019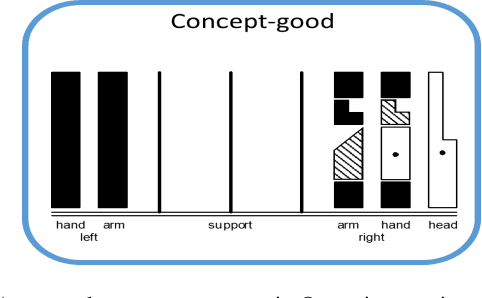
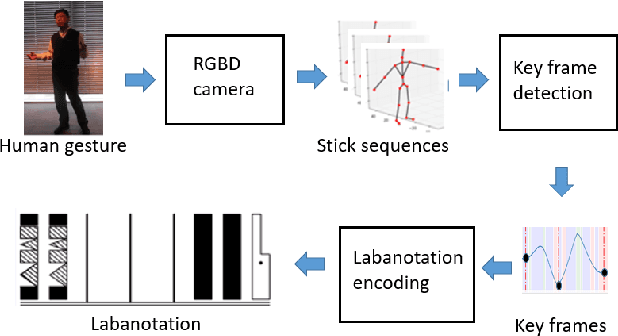
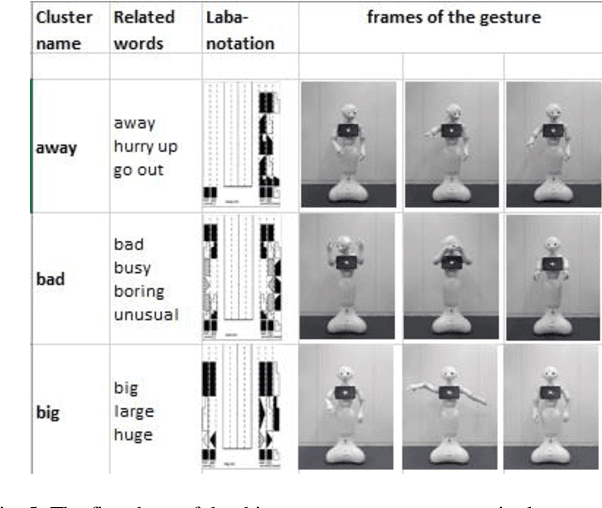
With an increasing need for elderly and disability care, there is an increasing opportunity for intelligent and mobile devices such as robots to provide care and support solutions. In order to naturally assist and interact with humans, a robot must possess effective conversational capabilities. Gestures accompanying spoken sentences are an important factor in human-to-human conversational communication. Humanoid robots must also use gestures if they are to be capable of the rich interactions implied and afforded by their humanlike appearance. However, present systems for gesture generation do not dynamically provide realistic physical gestures that are naturally understood by humans. A method for humanoid robots to generate gestures along with spoken sentences is proposed herein. We emphasize that our gesture-generating architecture can be applied to any type of humanoid robot through the use of labanotation, which is an existing system for notating human dance movements. Labanotation's gesture symbols can computationally transformed to be compatible across a range of robots with doddering physical characteristics. This paper describes a solution as an integrated system for conversational robots whose speech and gestures can supplement each other in human-robot interaction.
Describing upper body motions based on the Labanotation for learning-from-observation robots
Sep 18, 2016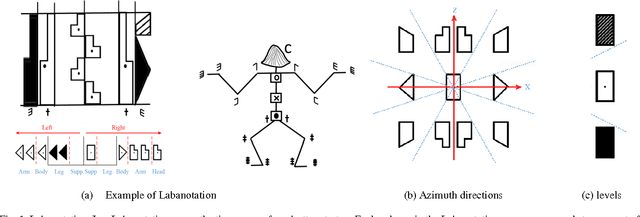
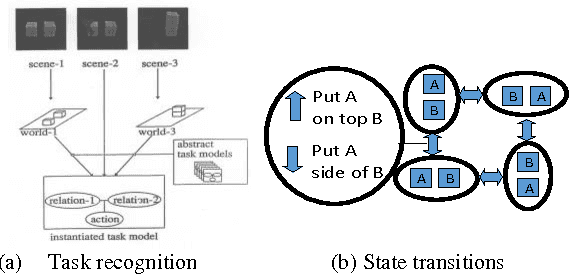
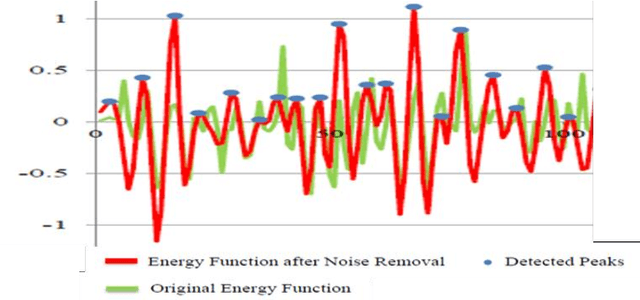
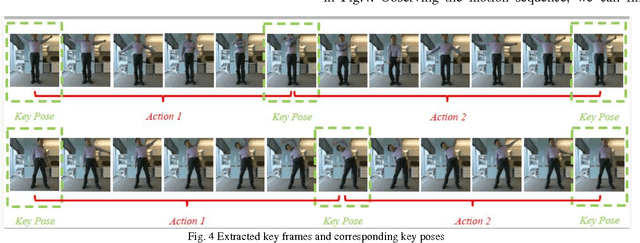
We have been developing a paradigm, which we refer to as Learning-from-observation, for a robot to automatically acquire what-to-do through observation of human performance. Since a simple mimicking method to repeat exact joint angles does not work due to the kinematic and dynamic difference between a human and a robot, the method introduces an intermediate symbolic representation, task models, to conceptually represent what-to-do through observation. Then, these task models are mapped appropriate robot motions depending on each robot hardware. This paper presents task models, designed based on the Labanotation, for upper body movements of humanoid robots. Given a human motion sequence, we first analyze the motions of the upper body, and extract certain fixed poses at certain key frames. These key poses are translated into states represented by Labanotation symbols. Then, task models, identified from the state transitions, are mapped to robot movements on a particular robot hardware. Since the task models based on Labanotation are independent from different robot hardware, we can share the same observation module; we only need task mapping modules depending on different robot hardware. The system was implemented and demonstrated that three different robots can automatically mimic human upper body motions with satisfactory level of resemblance.