 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Native 6G Physical Layer with Cross-Module Optimization and Cooperative Control Agents
Jan 07, 2026In this article, a framework of AI-native cross-module optimized physical layer with cooperative control agents is proposed, which involves optimization across global AI/ML modules of the physical layer with innovative design of multiple enhancement mechanisms and control strategies. Specifically, it achieves simultaneous optimization across global modules of uplink AI/ML-based joint source-channel coding with modulation, and downlink AI/ML-based modulation with precoding and corresponding data detection, reducing traditional inter-module information barriers to facilitate end-to-end optimization toward global objectives. Moreover, multiple enhancement mechanisms are also proposed, including i) an AI/ML-based cross-layer modulation approach with theoretical analysis for downlink transmission that breaks the isolation of inter-layer features to expand the solution space for determining improved constellation, ii) a utility-oriented precoder construction method that shifts the role of the AI/ML-based CSI feedback decoder from recovering the original CSI to directly generating precoding matrices aiming to improve end-to-end performance, and iii) incorporating modulation into AI/ML-based CSI feedback to bypass bit-level bottlenecks that introduce quantization errors, non-differentiable gradients, and limitations in constellation solution spaces. Furthermore, AI/ML based control agents for optimized transmission schemes are proposed that leverage AI/ML to perform model switching according to channel state, thereby enabling integrated control for global throughput optimization. Finally, simulation results demonstrate the superiority of the proposed solutions in terms of BLER and throughput. These extensive simulations employ more practical assumptions that are aligned with the requirements of the 3GPP, which hopefully provides valuable insights for future standardization discussions.
Interference Cancellation Based Neural Receiver for Superimposed Pilot in Multi-Layer Transmission
Jun 27, 2024In this paper, an interference cancellation based neural receiver for superimposed pilot (SIP) in multi-layer transmission is proposed, where the data and pilot are non-orthogonally superimposed in the same time-frequency resource. Specifically, to deal with the intra-layer and inter-layer interference of SIP under multi-layer transmission, the interference cancellation with superimposed symbol aided channel estimation is leveraged in the neural receiver, accompanied by the pre-design of pilot code-division orthogonal mechanism at transmitter. In addition, to address the complexity issue for inter-vendor collaboration and the generalization problem in practical deployments, respectively, this paper also provides a fixed SIP (F-SIP) design based on constant pilot power ratio and scalable mechanisms for different modulation and coding schemes (MCSs) and transmission layers. Simulation results demonstrate the superiority of the proposed schemes on the performance of block error rate and throughput compared with existing counterparts.
Knowledge-driven Meta-learning for CSI Feedback
Oct 25, 2023



Accurate and effective channel state information (CSI) feedback is a key technology for massive multiple-input and multiple-output systems. Recently, deep learning (DL) has been introduced for CSI feedback enhancement through massive collected training data and lengthy training time, which is quite costly and impractical for realistic deployment. In this article, a knowledge-driven meta-learning approach is proposed, where the DL model initialized by the meta model obtained from meta training phase is able to achieve rapid convergence when facing a new scenario during target retraining phase. Specifically, instead of training with massive data collected from various scenarios, the meta task environment is constructed based on the intrinsic knowledge of spatial-frequency characteristics of CSI for meta training. Moreover, the target task dataset is also augmented by exploiting the knowledge of statistical characteristics of wireless channel, so that the DL model can achieve higher performance with small actually collected dataset and short training time. In addition, we provide analyses of rationale for the improvement yielded by the knowledge in both phases. Simulation results demonstrate the superiority of the proposed approach from the perspective of feedback performance and convergence speed.
Toward Extending Concentric Tube Robot Kinematics for Large Clearance and Impulse Curvature
Aug 21, 2023



Concentric Tube Robots (CTRs) have been proposed to operate within the unstructured environment for minimally invasive surgeries. In this letter, we consider the operation scenario where the tubes travel inside the channels with a large clearance or large curvature, such as aortas or industrial pipes. Accurate kinematic modeling of CTRs is required for the development of advanced control and sensing algorithms. To this end, we extended the conventional CTR kinematics model to a more general case with large tube-to-tube clearance and large centerline curvature. Numerical simulations and experimental validations are conducted to compare our model with respect to the conventional CTR kinematic model. In the physical experiments, our proposed model achieved a tip position error of 1.53 mm in the 2D planer case and 4.36 mm in 3D case, outperforming the state-of-the-art model by 71% and 66%, respectively.
Concentric Tube Robot Redundancy Resolution via Velocity/Compliance Manipulability Optimization
May 10, 2023Concentric Tube Robots (CTR) have the potential to enable effective minimally invasive surgeries. While extensive modeling and control schemes have been proposed in the past decade, limited efforts have been made to improve the trajectory tracking performance from the perspective of manipulability , which can be critical to generate safe motion and feasible actuator commands. In this paper, we propose a gradient-based redundancy resolution framework that optimizes velocity/compliance manipulability-based performance indices during trajectory tracking for a kinematically redundant CTR. We efficiently calculate the gradients of manipulabilities by propagating the first- and second-order derivatives of state variables of the Cosserat rod model along the CTR arc length, reducing the gradient computation time by 68\% compared to finite difference method. Task-specific performance indices are optimized by projecting the gradient into the null-space of trajectory tracking. The proposed method is validated in three exemplary scenarios that involve trajectory tracking, obstacle avoidance, and external load compensation, respectively. Simulation results show that the proposed method is able to accomplish the required tasks while commonly used redundancy resolution approaches underperform or even fail.
A Knowledge-Driven Meta-Learning Method for CSI Feedback
Jan 31, 2023Accurate and effective channel state information (CSI) feedback is a key technology for massive multiple-input and multiple-output (MIMO) systems. Recently, deep learning (DL) has been introduced to enhance CSI feedback in massive MIMO application, where the massive collected training data and lengthy training time are costly and impractical for realistic deployment. In this paper, a knowledge-driven meta-learning solution for CSI feedback is proposed, where the DL model initialized by the meta model obtained from meta training phase is able to achieve rapid convergence when facing a new scenario during the target retraining phase. Specifically, instead of training with massive data collected from various scenarios, the meta task environment is constructed based on the intrinsic knowledge of spatial-frequency characteristics of CSI for meta training. Moreover, the target task dataset is also augmented by exploiting the knowledge of statistical characteristics of channel, so that the DL model initialized by meta training can rapidly fit into a new target scenario with higher performance using only a few actually collected data in the target retraining phase. The method greatly reduces the demand for the number of actual collected data, as well as the cost of training time for realistic deployment. Simulation results demonstrate the superiority of the proposed approach from the perspective of feedback performance and convergence speed.
AI Enlightens Wireless Communication: A Transformer Backbone for CSI Feedback
Jun 16, 2022

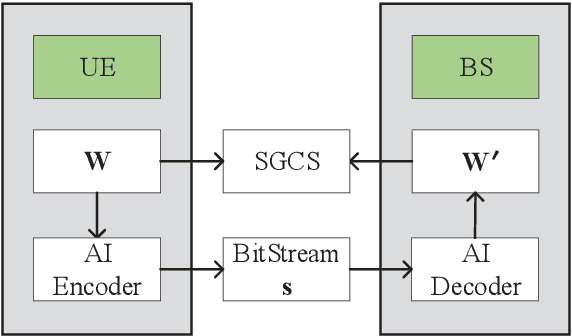
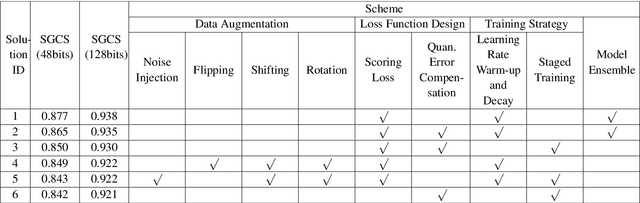
This paper is based on the background of the 2nd Wireless Communication Artificial Intelligence (AI) Competition (WAIC) which is hosted by IMT-2020(5G) Promotion Group 5G+AIWork Group, where the framework of the eigenvector-based channel state information (CSI) feedback problem is firstly provided. Then a basic Transformer backbone for CSI feedback referred to EVCsiNet-T is proposed. Moreover, a series of potential enhancements for deep learning based (DL-based) CSI feedback including i) data augmentation, ii) loss function design, iii) training strategy, and iv) model ensemble are introduced. The experimental results involving the comparison between EVCsiNet-T and traditional codebook methods over different channels are further provided, which show the advanced performance and a promising prospect of Transformer on DL-based CSI feedback problem.
AI Enlightens Wireless Communication: Analyses, Solutions and Opportunities on CSI Feedback
Jun 15, 2021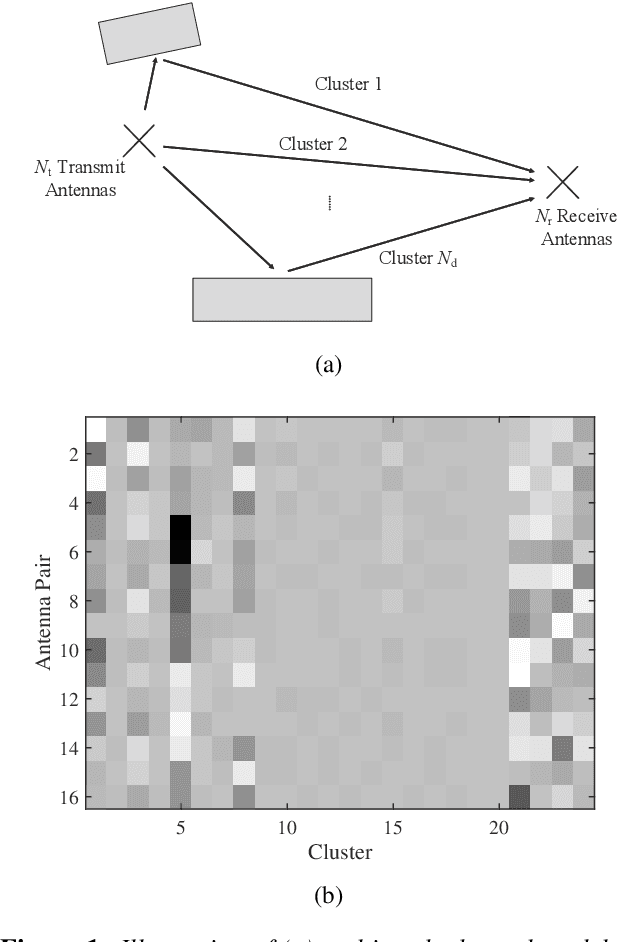
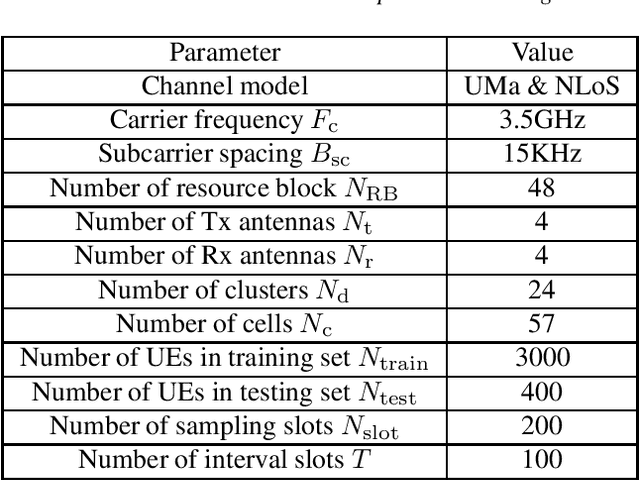
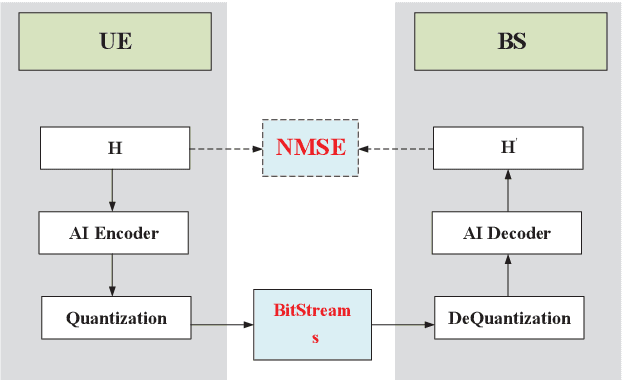
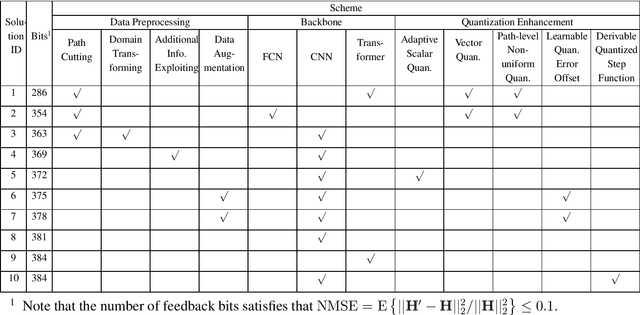
In this paper, we give a systematic description of the 1st Wireless Communication Artificial Intelligence (AI) Competition (WAIC) which is hosted by IMT-2020(5G) Promotion Group 5G+AI Work Group. Firstly, the framework of full channel state information (F-CSI) feedback problem and its corresponding channel dataset are provided. Then the enhancing schemes for DL-based F-CSI feedback including i) channel data analysis and preprocessing, ii) neural network design and iii) quantization enhancement are elaborated. The final competition results composed of different enhancing schemes are presented. Based on the valuable experience of 1st WAIC, we also list some challenges and potential study areas for the design of AI-based wireless communication systems.
Triple-cooperative Video Shadow Detection
Mar 11, 2021

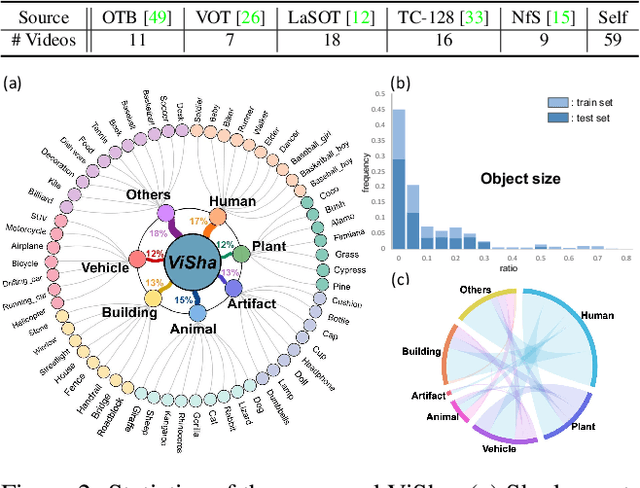
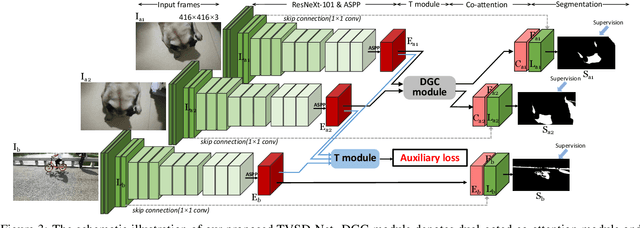
Shadow detection in a single image has received significant research interest in recent years. However, much fewer works have been explored in shadow detection over dynamic scenes. The bottleneck is the lack of a well-established dataset with high-quality annotations for video shadow detection. In this work, we collect a new video shadow detection dataset, which contains 120 videos with 11, 685 frames, covering 60 object categories, varying lengths, and different motion/lighting conditions. All the frames are annotated with a high-quality pixel-level shadow mask. To the best of our knowledge, this is the first learning-oriented dataset for video shadow detection. Furthermore, we develop a new baseline model, named triple-cooperative video shadow detection network (TVSD-Net). It utilizes triple parallel networks in a cooperative manner to learn discriminative representations at intra-video and inter-video levels. Within the network, a dual gated co-attention module is proposed to constrain features from neighboring frames in the same video, while an auxiliary similarity loss is introduced to mine semantic information between different videos. Finally, we conduct a comprehensive study on ViSha, evaluating 12 state-of-the-art models (including single image shadow detectors, video object segmentation, and saliency detection methods). Experiments demonstrate that our model outperforms SOTA competitors.
Enabling Remote Whole-Body Control with 5G Edge Computing
Aug 19, 2020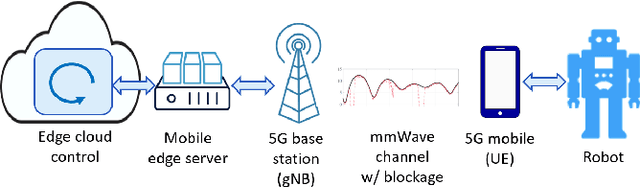
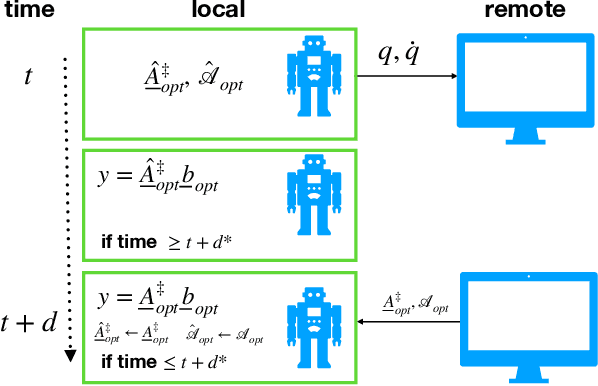
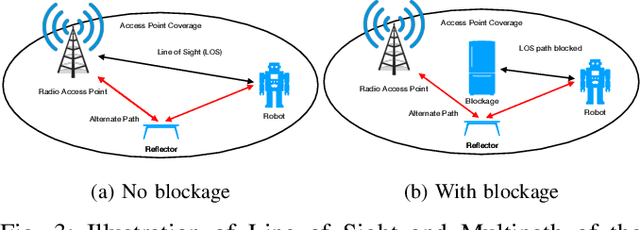
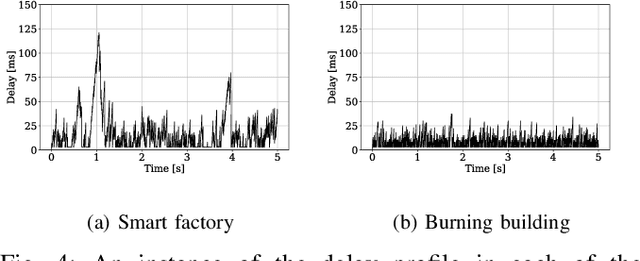
Real-world applications require light-weight, energy-efficient, fully autonomous robots. Yet, increasing autonomy is oftentimes synonymous with escalating computational requirements. It might thus be desirable to offload intensive computation--not only sensing and planning, but also low-level whole-body control--to remote servers in order to reduce on-board computational needs. Fifth Generation (5G) wireless cellular technology, with its low latency and high bandwidth capabilities, has the potential to unlock cloud-based high performance control of complex robots. However, state-of-the-art control algorithms for legged robots can only tolerate very low control delays, which even ultra-low latency 5G edge computing can sometimes fail to achieve. In this work, we investigate the problem of cloud-based whole-body control of legged robots over a 5G link. We propose a novel approach that consists of a standard optimization-based controller on the network edge and a local linear, approximately optimal controller that significantly reduces on-board computational needs while increasing robustness to delay and possible loss of communication. Simulation experiments on humanoid balancing and walking tasks that includes a realistic 5G communication model demonstrate significant improvement of the reliability of robot locomotion under jitter and delays likely to experienced in 5G wireless links.