 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYolov3
Papers and Code
IoUCert: Robustness Verification for Anchor-based Object Detectors
Mar 04, 2026While formal robustness verification has seen significant success in image classification, scaling these guarantees to object detection remains notoriously difficult due to complex non-linear coordinate transformations and Intersection-over-Union (IoU) metrics. We introduce IoUCert, a novel formal verification framework designed specifically to overcome these bottlenecks in foundational anchor-based object detection architectures. Focusing on the object localisation component in single-object settings, we propose a coordinate transformation that enables our algorithm to circumvent precision-degrading relaxations of non-linear box prediction functions. This allows us to optimise bounds directly with respect to the anchor box offsets which enables a novel Interval Bound Propagation method that derives optimal IoU bounds. We demonstrate that our method enables, for the first time, the robustness verification of realistic, anchor-based models including SSD, YOLOv2, and YOLOv3 variants against various input perturbations.
Streamlining the Development of Active Learning Methods in Real-World Object Detection
Aug 27, 2025Active learning (AL) for real-world object detection faces computational and reliability challenges that limit practical deployment. Developing new AL methods requires training multiple detectors across iterations to compare against existing approaches. This creates high costs for autonomous driving datasets where the training of one detector requires up to 282 GPU hours. Additionally, AL method rankings vary substantially across validation sets, compromising reliability in safety-critical transportation systems. We introduce object-based set similarity ($\mathrm{OSS}$), a metric that addresses these challenges. $\mathrm{OSS}$ (1) quantifies AL method effectiveness without requiring detector training by measuring similarity between training sets and target domains using object-level features. This enables the elimination of ineffective AL methods before training. Furthermore, $\mathrm{OSS}$ (2) enables the selection of representative validation sets for robust evaluation. We validate our similarity-based approach on three autonomous driving datasets (KITTI, BDD100K, CODA) using uncertainty-based AL methods as a case study with two detector architectures (EfficientDet, YOLOv3). This work is the first to unify AL training and evaluation strategies in object detection based on object similarity. $\mathrm{OSS}$ is detector-agnostic, requires only labeled object crops, and integrates with existing AL pipelines. This provides a practical framework for deploying AL in real-world applications where computational efficiency and evaluation reliability are critical. Code is available at https://mos-ks.github.io/publications/.
YOLOv11-RGBT: Towards a Comprehensive Single-Stage Multispectral Object Detection Framework
Jun 18, 2025Multispectral object detection, which integrates information from multiple bands, can enhance detection accuracy and environmental adaptability, holding great application potential across various fields. Although existing methods have made progress in cross-modal interaction, low-light conditions, and model lightweight, there are still challenges like the lack of a unified single-stage framework, difficulty in balancing performance and fusion strategy, and unreasonable modality weight allocation. To address these, based on the YOLOv11 framework, we present YOLOv11-RGBT, a new comprehensive multimodal object detection framework. We designed six multispectral fusion modes and successfully applied them to models from YOLOv3 to YOLOv12 and RT-DETR. After reevaluating the importance of the two modalities, we proposed a P3 mid-fusion strategy and multispectral controllable fine-tuning (MCF) strategy for multispectral models. These improvements optimize feature fusion, reduce redundancy and mismatches, and boost overall model performance. Experiments show our framework excels on three major open-source multispectral object detection datasets, like LLVIP and FLIR. Particularly, the multispectral controllable fine-tuning strategy significantly enhanced model adaptability and robustness. On the FLIR dataset, it consistently improved YOLOv11 models' mAP by 3.41%-5.65%, reaching a maximum of 47.61%, verifying the framework and strategies' effectiveness. The code is available at: https://github.com/wandahangFY/YOLOv11-RGBT.
PaniCar: Securing the Perception of Advanced Driving Assistance Systems Against Emergency Vehicle Lighting
May 08, 2025
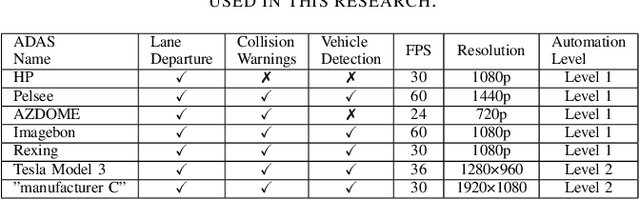

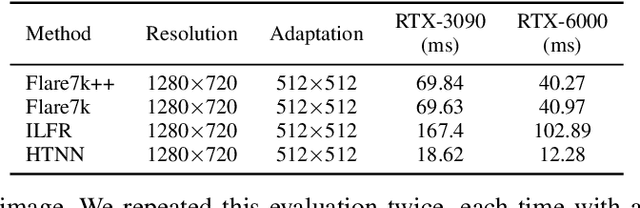
The safety of autonomous cars has come under scrutiny in recent years, especially after 16 documented incidents involving Teslas (with autopilot engaged) crashing into parked emergency vehicles (police cars, ambulances, and firetrucks). While previous studies have revealed that strong light sources often introduce flare artifacts in the captured image, which degrade the image quality, the impact of flare on object detection performance remains unclear. In this research, we unveil PaniCar, a digital phenomenon that causes an object detector's confidence score to fluctuate below detection thresholds when exposed to activated emergency vehicle lighting. This vulnerability poses a significant safety risk, and can cause autonomous vehicles to fail to detect objects near emergency vehicles. In addition, this vulnerability could be exploited by adversaries to compromise the security of advanced driving assistance systems (ADASs). We assess seven commercial ADASs (Tesla Model 3, "manufacturer C", HP, Pelsee, AZDOME, Imagebon, Rexing), four object detectors (YOLO, SSD, RetinaNet, Faster R-CNN), and 14 patterns of emergency vehicle lighting to understand the influence of various technical and environmental factors. We also evaluate four SOTA flare removal methods and show that their performance and latency are insufficient for real-time driving constraints. To mitigate this risk, we propose Caracetamol, a robust framework designed to enhance the resilience of object detectors against the effects of activated emergency vehicle lighting. Our evaluation shows that on YOLOv3 and Faster RCNN, Caracetamol improves the models' average confidence of car detection by 0.20, the lower confidence bound by 0.33, and reduces the fluctuation range by 0.33. In addition, Caracetamol is capable of processing frames at a rate of between 30-50 FPS, enabling real-time ADAS car detection.
Brain Tumor Identification using Improved YOLOv8
Feb 06, 2025



Identifying the extent of brain tumors is a significant challenge in brain cancer treatment. The main difficulty is in the approximate detection of tumor size. Magnetic resonance imaging (MRI) has become a critical diagnostic tool. However, manually detecting the boundaries of brain tumors from MRI scans is a labor-intensive task that requires extensive expertise. Deep learning and computer-aided detection techniques have led to notable advances in machine learning for this purpose. In this paper, we propose a modified You Only Look Once (YOLOv8) model to accurately detect the tumors within the MRI images. The proposed model replaced the Non-Maximum Suppression (NMS) algorithm with a Real-Time Detection Transformer (RT- DETR) in the detection head. NMS filters out redundant or overlapping bounding boxes in the detected tumors, but they are hand-designed and pre-set. RT-DETR removes hand-designed components. The second improvement was made by replacing the normal convolution block with ghost convolution. Ghost Convolution reduces computational and memory costs while maintaining high accuracy and enabling faster inference, making it ideal for resource-constrained environments and real-time applications. The third improvement was made by introducing a vision transformer block in the backbone of YOLOv8 to extract context-aware features. We used a publicly available dataset of brain tumors in the proposed model. The proposed model performed better than the original YOLOv8 model and also performed better than other object detectors (Faster R- CNN, Mask R-CNN, YOLO, YOLOv3, YOLOv4, YOLOv5, SSD, RetinaNet, EfficientDet, and DETR). The proposed model achieved 0.91 mAP (mean Average Precision)@0.5.
Object Detection Approaches to Identifying Hand Images with High Forensic Values
Dec 21, 2024Forensic science plays a crucial role in legal investigations, and the use of advanced technologies, such as object detection based on machine learning methods, can enhance the efficiency and accuracy of forensic analysis. Human hands are unique and can leave distinct patterns, marks, or prints that can be utilized for forensic examinations. This paper compares various machine learning approaches to hand detection and presents the application results of employing the best-performing model to identify images of significant importance in forensic contexts. We fine-tune YOLOv8 and vision transformer-based object detection models on four hand image datasets, including the 11k hands dataset with our own bounding boxes annotated by a semi-automatic approach. Two YOLOv8 variants, i.e., YOLOv8 nano (YOLOv8n) and YOLOv8 extra-large (YOLOv8x), and two vision transformer variants, i.e., DEtection TRansformer (DETR) and Detection Transformers with Assignment (DETA), are employed for the experiments. Experimental results demonstrate that the YOLOv8 models outperform DETR and DETA on all datasets. The experiments also show that YOLOv8 approaches result in superior performance compared with existing hand detection methods, which were based on YOLOv3 and YOLOv4 models. Applications of our fine-tuned YOLOv8 models for identifying hand images (or frames in a video) with high forensic values produce excellent results, significantly reducing the time required by forensic experts. This implies that our approaches can be implemented effectively for real-world applications in forensics or related fields.
Smartphone-based Iris Recognition through High-Quality Visible Spectrum Iris Capture
Dec 17, 2024
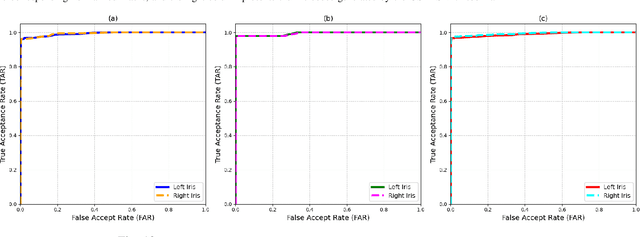
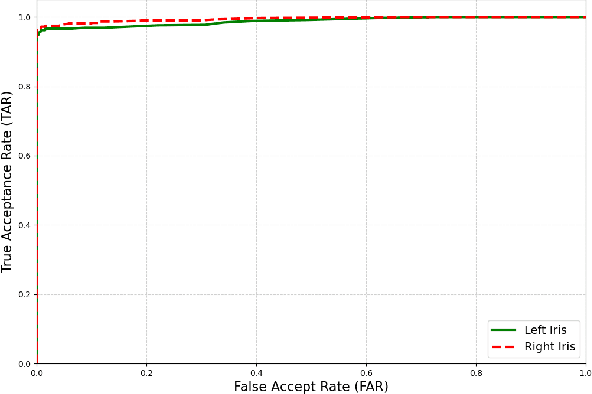
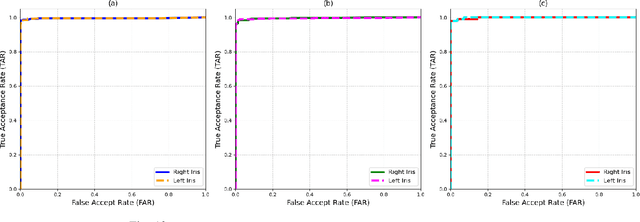
Iris recognition is widely acknowledged for its exceptional accuracy in biometric authentication, traditionally relying on near-infrared (NIR) imaging. Recently, visible spectrum (VIS) imaging via accessible smartphone cameras has been explored for biometric capture. However, a thorough study of iris recognition using smartphone-captured 'High-Quality' VIS images and cross-spectral matching with previously enrolled NIR images has not been conducted. The primary challenge lies in capturing high-quality biometrics, a known limitation of smartphone cameras. This study introduces a novel Android application designed to consistently capture high-quality VIS iris images through automated focus and zoom adjustments. The application integrates a YOLOv3-tiny model for precise eye and iris detection and a lightweight Ghost-Attention U-Net (G-ATTU-Net) for segmentation, while adhering to ISO/IEC 29794-6 standards for image quality. The approach was validated using smartphone-captured VIS and NIR iris images from 47 subjects, achieving a True Acceptance Rate (TAR) of 96.57% for VIS images and 97.95% for NIR images, with consistent performance across various capture distances and iris colors. This robust solution is expected to significantly advance the field of iris biometrics, with important implications for enhancing smartphone security.
Automatic Detection, Positioning and Counting of Grape Bunches Using Robots
Dec 12, 2024



In order to promote agricultural automatic picking and yield estimation technology, this project designs a set of automatic detection, positioning and counting algorithms for grape bunches, and applies it to agricultural robots. The Yolov3 detection network is used to realize the accurate detection of grape bunches, and the local tracking algorithm is added to eliminate relocation. Then it obtains the accurate 3D spatial position of the central points of grape bunches using the depth distance and the spatial restriction method. Finally, the counting of grape bunches is completed. It is verified using the agricultural robot in the simulated vineyard environment. The project code is released at: https://github.com/XuminGaoGithub/Grape_bunches_count_using_robots.
Self-supervised cross-modality learning for uncertainty-aware object detection and recognition in applications which lack pre-labelled training data
Nov 05, 2024
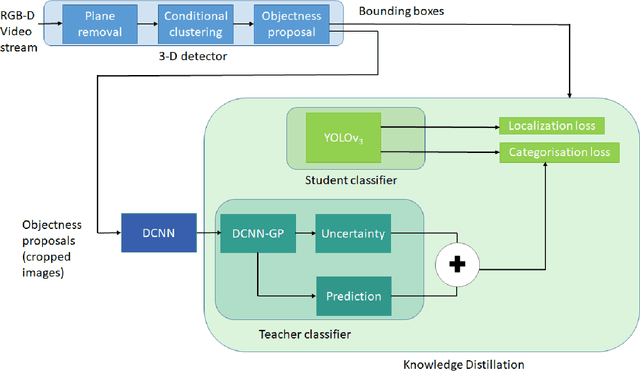
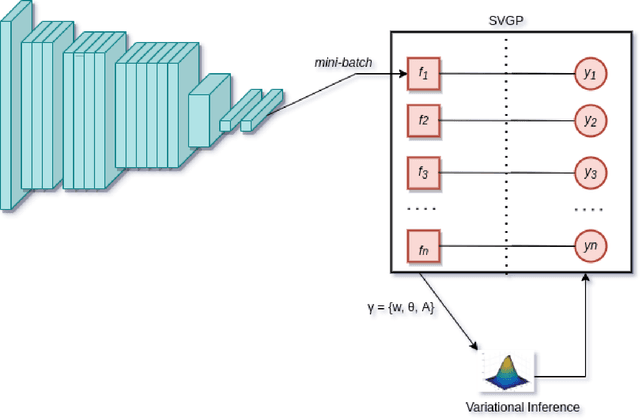
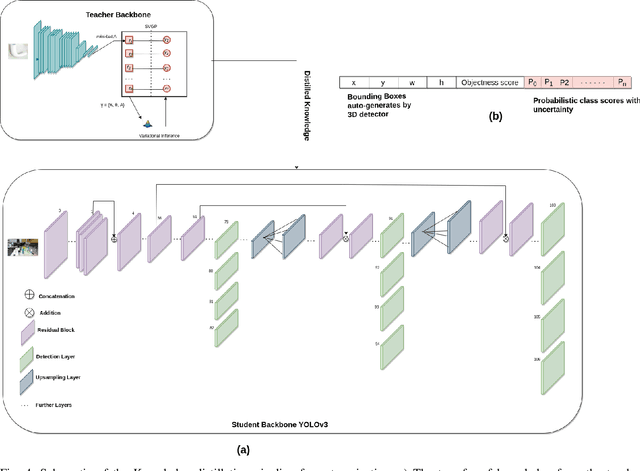
This paper shows how an uncertainty-aware, deep neural network can be trained to detect, recognise and localise objects in 2D RGB images, in applications lacking annotated train-ng datasets. We propose a self-supervising teacher-student pipeline, in which a relatively simple teacher classifier, trained with only a few labelled 2D thumbnails, automatically processes a larger body of unlabelled RGB-D data to teach a student network based on a modified YOLOv3 architecture. Firstly, 3D object detection with back projection is used to automatically extract and teach 2D detection and localisation information to the student network. Secondly, a weakly supervised 2D thumbnail classifier, with minimal training on a small number of hand-labelled images, is used to teach object category recognition. Thirdly, we use a Gaussian Process GP to encode and teach a robust uncertainty estimation functionality, so that the student can output confidence scores with each categorization. The resulting student significantly outperforms the same YOLO architecture trained directly on the same amount of labelled data. Our GP-based approach yields robust and meaningful uncertainty estimations for complex industrial object classifications. The end-to-end network is also capable of real-time processing, needed for robotics applications. Our method can be applied to many important industrial tasks, where labelled datasets are typically unavailable. In this paper, we demonstrate an example of detection, localisation, and object category recognition of nuclear mixed-waste materials in highly cluttered and unstructured scenes. This is critical for robotic sorting and handling of legacy nuclear waste, which poses complex environmental remediation challenges in many nuclearised nations.
ERUP-YOLO: Enhancing Object Detection Robustness for Adverse Weather Condition by Unified Image-Adaptive Processing
Nov 05, 2024



We propose an image-adaptive object detection method for adverse weather conditions such as fog and low-light. Our framework employs differentiable preprocessing filters to perform image enhancement suitable for later-stage object detections. Our framework introduces two differentiable filters: a B\'ezier curve-based pixel-wise (BPW) filter and a kernel-based local (KBL) filter. These filters unify the functions of classical image processing filters and improve performance of object detection. We also propose a domain-agnostic data augmentation strategy using the BPW filter. Our method does not require data-specific customization of the filter combinations, parameter ranges, and data augmentation. We evaluate our proposed approach, called Enhanced Robustness by Unified Image Processing (ERUP)-YOLO, by applying it to the YOLOv3 detector. Experiments on adverse weather datasets demonstrate that our proposed filters match or exceed the expressiveness of conventional methods and our ERUP-YOLO achieved superior performance in a wide range of adverse weather conditions, including fog and low-light conditions.