 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Approach to Linking Histology Images with DNA Methylation
Apr 07, 2025DNA methylation is an epigenetic mechanism that regulates gene expression by adding methyl groups to DNA. Abnormal methylation patterns can disrupt gene expression and have been linked to cancer development. To quantify DNA methylation, specialized assays are typically used. However, these assays are often costly and have lengthy processing times, which limits their widespread availability in routine clinical practice. In contrast, whole slide images (WSIs) for the majority of cancer patients can be more readily available. As such, given the ready availability of WSIs, there is a compelling need to explore the potential relationship between WSIs and DNA methylation patterns. To address this, we propose an end-to-end graph neural network based weakly supervised learning framework to predict the methylation state of gene groups exhibiting coherent patterns across samples. Using data from three cohorts from The Cancer Genome Atlas (TCGA) - TCGA-LGG (Brain Lower Grade Glioma), TCGA-GBM (Glioblastoma Multiforme) ($n$=729) and TCGA-KIRC (Kidney Renal Clear Cell Carcinoma) ($n$=511) - we demonstrate that the proposed approach achieves significantly higher AUROC scores than the state-of-the-art (SOTA) methods, by more than $20\%$. We conduct gene set enrichment analyses on the gene groups and show that majority of the gene groups are significantly enriched in important hallmarks and pathways. We also generate spatially enriched heatmaps to further investigate links between histological patterns and DNA methylation states. To the best of our knowledge, this is the first study that explores association of spatially resolved histological patterns with gene group methylation states across multiple cancer types using weakly supervised deep learning.
Foundation Models in Computational Pathology: A Review of Challenges, Opportunities, and Impact
Feb 12, 2025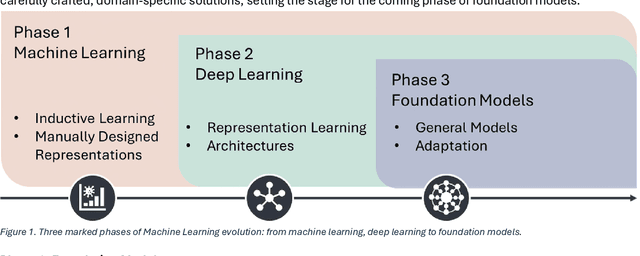
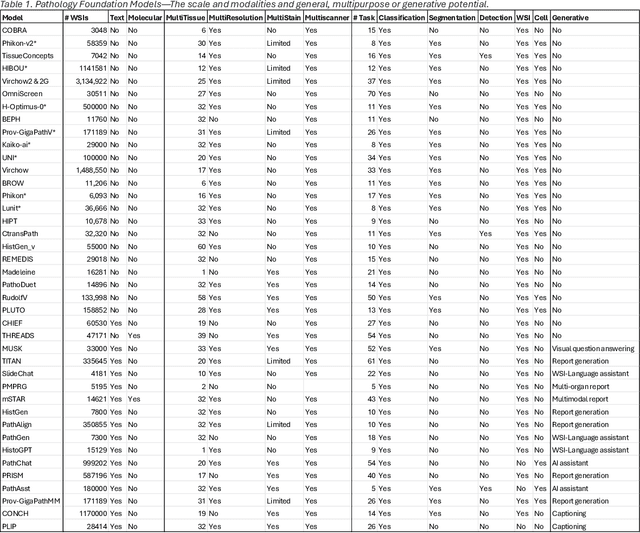
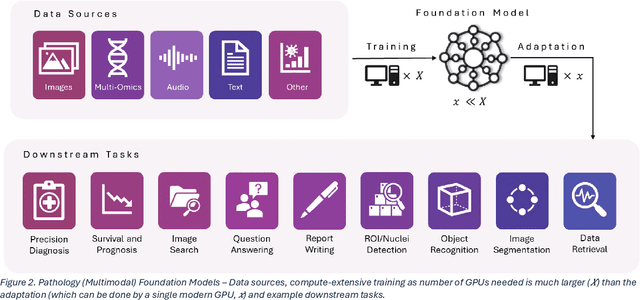
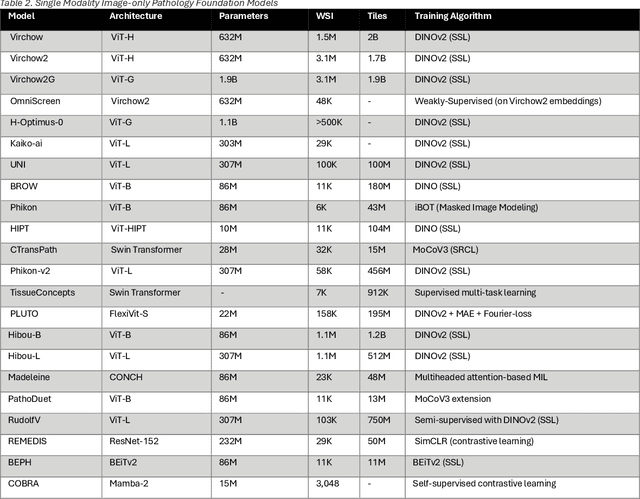
From self-supervised, vision-only models to contrastive visual-language frameworks, computational pathology has rapidly evolved in recent years. Generative AI "co-pilots" now demonstrate the ability to mine subtle, sub-visual tissue cues across the cellular-to-pathology spectrum, generate comprehensive reports, and respond to complex user queries. The scale of data has surged dramatically, growing from tens to millions of multi-gigapixel tissue images, while the number of trainable parameters in these models has risen to several billion. The critical question remains: how will this new wave of generative and multi-purpose AI transform clinical diagnostics? In this article, we explore the true potential of these innovations and their integration into clinical practice. We review the rapid progress of foundation models in pathology, clarify their applications and significance. More precisely, we examine the very definition of foundational models, identifying what makes them foundational, general, or multipurpose, and assess their impact on computational pathology. Additionally, we address the unique challenges associated with their development and evaluation. These models have demonstrated exceptional predictive and generative capabilities, but establishing global benchmarks is crucial to enhancing evaluation standards and fostering their widespread clinical adoption. In computational pathology, the broader impact of frontier AI ultimately depends on widespread adoption and societal acceptance. While direct public exposure is not strictly necessary, it remains a powerful tool for dispelling misconceptions, building trust, and securing regulatory support.
Stain-Invariant Representation for Tissue Classification in Histology Images
Nov 21, 2024
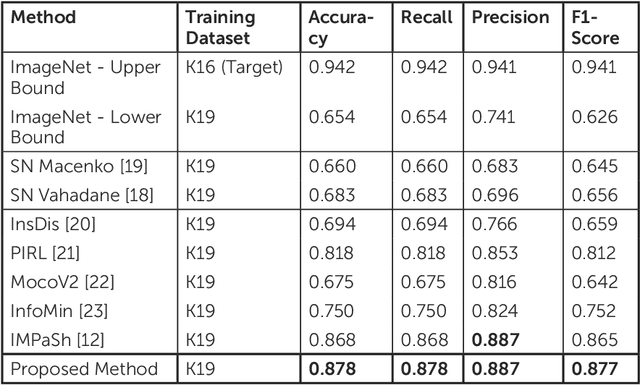
The process of digitising histology slides involves multiple factors that can affect a whole slide image's (WSI) final appearance, including the staining protocol, scanner, and tissue type. This variability constitutes a domain shift and results in significant problems when training and testing deep learning (DL) algorithms in multi-cohort settings. As such, developing robust and generalisable DL models in computational pathology (CPath) remains an open challenge. In this regard, we propose a framework that generates stain-augmented versions of the training images using stain matrix perturbation. Thereafter, we employed a stain regularisation loss to enforce consistency between the feature representations of the source and augmented images. Doing so encourages the model to learn stain-invariant and, consequently, domain-invariant feature representations. We evaluate the performance of the proposed model on cross-domain multi-class tissue type classification of colorectal cancer images and have achieved improved performance compared to other state-of-the-art methods.
Domain Generalization in Computational Pathology: Survey and Guidelines
Oct 30, 2023



Deep learning models have exhibited exceptional effectiveness in Computational Pathology (CPath) by tackling intricate tasks across an array of histology image analysis applications. Nevertheless, the presence of out-of-distribution data (stemming from a multitude of sources such as disparate imaging devices and diverse tissue preparation methods) can cause \emph{domain shift} (DS). DS decreases the generalization of trained models to unseen datasets with slightly different data distributions, prompting the need for innovative \emph{domain generalization} (DG) solutions. Recognizing the potential of DG methods to significantly influence diagnostic and prognostic models in cancer studies and clinical practice, we present this survey along with guidelines on achieving DG in CPath. We rigorously define various DS types, systematically review and categorize existing DG approaches and resources in CPath, and provide insights into their advantages, limitations, and applicability. We also conduct thorough benchmarking experiments with 28 cutting-edge DG algorithms to address a complex DG problem. Our findings suggest that careful experiment design and CPath-specific Stain Augmentation technique can be very effective. However, there is no one-size-fits-all solution for DG in CPath. Therefore, we establish clear guidelines for detecting and managing DS depending on different scenarios. While most of the concepts, guidelines, and recommendations are given for applications in CPath, we believe that they are applicable to most medical image analysis tasks as well.
Mimicking a Pathologist: Dual Attention Model for Scoring of Gigapixel Histology Images
Feb 19, 2023


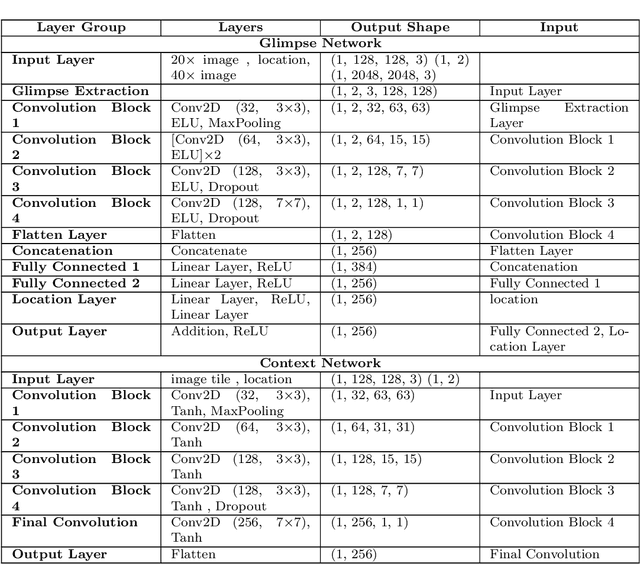
Some major challenges associated with the automated processing of whole slide images (WSIs) includes their sheer size, different magnification levels and high resolution. Utilizing these images directly in AI frameworks is computationally expensive due to memory constraints, while downsampling WSIs incurs information loss and splitting WSIs into tiles and patches results in loss of important contextual information. We propose a novel dual attention approach, consisting of two main components, to mimic visual examination by a pathologist. The first component is a soft attention model which takes as input a high-level view of the WSI to determine various regions of interest. We employ a custom sampling method to extract diverse and spatially distinct image tiles from selected high attention areas. The second component is a hard attention classification model, which further extracts a sequence of multi-resolution glimpses from each tile for classification. Since hard attention is non-differentiable, we train this component using reinforcement learning and predict the location of glimpses without processing all patches of a given tile, thereby aligning with pathologist's way of diagnosis. We train our components both separately and in an end-to-end fashion using a joint loss function to demonstrate the efficacy of our proposed model. We employ our proposed model on two different IHC use cases: HER2 prediction on breast cancer and prediction of Intact/Loss status of two MMR biomarkers, for colorectal cancer. We show that the proposed model achieves accuracy comparable to state-of-the-art methods while only processing a small fraction of the WSI at highest magnification.
Cellular Segmentation and Composition in Routine Histology Images using Deep Learning
Mar 04, 2022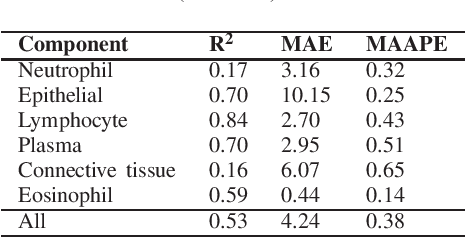
Identification and quantification of nuclei in colorectal cancer haematoxylin \& eosin (H\&E) stained histology images is crucial to prognosis and patient management. In computational pathology these tasks are referred to as nuclear segmentation, classification and composition and are used to extract meaningful interpretable cytological and architectural features for downstream analysis. The CoNIC challenge poses the task of automated nuclei segmentation, classification and composition into six different types of nuclei from the largest publicly known nuclei dataset - Lizard. In this regard, we have developed pipelines for the prediction of nuclei segmentation using HoVer-Net and ALBRT for cellular composition. On testing on the preliminary test set, HoVer-Net achieved a PQ of 0.58, a PQ+ of 0.58 and finally a mPQ+ of 0.35. For the prediction of cellular composition with ALBRT on the preliminary test set, we achieved an overall $R^2$ score of 0.53, consisting of 0.84 for lymphocytes, 0.70 for epithelial cells, 0.70 for plasma and .060 for eosinophils.