 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynFacePAD 2023: Competition on Face Presentation Attack Detection Based on Privacy-aware Synthetic Training Data
Nov 09, 2023

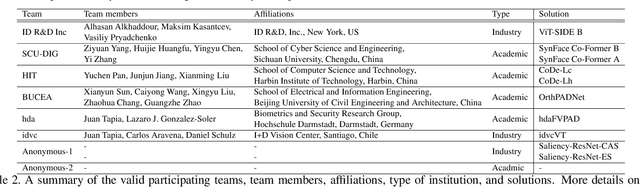
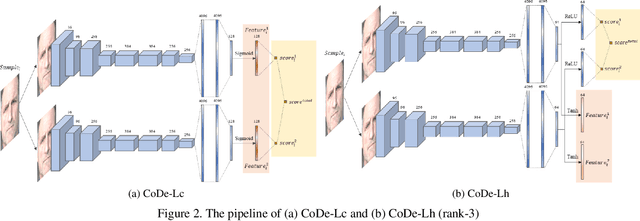
This paper presents a summary of the Competition on Face Presentation Attack Detection Based on Privacy-aware Synthetic Training Data (SynFacePAD 2023) held at the 2023 International Joint Conference on Biometrics (IJCB 2023). The competition attracted a total of 8 participating teams with valid submissions from academia and industry. The competition aimed to motivate and attract solutions that target detecting face presentation attacks while considering synthetic-based training data motivated by privacy, legal and ethical concerns associated with personal data. To achieve that, the training data used by the participants was limited to synthetic data provided by the organizers. The submitted solutions presented innovations and novel approaches that led to outperforming the considered baseline in the investigated benchmarks.
Iris Liveness Detection Competition (LivDet-Iris) -- The 2023 Edition
Oct 06, 2023



This paper describes the results of the 2023 edition of the ''LivDet'' series of iris presentation attack detection (PAD) competitions. New elements in this fifth competition include (1) GAN-generated iris images as a category of presentation attack instruments (PAI), and (2) an evaluation of human accuracy at detecting PAI as a reference benchmark. Clarkson University and the University of Notre Dame contributed image datasets for the competition, composed of samples representing seven different PAI categories, as well as baseline PAD algorithms. Fraunhofer IGD, Beijing University of Civil Engineering and Architecture, and Hochschule Darmstadt contributed results for a total of eight PAD algorithms to the competition. Accuracy results are analyzed by different PAI types, and compared to human accuracy. Overall, the Fraunhofer IGD algorithm, using an attention-based pixel-wise binary supervision network, showed the best-weighted accuracy results (average classification error rate of 37.31%), while the Beijing University of Civil Engineering and Architecture's algorithm won when equal weights for each PAI were given (average classification rate of 22.15%). These results suggest that iris PAD is still a challenging problem.
Visual Realism Assessment for Face-swap Videos
Feb 02, 2023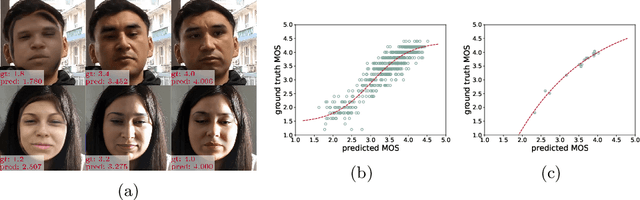
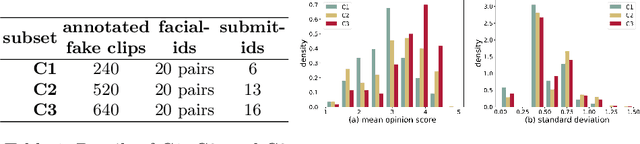
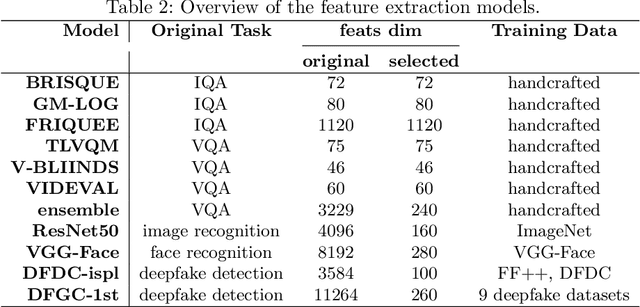
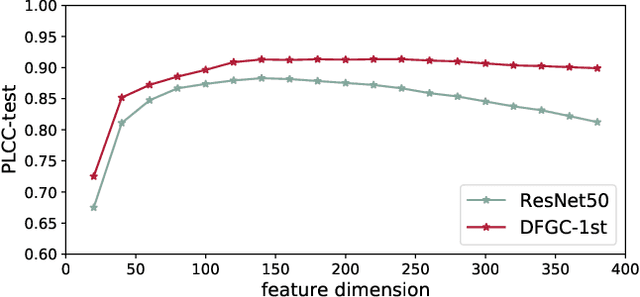
Deep-learning based face-swap videos, also known as deep fakes, are becoming more and more realistic and deceiving. The malicious usage of these face-swap videos has caused wide concerns. The research community has been focusing on the automatic detection of these fake videos, but the as sessment of their visual realism, as perceived by human eyes, is still an unexplored dimension. Visual realism assessment, or VRA, is essential for assessing the potential impact that may be brought by a specific face-swap video, and it is also important as a quality assessment metric to compare different face-swap methods. In this paper, we make a small step to wards this new VRA direction by building a benchmark for evaluating the effectiveness of different automatic VRA models, which range from using traditional hand-crafted features to different kinds of deep-learning features. The evaluations are based on a recent competition dataset named as DFGC 2022, which contains 1400 diverse face-swap videos that are annotated with Mean Opinion Scores (MOS) on visual realism. Comprehensive experiment results using 11 models and 3 protocols are shown and discussed. We demonstrate the feasibility of devising effective VRA models for assessing face-swap videos and methods. The particular usefulness of existing deepfake detection features for VRA is also noted. The code and benchmark will be made publicly available.
CASIA-Face-Africa: A Large-scale African Face Image Database
May 11, 2021

Face recognition is a popular and well-studied area with wide applications in our society. However, racial bias had been proven to be inherent in most State Of The Art (SOTA) face recognition systems. Many investigative studies on face recognition algorithms have reported higher false positive rates of African subjects cohorts than the other cohorts. Lack of large-scale African face image databases in public domain is one of the main restrictions in studying the racial bias problem of face recognition. To this end, we collect a face image database namely CASIA-Face-Africa which contains 38,546 images of 1,183 African subjects. Multi-spectral cameras are utilized to capture the face images under various illumination settings. Demographic attributes and facial expressions of the subjects are also carefully recorded. For landmark detection, each face image in the database is manually labeled with 68 facial keypoints. A group of evaluation protocols are constructed according to different applications, tasks, partitions and scenarios. The performances of SOTA face recognition algorithms without re-training are reported as baselines. The proposed database along with its face landmark annotations, evaluation protocols and preliminary results form a good benchmark to study the essential aspects of face biometrics for African subjects, especially face image preprocessing, face feature analysis and matching, facial expression recognition, sex/age estimation, ethnic classification, face image generation, etc. The database can be downloaded from our http://www.cripacsir.cn/dataset/
Alignment Free and Distortion Robust Iris Recognition
Dec 01, 2019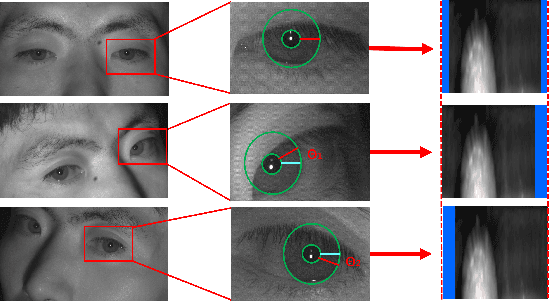
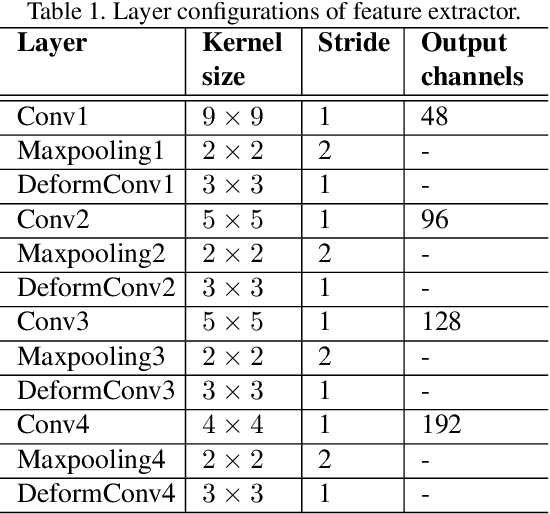
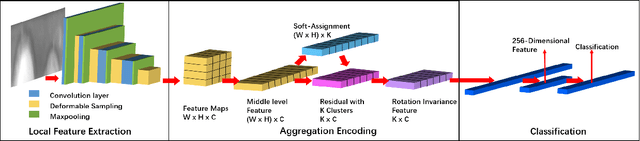
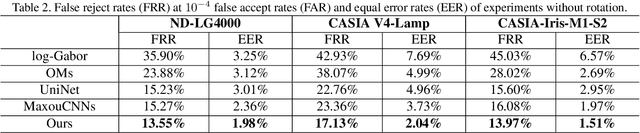
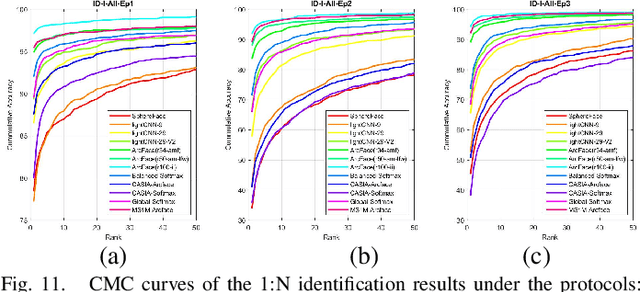
Iris recognition is a reliable personal identification method but there is still much room to improve its accuracy especially in less-constrained situations. For example, free movement of head pose may cause large rotation difference between iris images. And illumination variations may cause irregular distortion of iris texture. To match intra-class iris images with head rotation robustly, the existing solutions usually need a precise alignment operation by exhaustive search within a determined range in iris image preprosessing or brute force searching the minimum Hamming distance in iris feature matching. In the wild, iris rotation is of much greater uncertainty than that in constrained situations and exhaustive search within a determined range is impracticable. This paper presents a unified feature-level solution to both alignment free and distortion robust iris recognition in the wild. A new deep learning based method named Alignment Free Iris Network (AFINet) is proposed, which uses a trainable VLAD (Vector of Locally Aggregated Descriptors) encoder called NetVLAD to decouple the correlations between local representations and their spatial positions. And deformable convolution is used to overcome iris texture distortion by dense adaptive sampling. The results of extensive experiments on three public iris image databases and the simulated degradation databases show that AFINet significantly outperforms state-of-art iris recognition methods.
Joint Iris Segmentation and Localization Using Deep Multi-task Learning Framework
Jan 31, 2019
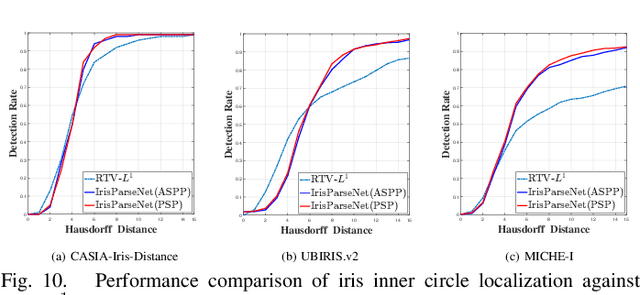
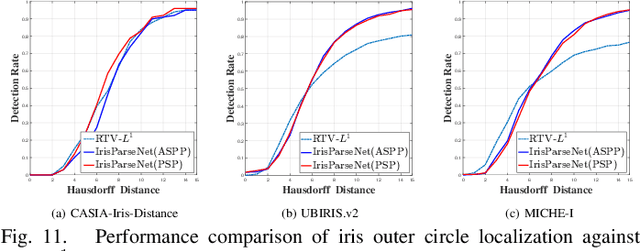
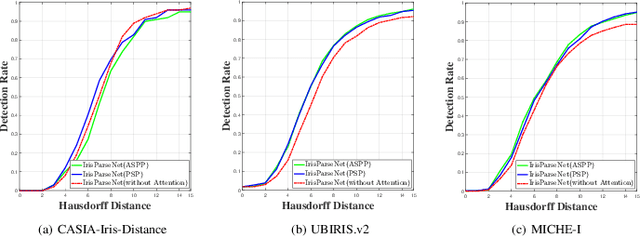
Iris segmentation and localization in non-cooperative environment is challenging due to illumination variations, long distances, moving subjects and limited user cooperation, etc. Traditional methods often suffer from poor performance when confronted with iris images captured in these conditions. Recent studies have shown that deep learning methods could achieve impressive performance on iris segmentation task. In addition, as iris is defined as an annular region between pupil and sclera, geometric constraints could be imposed to help locating the iris more accurately and improve the segmentation results. In this paper, we propose a deep multi-task learning framework, named as IrisParseNet, to exploit the inherent correlations between pupil, iris and sclera to boost up the performance of iris segmentation and localization in a unified model. In particular, IrisParseNet firstly applies a Fully Convolutional Encoder-Decoder Attention Network to simultaneously estimate pupil center, iris segmentation mask and iris inner/outer boundary. Then, an effective post-processing method is adopted for iris inner/outer circle localization.To train and evaluate the proposed method, we manually label three challenging iris datasets, namely CASIA-Iris-Distance, UBIRIS.v2, and MICHE-I, which cover various types of noises. Extensive experiments are conducted on these newly annotated datasets, and results show that our method outperforms state-of-the-art methods on various benchmarks. All the ground-truth annotations, annotation codes and evaluation protocols are publicly available at https://github.com/xiamenwcy/IrisParseNet.