 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fully Automated and Explainable Algorithm for the Prediction of Malignant Transformation in Oral Epithelial Dysplasia
Jul 06, 2023
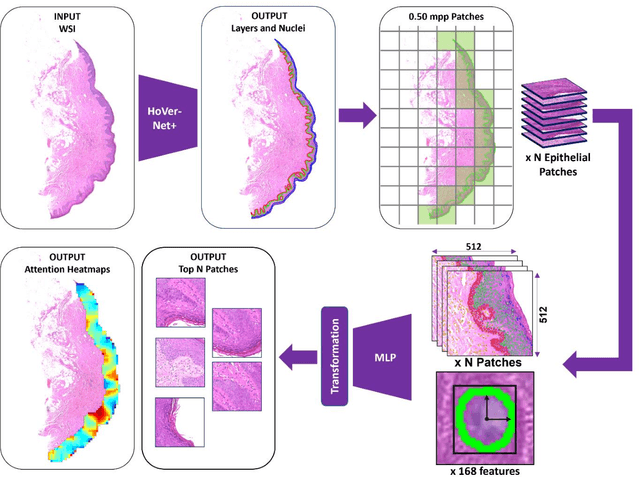
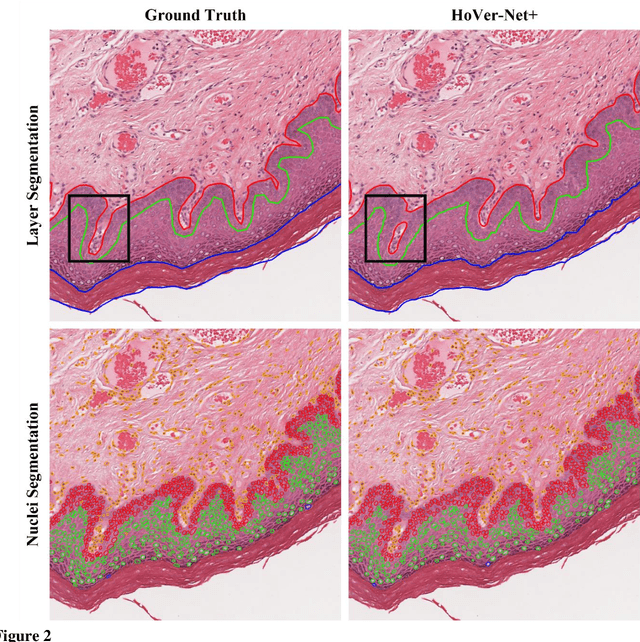

Oral epithelial dysplasia (OED) is a premalignant histopathological diagnosis given to lesions of the oral cavity. Its grading suffers from significant inter-/intra- observer variability, and does not reliably predict malignancy progression, potentially leading to suboptimal treatment decisions. To address this, we developed a novel artificial intelligence algorithm that can assign an Oral Malignant Transformation (OMT) risk score, based on histological patterns in the in Haematoxylin and Eosin stained whole slide images, to quantify the risk of OED progression. The algorithm is based on the detection and segmentation of nuclei within (and around) the epithelium using an in-house segmentation model. We then employed a shallow neural network fed with interpretable morphological/spatial features, emulating histological markers. We conducted internal cross-validation on our development cohort (Sheffield; n = 193 cases) followed by independent validation on two external cohorts (Birmingham and Belfast; n = 92 cases). The proposed OMTscore yields an AUROC = 0.74 in predicting whether an OED progresses to malignancy or not. Survival analyses showed the prognostic value of our OMTscore for predicting malignancy transformation, when compared to the manually-assigned WHO and binary grades. Analysis of the correctly predicted cases elucidated the presence of peri-epithelial and epithelium-infiltrating lymphocytes in the most predictive patches of cases that transformed (p < 0.0001). This is the first study to propose a completely automated algorithm for predicting OED transformation based on interpretable nuclear features, whilst being validated on external datasets. The algorithm shows better-than-human-level performance for prediction of OED malignant transformation and offers a promising solution to the challenges of grading OED in routine clinical practice.
CoNIC Challenge: Pushing the Frontiers of Nuclear Detection, Segmentation, Classification and Counting
Mar 14, 2023



Nuclear detection, segmentation and morphometric profiling are essential in helping us further understand the relationship between histology and patient outcome. To drive innovation in this area, we setup a community-wide challenge using the largest available dataset of its kind to assess nuclear segmentation and cellular composition. Our challenge, named CoNIC, stimulated the development of reproducible algorithms for cellular recognition with real-time result inspection on public leaderboards. We conducted an extensive post-challenge analysis based on the top-performing models using 1,658 whole-slide images of colon tissue. With around 700 million detected nuclei per model, associated features were used for dysplasia grading and survival analysis, where we demonstrated that the challenge's improvement over the previous state-of-the-art led to significant boosts in downstream performance. Our findings also suggest that eosinophils and neutrophils play an important role in the tumour microevironment. We release challenge models and WSI-level results to foster the development of further methods for biomarker discovery.
Mimicking a Pathologist: Dual Attention Model for Scoring of Gigapixel Histology Images
Feb 19, 2023


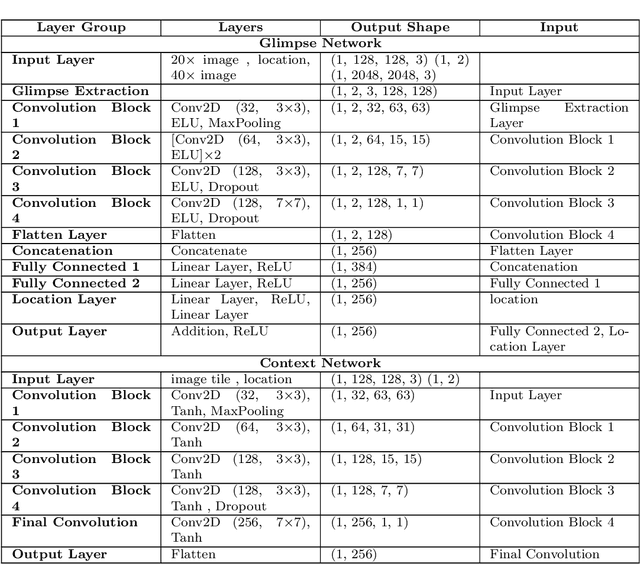
Some major challenges associated with the automated processing of whole slide images (WSIs) includes their sheer size, different magnification levels and high resolution. Utilizing these images directly in AI frameworks is computationally expensive due to memory constraints, while downsampling WSIs incurs information loss and splitting WSIs into tiles and patches results in loss of important contextual information. We propose a novel dual attention approach, consisting of two main components, to mimic visual examination by a pathologist. The first component is a soft attention model which takes as input a high-level view of the WSI to determine various regions of interest. We employ a custom sampling method to extract diverse and spatially distinct image tiles from selected high attention areas. The second component is a hard attention classification model, which further extracts a sequence of multi-resolution glimpses from each tile for classification. Since hard attention is non-differentiable, we train this component using reinforcement learning and predict the location of glimpses without processing all patches of a given tile, thereby aligning with pathologist's way of diagnosis. We train our components both separately and in an end-to-end fashion using a joint loss function to demonstrate the efficacy of our proposed model. We employ our proposed model on two different IHC use cases: HER2 prediction on breast cancer and prediction of Intact/Loss status of two MMR biomarkers, for colorectal cancer. We show that the proposed model achieves accuracy comparable to state-of-the-art methods while only processing a small fraction of the WSI at highest magnification.
Consistency Regularisation in Varying Contexts and Feature Perturbations for Semi-Supervised Semantic Segmentation of Histology Images
Feb 11, 2023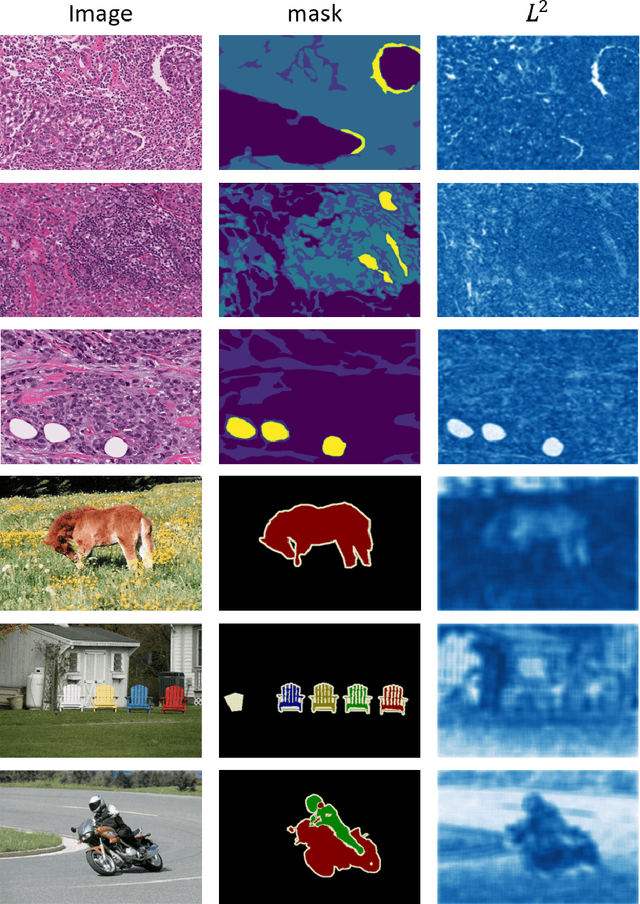
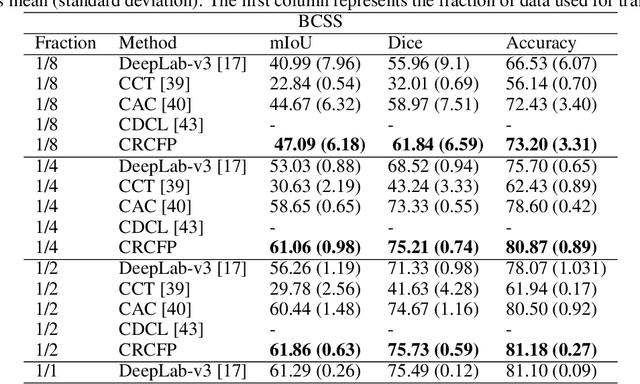
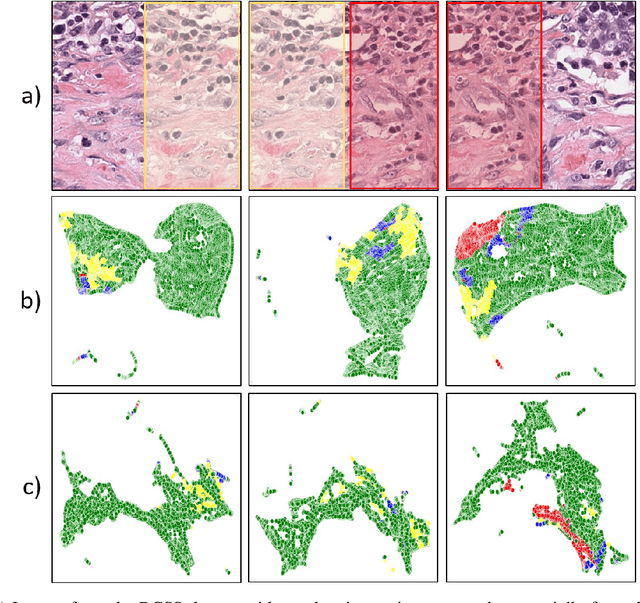
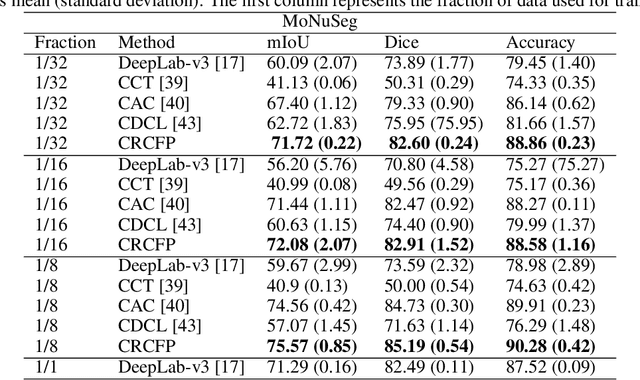
Semantic segmentation of various tissue and nuclei types in histology images is fundamental to many downstream tasks in the area of computational pathology (CPath). In recent years, Deep Learning (DL) methods have been shown to perform well on segmentation tasks but DL methods generally require a large amount of pixel-wise annotated data. Pixel-wise annotation sometimes requires expert's knowledge and time which is laborious and costly to obtain. In this paper, we present a consistency based semi-supervised learning (SSL) approach that can help mitigate this challenge by exploiting a large amount of unlabelled data for model training thus alleviating the need for a large annotated dataset. However, SSL models might also be susceptible to changing context and features perturbations exhibiting poor generalisation due to the limited training data. We propose an SSL method that learns robust features from both labelled and unlabelled images by enforcing consistency against varying contexts and feature perturbations. The proposed method incorporates context-aware consistency by contrasting pairs of overlapping images in a pixel-wise manner from changing contexts resulting in robust and context invariant features. We show that cross-consistency training makes the encoder features invariant to different perturbations and improves the prediction confidence. Finally, entropy minimisation is employed to further boost the confidence of the final prediction maps from unlabelled data. We conduct an extensive set of experiments on two publicly available large datasets (BCSS and MoNuSeg) and show superior performance compared to the state-of-the-art methods.
LYSTO: The Lymphocyte Assessment Hackathon and Benchmark Dataset
Jan 16, 2023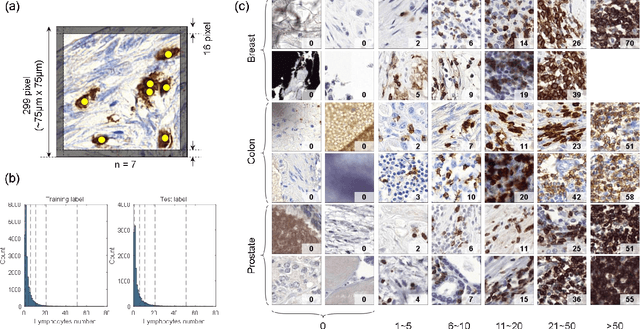
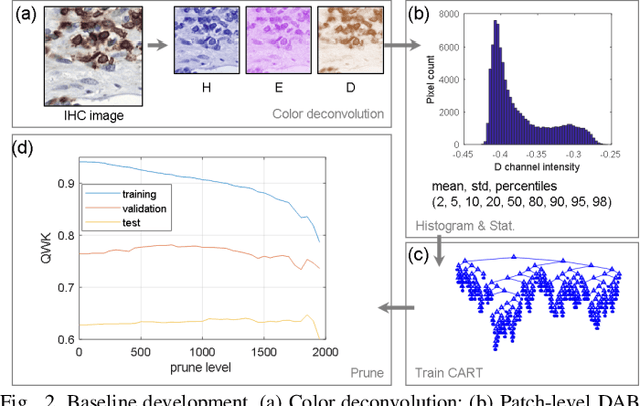
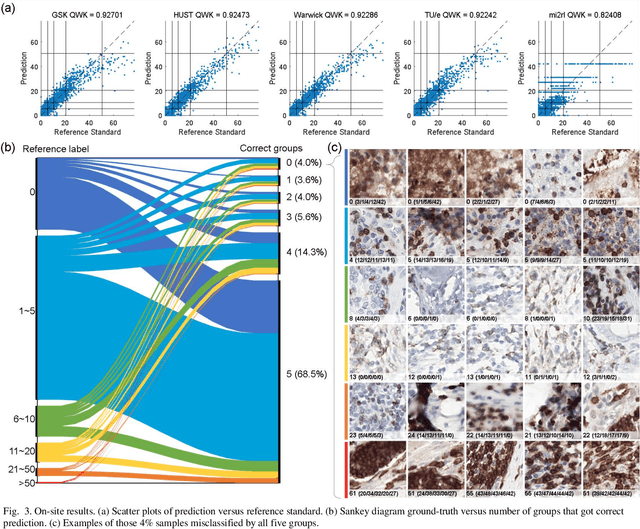
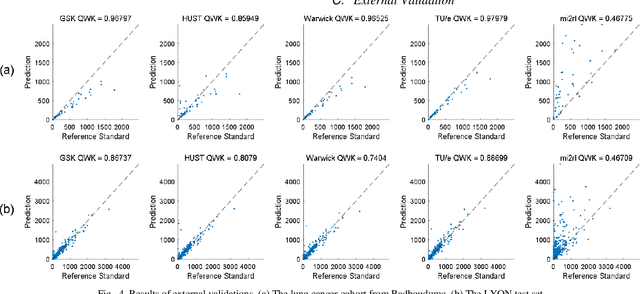
We introduce LYSTO, the Lymphocyte Assessment Hackathon, which was held in conjunction with the MICCAI 2019 Conference in Shenzen (China). The competition required participants to automatically assess the number of lymphocytes, in particular T-cells, in histopathological images of colon, breast, and prostate cancer stained with CD3 and CD8 immunohistochemistry. Differently from other challenges setup in medical image analysis, LYSTO participants were solely given a few hours to address this problem. In this paper, we describe the goal and the multi-phase organization of the hackathon; we describe the proposed methods and the on-site results. Additionally, we present post-competition results where we show how the presented methods perform on an independent set of lung cancer slides, which was not part of the initial competition, as well as a comparison on lymphocyte assessment between presented methods and a panel of pathologists. We show that some of the participants were capable to achieve pathologist-level performance at lymphocyte assessment. After the hackathon, LYSTO was left as a lightweight plug-and-play benchmark dataset on grand-challenge website, together with an automatic evaluation platform. LYSTO has supported a number of research in lymphocyte assessment in oncology. LYSTO will be a long-lasting educational challenge for deep learning and digital pathology, it is available at https://lysto.grand-challenge.org/.
Cellular Segmentation and Composition in Routine Histology Images using Deep Learning
Mar 04, 2022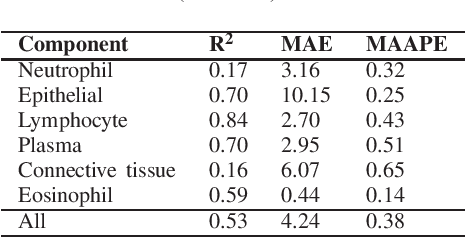
Identification and quantification of nuclei in colorectal cancer haematoxylin \& eosin (H\&E) stained histology images is crucial to prognosis and patient management. In computational pathology these tasks are referred to as nuclear segmentation, classification and composition and are used to extract meaningful interpretable cytological and architectural features for downstream analysis. The CoNIC challenge poses the task of automated nuclei segmentation, classification and composition into six different types of nuclei from the largest publicly known nuclei dataset - Lizard. In this regard, we have developed pipelines for the prediction of nuclei segmentation using HoVer-Net and ALBRT for cellular composition. On testing on the preliminary test set, HoVer-Net achieved a PQ of 0.58, a PQ+ of 0.58 and finally a mPQ+ of 0.35. For the prediction of cellular composition with ALBRT on the preliminary test set, we achieved an overall $R^2$ score of 0.53, consisting of 0.84 for lymphocytes, 0.70 for epithelial cells, 0.70 for plasma and .060 for eosinophils.