 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIPI 2024 Challenge on Nighttime Flare Removal: Methods and Results
Apr 30, 2024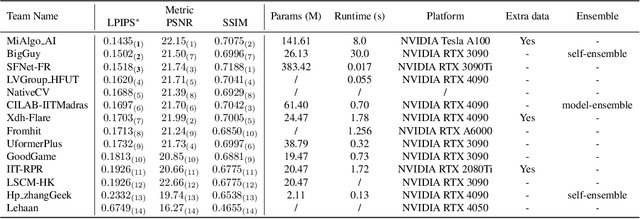
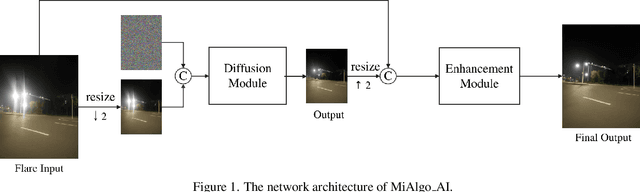
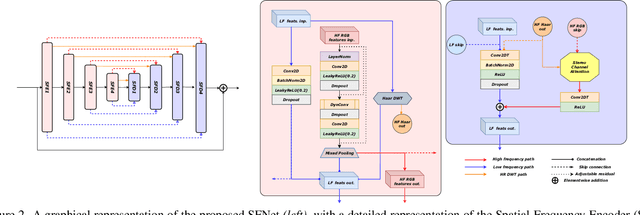
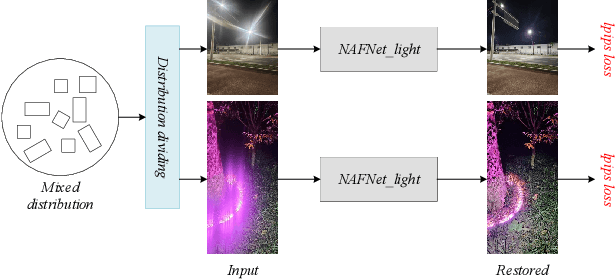
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024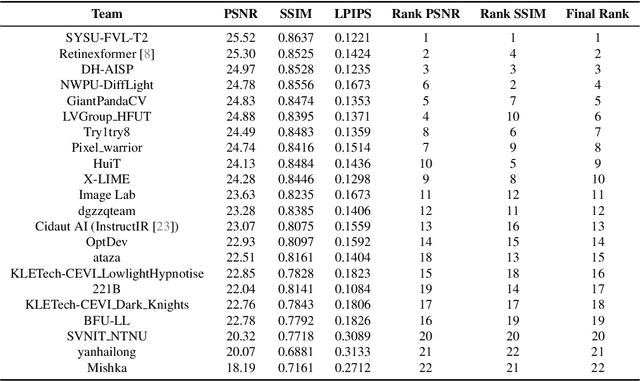


This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Cut-and-Paste: Subject-Driven Video Editing with Attention Control
Nov 20, 2023



This paper presents a novel framework termed Cut-and-Paste for real-word semantic video editing under the guidance of text prompt and additional reference image. While the text-driven video editing has demonstrated remarkable ability to generate highly diverse videos following given text prompts, the fine-grained semantic edits are hard to control by plain textual prompt only in terms of object details and edited region, and cumbersome long text descriptions are usually needed for the task. We therefore investigate subject-driven video editing for more precise control of both edited regions and background preservation, and fine-grained semantic generation. We achieve this goal by introducing an reference image as supplementary input to the text-driven video editing, which avoids racking your brain to come up with a cumbersome text prompt describing the detailed appearance of the object. To limit the editing area, we refer to a method of cross attention control in image editing and successfully extend it to video editing by fusing the attention map of adjacent frames, which strikes a balance between maintaining video background and spatio-temporal consistency. Compared with current methods, the whole process of our method is like ``cut" the source object to be edited and then ``paste" the target object provided by reference image. We demonstrate that our method performs favorably over prior arts for video editing under the guidance of text prompt and extra reference image, as measured by both quantitative and subjective evaluations.