 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndogenous Reprompting: Self-Evolving Cognitive Alignment for Unified Multimodal Models
Jan 28, 2026Unified Multimodal Models (UMMs) exhibit strong understanding, yet this capability often fails to effectively guide generation. We identify this as a Cognitive Gap: the model lacks the understanding of how to enhance its own generation process. To bridge this gap, we propose Endogenous Reprompting, a mechanism that transforms the model's understanding from a passive encoding process into an explicit generative reasoning step by generating self-aligned descriptors during generation. To achieve this, we introduce SEER (Self-Evolving Evaluator and Reprompter), a training framework that establishes a two-stage endogenous loop using only 300 samples from a compact proxy task, Visual Instruction Elaboration. First, Reinforcement Learning with Verifiable Rewards (RLVR) activates the model's latent evaluation ability via curriculum learning, producing a high-fidelity endogenous reward signal. Second, Reinforcement Learning with Model-rewarded Thinking (RLMT) leverages this signal to optimize the generative reasoning policy. Experiments show that SEER consistently outperforms state-of-the-art baselines in evaluation accuracy, reprompting efficiency, and generation quality, without sacrificing general multimodal capabilities.
Visual Realism Assessment for Face-swap Videos
Feb 02, 2023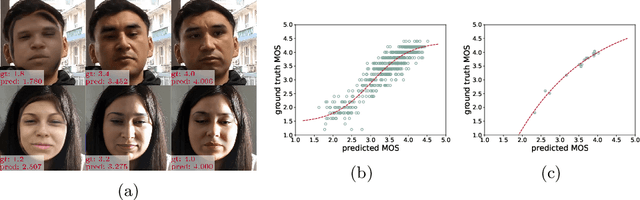
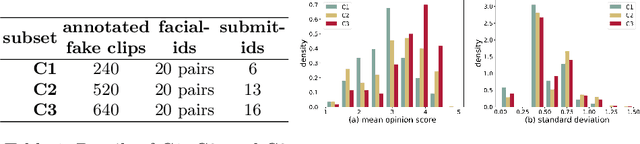
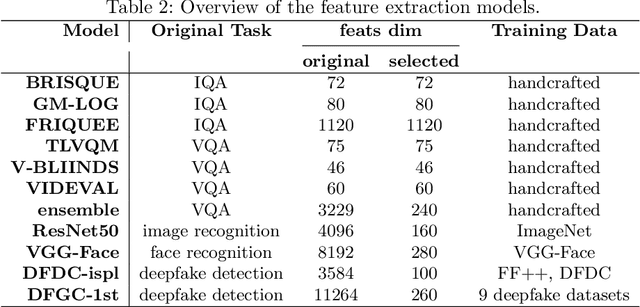
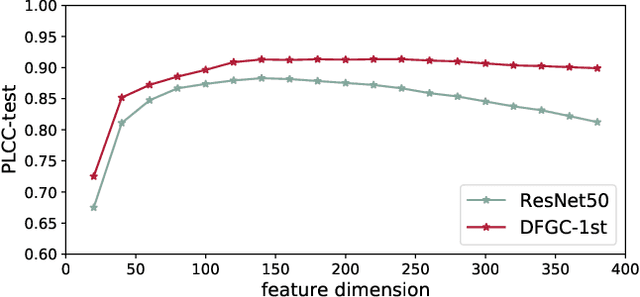
Deep-learning based face-swap videos, also known as deep fakes, are becoming more and more realistic and deceiving. The malicious usage of these face-swap videos has caused wide concerns. The research community has been focusing on the automatic detection of these fake videos, but the as sessment of their visual realism, as perceived by human eyes, is still an unexplored dimension. Visual realism assessment, or VRA, is essential for assessing the potential impact that may be brought by a specific face-swap video, and it is also important as a quality assessment metric to compare different face-swap methods. In this paper, we make a small step to wards this new VRA direction by building a benchmark for evaluating the effectiveness of different automatic VRA models, which range from using traditional hand-crafted features to different kinds of deep-learning features. The evaluations are based on a recent competition dataset named as DFGC 2022, which contains 1400 diverse face-swap videos that are annotated with Mean Opinion Scores (MOS) on visual realism. Comprehensive experiment results using 11 models and 3 protocols are shown and discussed. We demonstrate the feasibility of devising effective VRA models for assessing face-swap videos and methods. The particular usefulness of existing deepfake detection features for VRA is also noted. The code and benchmark will be made publicly available.